
此前,该站完好无损,经过我一阵瞎折腾,以及外来因素的干扰,最终崩盘,以至于重新建站,更换了一个更轻量级的主题,关于建站的教程,网上屡屡皆是,在此我不在赘述,仅仅简单记录一下该站出问题的时候进行的问题排查。
问题排查
起初网站第一天登陆不上,我没有太多的在意,直到第二天上班的凌晨还登不上,我逐渐意识到事情的不对,让朋友帮忙访问了一下,却返回正常的结果(记一下她是电信流量卡,等会要考),我以为是我自己的设备问题,但是换了两张卡的流量都登不上去,又让我朋友也登了一下也是同样的问题。于是我便排除流量问题的可能,误以为第一个朋友能成功访问是因为浏览器的缓存暂时未清除。
于是我用阿里云拔测工具,测出来是611,于是我想用宝塔面板服务也登不上,也是611,ping了一下,发现DNS能够正常解析域名。故排除DNS的故障。
重装服务器、nginx、bt
然后用workbench远程连接服务器,心想着网站的内部的问题,懒得排查,干脆直接一键删库,反正我也打算重新整理下这个网站,于是便一键删除了整个库。然后格式化了服务器云盘,重装了服务器系统。最后重装NGINX服务和BT服务
注意:安装nginx的注意下网站的配置文件,改一下其中的server服务的对应站点内容,详情可以参考下面这篇文。
从零开始部署到上线:手把手教你搭建属于自己的个人博客网站!-阿里云开发者社区 (aliyun.com)
然后记得加上443和80的http服务端口,并到服务器的安全组里面去开放
Nginx网站服务配置,图文详解(超详细)_nginx 配置网页-CSDN博客
详请的HTTP配置,我直接放在下面:
http {
##文件扩展名与文件类型映射表
include mime.types;
##默认文件类型
default_type application/octet-stream;
##日志格式设定
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
##访问日志位置
#access_log logs/access.log main;
##支持文件发送(下载)
sendfile on;
##此选项允许或禁止使用socke的TCP_CORK的选项(发送数据包前先缓存数据),此选项仅在使用sendfile的时候使用
#tcp_nopush on;
##连接保持超时时间,单位是秒
#keepalive_timeout 0;
keepalive_timeout 65;
##gzip模块设置,设置是否开启gzip压缩输出
#gzip on;
##Web 服务的监听配置
server {
##监听地址及端口
listen 80;
##站点域名,可以有多个,用空格隔开
server_name www.lic.com;
##网页的默认字符集
charset utf-8;
##根目录配置
location / {
##网站根目录的位置/usr/local/nginx/html
root html;
##默认首页文件名
index index.html index.htm;
}
##内部错误的反馈页面
error_page 500 502 503 504 /50x.html;
##错误页面配置
location = /50x.html {
root html;
}
}
}SSL证书更新
做完上面的配置,然后记得更新一下SSL证书,具体步骤如下
打开 Nginx 配置文件 nginx.conf,找到包含 /path/to/your/certificate.pem 的行,并将其更改为您的实际 SSL 证书路径。如果您没有 SSL 证书,或者不需要 SSL,那么可以注释掉相关的 SSL 配置行。
使用以下命令编辑配置文件(这里使用 vi 编辑器,您也可以使用其他编辑器,如 nano):
vi /usr/local/nginx/conf/nginx.conf找到类似下面的行,并将其更改为正确的路径或注释掉:
# ssl_certificate /path/to/your/certificate.pem;
# ssl_certificate_key /path/to/your/private.key;更新配置文件后,重新测试配置文件是否正确:
/usr/local/nginx/sbin/nginx -t重启Nginx
