
懒人一键:
01.基础概念
- 域名:IP地址不便于记忆,故采用域名系统和DNS与ip地址映射。
- DNS:分布式网络目录服务,主要用于域名和ip地址的转换
- 本地HOSTS文件:优先解析ip的地址的一种菜单,如某些加速软件的原理
- CDN:缓存节点技术,工作原理:什么是CDN?它解决了什么难题?5分钟让你明明白白!-腾讯云开发者社区-腾讯云 (tencent.com)
- 后门:指绕过安全控制而获取对程序或系统访问权的方法,免杀
- web组成架构:源码(java、php)、操作系统、中间搭建平台(nginx、apache)、数据库
小tips:一个站点,在其D盘下存在”wwwroot/www.zip”的文件,用域名访问进行爆破”/www.zip” 可能不能下载,但是用ip地址爆破”/www.zip”,就可以下载,原因在于,用域名访问的是固定的目录,但用ip访问就是访问的网站根目录,就可以下载。
02.数据包拓展
浏览器与服务器代理
正常情况下:浏览器发送 Request请求数据包 到放服务器,服务器 返回 Response响应包
代理情况下:在服务器与客户传输数据时,先进行截获,再发送。
HTTPS与HTTP
HTTP 与 HTTPS 的区别 | 菜鸟教程 (runoob.com)
http:HTTP->TCP->IP
https:HTTP-> SSL/TLS->TCP->IP (有证书或者加密协议)
两者区别:
1. HTTP 明文传输,数据未加密,安全性差,HTTPS(SSL+HTTP) 数据传输加密,安全性好。
2. 使用 HTTPS 协议需要到 CA(数字证书认证机构) 申请证书。
3. HTTP 页面响应速度比 HTTPS 快,因为 HTTP 使用 TCP 三次握手进行连接建立 ,客户端、服务器需要交换 3个包,而 HTTPS 除了 TCP 的三个包,还要加上 SSL 握手需要的 9 个包,所以一共是 12 个包。
4. HTTP 和 HTTPS 使用的是不同的连接方式,端口也不一样,前者80,后者443。
5. HTTPS 就是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比较 HTTPS 更耗费服务器资源。数据包
HTTP工作流程:建立连接->发送请求数据包->发送响应数据包->关闭连接
Request请求数据包格式
1.请求行:请求类型/请求资源路径、协议版本和类型
2.请求头:一些键值对,浏览器与web服务器之间都可以发送,特定的某种意义
3.空行:请求头与请求体之间用一个空行隔开
4.请求体:要发送的数据(一般会post提交会使用)例:user=123&pass=123
请求行:请求类型/请求资源路径、协议的版本和类型
由三个标记组成:请求方法、请求URL和HTTP版本,它们用空格分开。
例如: GET / index.html HTTP/x.x
HTTP 规划定义了8种可能的请求方法:
GET:检索URL中标识资源的一个简单请求
HEAD:与GET方法相同,服务器只返回状态行和头标,并不返回请求文档
POST:服务器接收被写入客户端输出流中数据的请求
PUT:服务器保存请求数据作为指定URL新内容的请求
DELETE:服务器删除URL中命令的资源的请求
OPTIONS:关于服务器支持的请求方法信息的请求
TRACE:web服务器反馈HTTP请求和其头标的请求
CONNECT:已文档化,但当前未实现的一个方法,预留做隧道处理
请求头:由关键字/值对组成,每行一对,关键字和值用冒号分享
HOST:主机或域名地址
Accept:指浏览器或其他客户可以接受的MIME文件格式,servlet可以根据它判断并返回适当的文件格式
User-Agent:是客户浏览器名称
Host:对应网址URL中的web名称和端口号
Accept-Language:指出浏览器可以接受的语言种类,如en或者en-us,指英语
connection:用来告诉服务器是否可以维持固定的HTTP连接、http是无连接的,HTTP/1.1使用Keep-Alive为默认值,这样当浏览器需要多个文件时(如一个HTML文件和相关的图形文件),不需要每次都建立连接
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,他可以记载服务器相关的用户信息,也可以用来实现会话功能
Referer:表明产生请求的网页URL,这个属性可以用来跟踪web请求是从什么网站来的。如比从网页/icconcept/index.jsp中点击一个链接到网页/icwork/search,再向服务器发送的GET/icwork/search中的请求中,Referer是http://hostname:8080/icconcept/index.jsp
Content-Type:用来表明request的内容类型,可以用HttpServeletRequest的getContentType()方法取得。
Accept-Charset:指出浏览器可以接受的字符编码
Accept-Encoding:指出浏览器可以接受的编码方式。编码方式不同于文件格式,它是为了压缩文件传递速度。浏览器在接收到web响应之后再解码,然后再检查文件格式
空行:请求头与请求体之间用一个空行隔开
最后一个请求头标之后是空行,发送回车符和退行,通知服务器以下不再有头标。
请求体:发送的数据(一般post提交会使用)
使用POST传送,最常使用的是Content-Type和Content-Length头标Response返回数据包
一个响应包由4部分组成:状态行+响应头标+空行+响应数据(与请求包有点类似)
1.状态行:协议版本、数字形式的状态代码和状态描述,各元素之间以空格分隔
2.响应头标:包含服务器类型、日期、长度、内容类型等
3.空行:响应头与响应体之间用空行隔开
4.响应数据:浏览器会将实体内容中额数据取出来,生成相应的页面
HTTP响应码(status)
1xx:信息,请求收到,继续处理
2xx:成功,行为被成功的接收、理解和采纳
3xx:重定向,为了完成请求,必须进一步执行的动作
4xx:客户端错误
5xx:服务器错误
200:存在文件
403:存在文件夹
3xx:均可能存在
404:不存在文件及文件夹
500:均可能存在
响应头标:包含服务器类型、日期、长度、内容类型等