完成上述过程后,我重新启动了nginx
/usr/local/nginx/sbin/nginx结果弹出了错误提示:“Failed to execute operation: Invalid argument” 表明我尝试执行的命令使用了不正确的参数,或者服务管理器 systemctl 无法找到指定的服务。
这意味着几种情况:
- 我的nginx服务单元不存在/不在正确位置
- nginx服务单元文件已经存在
利用命令检查后,发现我的nginx服务单元文件不存在,于是我便创建了一个新的:
#检查命令
ls /etc/systemd/system/nginx.service
ls /usr/lib/systemd/system/nginx.service#重建nginx服务单元
[root@XiaoYang ~]# cat <<EOF >/etc/systemd/system/nginx.service
[Unit]
Description=The NGINX HTTP and reverse proxy server
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStartPre=/usr/local/nginx/sbin/nginx -t
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
##请确保 PIDFile 和 ExecStart 等路径与您的 Nginx 安装路径匹配。接下来只需要重启即可
重新加载 `systemd` 管理器:systemctl daemon-reload
启用并启动 Nginx 服务:
systemctl enable nginx
systemctl start nginx
确保 Nginx 在系统启动时自动启动:systemctl enable nginx
检查 Nginx 服务状态:systemctl status nginx
查看 Nginx 日志:
tail -f /usr/local/nginx/logs/access.log
tail -f /usr/local/nginx/logs/error.log开放80、443端口并监听
做好上面的后,我去重新在阿里云安全组添加了80、443端口,然后服务器中然后用netstat命令检查端口80和443是否正常运行,看是否有被占用。
若被占用,则使用kill命令杀死占用进程,然后重新运行nginx服务即可
再次排查
此时我再次进行ping,发现服务器站点能够ping通,响应200,此时我便下意识觉得肯定是服务器内部的问题,然后着手下一步网站的重建,结果在登陆宝塔面板的时候,意外还是来了,仍然登陆不了bt面板,去服务器内部检测,发现bt面板服务是正常开启的
于是我便去阿里云提交了工单,结果吃我一惊,对方工程师让我用tracert进行网络跳转测试,并反馈相应截图,我测试了一下,route在进行到第10的时候进行断线了,然后我用微步在线溯源了一下,发现是中国移动运行商的ip,接着就出现了下面这一幕。
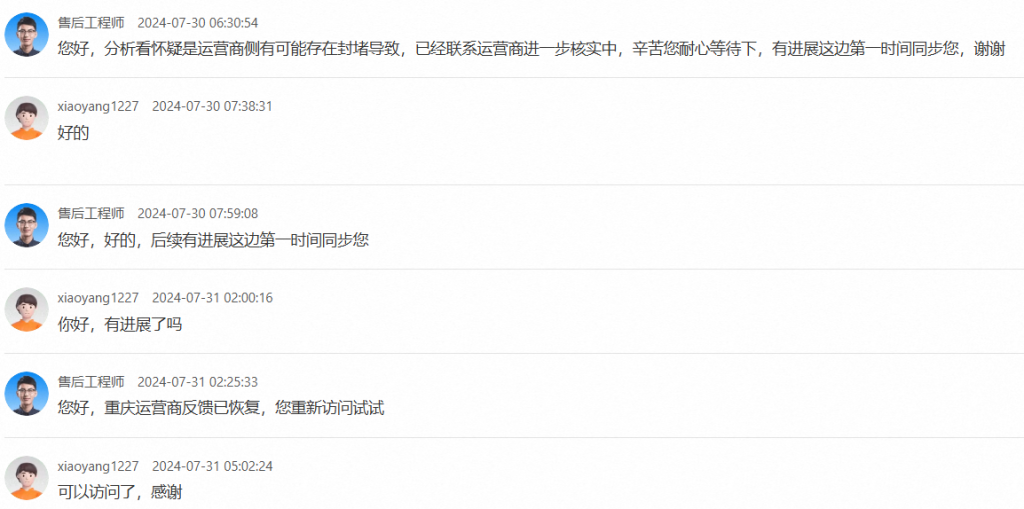
这个结果结果让我很纳闷,回想一下发现朋友的卡跟我不是同一个运营商,怪不得他能正常访问,网络拨测的时候返回结果611的也全是移动运营商。但是我也没有在hvv期间使用云计算进行攻击啊,跟何况我是防守方啊。结果第二天去值班的时候,发现群记录:
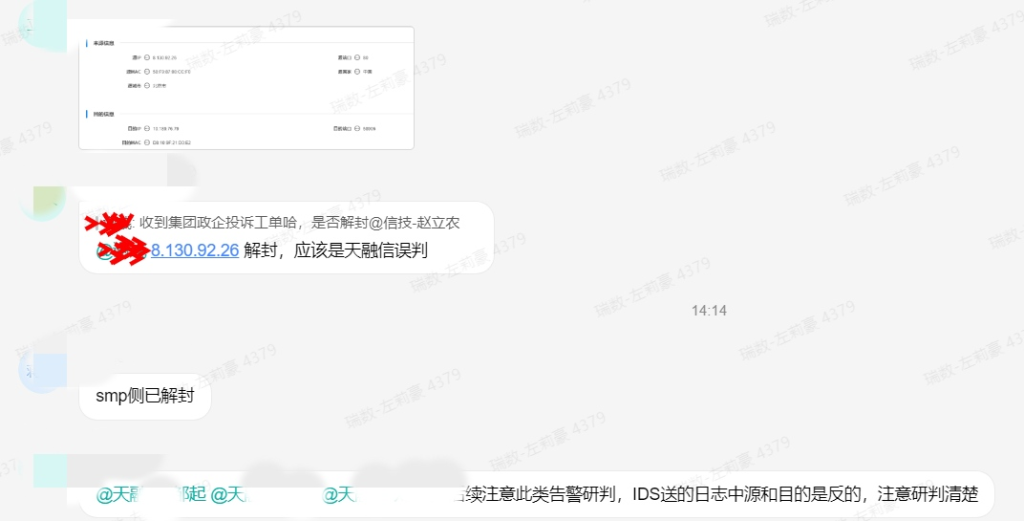
我一看,这不就是我的服务器ip吗,搞半天原来是护网同事误封了,辛亏我即使联系了阿里云客服,接着第三天早会就强调了有关云服务器的上报封堵,提醒我们一定要做好研判再进行上报封堵。
总结
总的来说,算是一个乌龙,要是当时在工作群里问一下,估计就没那么多事了,但也算给我收获了很多宝贵的经验。
遇到类似情况,应对手段:查DNS,网络拔测看响应码、远程连接服务器查对应服务是否正常运行,tracert route侦察是否存在ip封堵、安全组排查端口是否正常开始等等。。。



miaomiao