像请求头标一样,它们指出服务器的功能,标识出响应数据的细节
空行:响应头与响应体之间用空行隔开
最后一个响应头标之后是一个空行,发送回车符和退行,表面服务器以下不再有头标。
响应数据:浏览器会将实体内容中的数据取出来,生成相应的页面
HTML文档和图像等,也就是HTML本身。
Server:服务端所使用的Web服务名称,如:Server:Apache/1.3.6(Unix)。
Set-Cookie:服务器向客户端设置的Cookie。
Last-Modified,服务器通过这个域告诉客户端浏览器,资源的最后修改时间。
Location:重定向用户到另一个页面,比如身份认证通过之后就会转向另一个页面。这个域通常配合302状态码使用。
Content-Length:body部分的长度(单位字节)。03.搭建安全(中间件)扩展
- 常见搭建平台脚本启用:ASP,PHP,ASPX,JSP,PY,JAVAWEB等环境
- 域名IP目录解析安全问题:IP地址可以访问发现更多内容,而域名访问只能发现一个文件夹下的所有文件。IP地址访问可以发现程序源码备份文件和敏感信息。访问网站的时候,可以访问域名,也可以访问IP地址。访问域名一般会指向某个目录,而访问IP地址一般会指向根目录;
- 常见文件后缀解析对应安全:指定后缀名对应某个文件,访问网站出现遇到不能解析的文件就是中间件可能默认或者添加某些设置导致解析时出现问题
- 思路:抓取网站的搭建平台信息–>查看对应版本是否存在中间漏洞–>漏洞利用
中间件常见漏洞信息:见工具集
练习:ubuntu搭建vulhub靶场,自行练习
04.WEB源码拓展
前言: WEB源码在安全测试中是非常重要的信息来源,可以用来代码审计漏洞也可以用来做信息突破口。如:获取某ASP源码后可以采用默认数据库下载为突破,获取某其他脚本源码漏洞可以进行代码审计挖掘或分析其业务逻辑等
拿到源码,从下面角度出发:
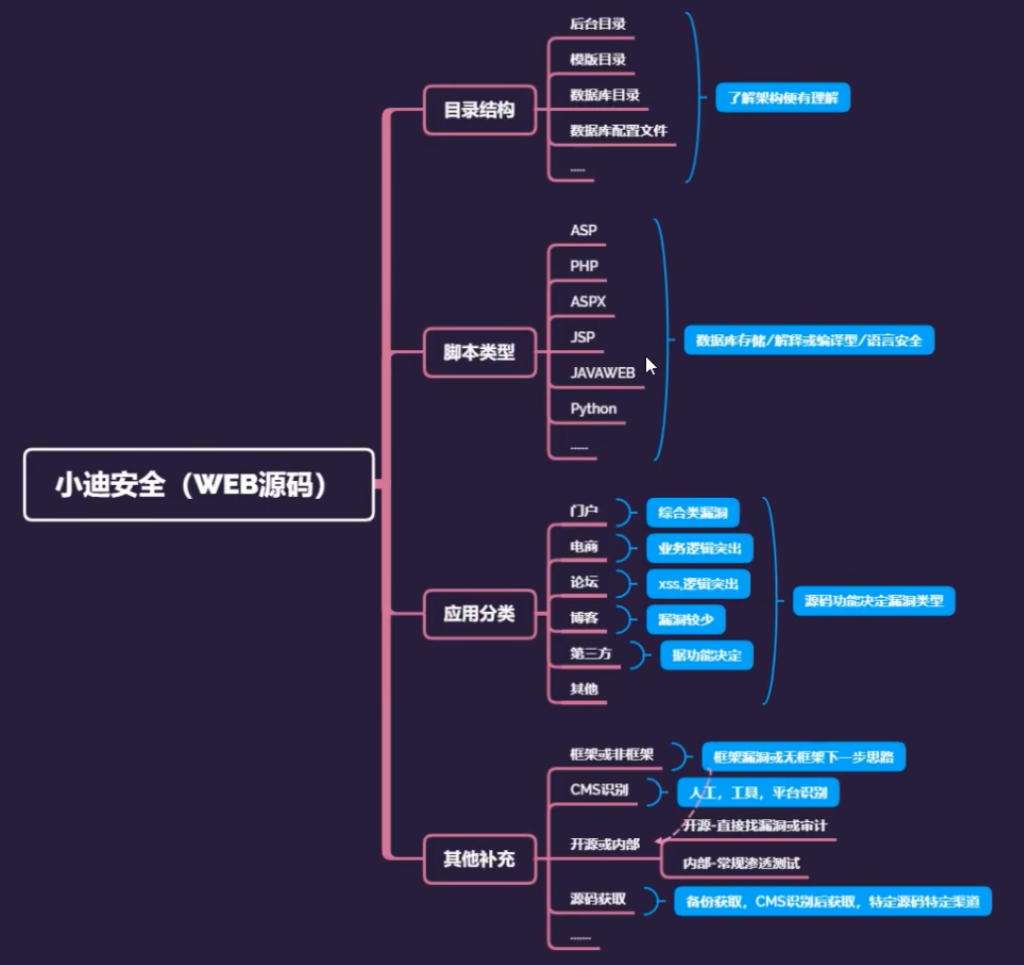
常见CMS:WordPress、halo、ghost
#数据库配置文件,后台目录,模版目录,数据库目录等
#ASP,PHP,ASPX,JSP,JAVAWEB等脚本类型源码安全问题
#社交,论坛,门户,第三方,博客等不同的代码机制对应漏洞
#开源,未开源问题,框架非框架问题,关于CMS识别问题及后续等
#关于源码获取的相关途径:搜索,咸鱼淘宝,第三方源码站,各种行业对应
#总结:
关注应用分类及脚本类型估摸出可能存在的漏洞(其中框架类例外),在获取源码后可进行本地安全测试或代码审计,也可以分析其目录工作原理(数据库备份,bak文件等),未获取到的源码采用各种方法想办法获取!关于WEB源码目录结构
- 网站的脚本类型
- 网站的管理后台目录
- 网站的数据目录—包含数据库配置文件等
- 其他—template模板目录、member会员相关文件
关于WEB源码脚本类型源码安全问题
关于WEB源码应用分类
社交,论坛,门户,第三方,博客等不同的应用,对应的漏洞也不尽相同,可以根据业务不同,重点关注相关漏洞,放弃无关漏洞,节约时间
关于WEB源码其他说明
- 框架开发—直接找脚本语言框架的漏洞
- 非框架开发—找代码的漏洞
- CMS识别(网上开源代码)—如何判断是用什么程序搭建的(人工和工具,工具就是扫描某CMS特有程序文件来判断)—网上公开漏洞
- 开源—能识别并且在网上下载(白盒)
- 内部—没有源码或不知道—常规的渗透测试(黑盒)
- 源码获取—扫描工具扫描备份文件—cms获取源码—特定渠道(灰色网站源码)
- 源码获取的相关途径,包括 搜索引擎搜索,闲鱼淘宝,第三方源码站(菜鸟源码),各种行业对应(源码之家,站长下载)。
05.系统及数据库拓展
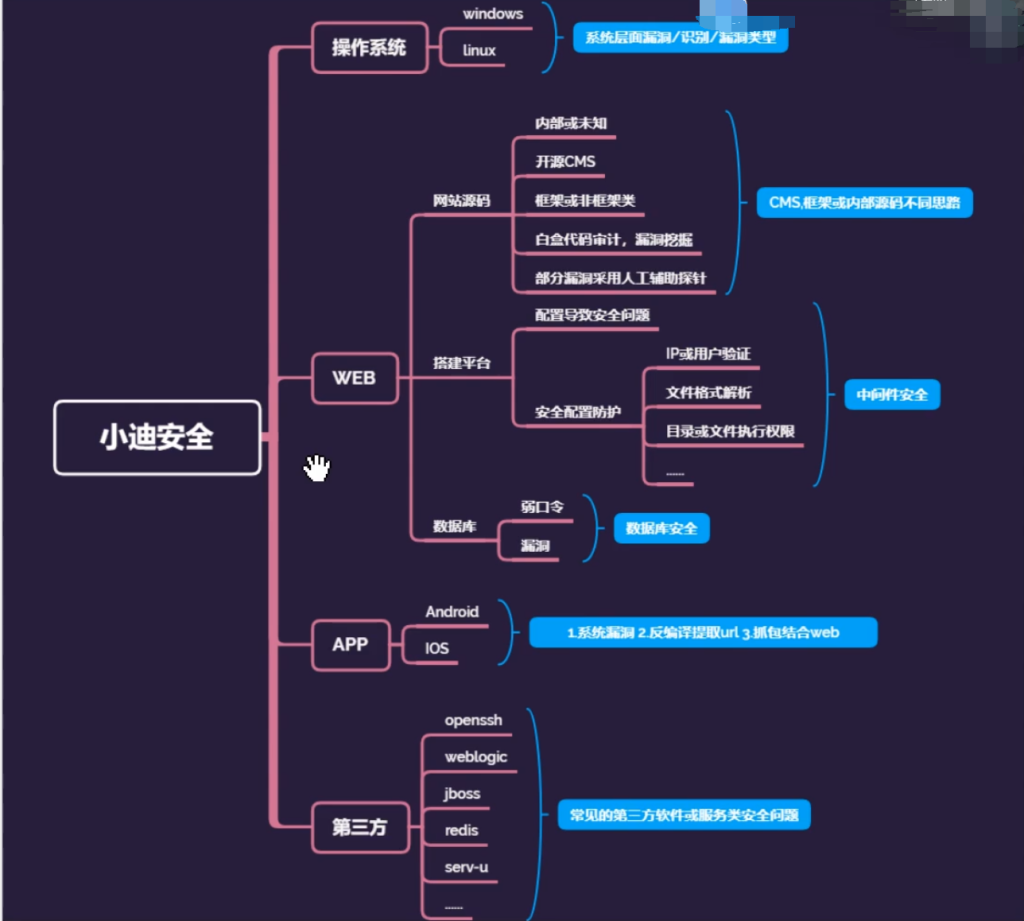
操作系统层面
1、识别操作系统常见方法:
---有网站的:通过网站的手工识别方法判断:Windows对网址大小写不敏感,Linux对大小写敏感。可以在网页中替换网站路径的大小写进行测试。
---没有网站的:通过nmap命令进行扫描:nmap -O IP 地址 ,或者工具masnmapscan(速度十分快)。
通过PING命令返回的TTL来判断目标主机的操作系统类型。不同的操作系统的默认TTL值是不同的(判断依据)采用近似比对。但是当用户修改了TTL值的时候,就会误导我们的判断,所以不一定准确。
下面是默认操作系统的TTL:
WINDOWS NT/2000 TTL:128
WINDOWS 95/98 TTL:32
UNIX TTL:255
LINUX TTL:64
WIN7 TTL:64
2、两者区别及识别意义
windows和linux的目录结构不一样;
windows和linux对大小写的敏感程度不一样;
windows和linux的漏洞不一样,可能windows的漏洞在Linux上就不能运用。
3、操作系统层面漏洞类型对应意义
不同漏洞会造成不同漏洞利用条件,有些漏洞在实践中需要额外的前提条件、很难利用,可以直接放弃。
4、简要操作系统层面漏洞影响范围
有些漏洞会对操作系统造成崩溃、而有些系统只是蓝屏、或者是权限的提升。
我们特别需要学习的漏洞是一些造成权限丢失的漏洞,因为可以帮助我们提权,比如ms17010就是一个高危漏洞,它跟权限挂钩,而且不需要一些额外的苛刻条件,只要是windows操作系统,没有打补丁,并且使用了smb,开放了445端口,就可能被利用。数据据库层面
不同数据库漏洞类型、攻击方式都不同,每种脚本语言都有对应的推荐的数据库,因为使用推荐数据库兼容性会比较好。
默认的语言搭配的数据库:
1.组合类型asp + access/mssql
2.组合类型php + mysql
3.组合类型aspx+mssql
4.组合类型jsp +mysql/oracle
5.组合类型Python + MongoDB
常见的数据库默认端口号:
一、关系型数据库
1、MySql数据库 ,默认端口是: 3306;
2、Oracle数据库 ,默认端口号为:1521;
3、Sql Server数据库 ,默认端口号为:1433;
4、DB2数据库, 默认端口号为:5000;
5、PostgreSQL数据库, 默认端口号为:5432;
6、国产的DM达梦数据库, 默认端口号为:5236。
二、NoSql数据库(非关系型数据库):
1.Redis数据库,默认端口号:6379;
2.Memcached数据库,默认端口号:11211 ;
3.MongoDB数据库,默认端口号:27017;
通过nmap -o ip 命令的返回情况进行判断端口开放情况
常见数据库漏洞:弱口令、数据库漏洞
影响范围:数据库权限、网站权限(登录后台)、修改网页内容第三方层面
不同的第三方软件或工具存在不同的漏洞、识别到更多的信息对收集到的漏洞也就越多
如何判断有那些第三方平台或软件:通过端口扫描:nmap -O -sV IP地址
常见第三方平台或软件漏洞类型及攻击:弱口令、软件漏洞
第三方平台或软件安全测试的范围:直接获取到软件的权限便于进一步的提权和攻击
补充:除去常规WEB安全及APP安全测试外,类似服务器单一或复杂的其他服务(邮件,游戏,负载均衡等),也可以作为安全测试目标,此类目标测试原则只是少了WEB应用或其他安全问题。
06.加密算法
#常见加密编码等算法解析
MD5,SHA,ASC,进制,时间戳,URL,BASE64,Unescape,AES,DES等
#常见加密形式算法解析
直接加密,带salt,带密码,带偏移,带位数,带模式,带干扰,自定义组合等
#常见解密方式(针对)
枚举,自定义逆向算法,可逆向
#了解常规加密算法的特性
长度位数,字符规律,代码分析,搜索获取等07.CDN技术与绕过
CDN并不利于我们的安全测试,原因:当第一个访问者进行访问下载后,会在该地区的运营商服务器上留下缓存,以便下次访问。但是网站上的CDN的缓存有时效性,与真实目标还是有所差异,当你网站扫描做请求的时候,其实并不是真实的目标主机,而是扫描的本地上的缓存。CDN会隐藏服务器真实的ip地址,无法对目标网站的操作系统进行渗透,但CDN站点又可以理解为是目标站点的镜像站点(大多数都是静态cdn加速),拥有相同的网站架构,且CDN服务器可与站点服务器进行交互,因此SQL注入,XSS等漏洞的挖掘并不受太大影响。
如何判断CDN服务是否存在
利用多节点技术进行请求返回判断:如果ping的结果只有一个IP,就没有CDN;若是不止一个IP,则有CDN。
http://ping.chinaz.com/
http://ping.aizhan.com/
http://ce.cloud.360.cn/
使用CDN工具查询:
http://www.cdnplanet.com/tools/cdnfinder/常见的CDN绕过技术
1.子域名查询:有些网站为了节约主站做了CDN服务而子站是没有做CDN服务,3种子站部署CDN的情况:
- 一是跟主站相同IP,此时我们知道了子站IP,相当于知道了主站IP;
- 二是跟主站IP不同,但是网段相同,此时可以扫描相同网段是否存活其他主机,大概率就是主站IP。比如192.168.1.100是子站IP,那么就扫描1-254网段判断;
- 三是子站IP和主站IP完全没有关系,此种情况我们无法判断,暂不考虑。
2.邮件服务查询:邮箱大部分都是内部人在访问,且访问的量也不是很大,一般不做CDN。且邮件服务器是对方发邮件给你,它的真实IP地址会泄露,根据对方邮件服务器给我们发送的邮件可以判定对方邮件服务器的地址。
3.国外地址请求:有些网站为了节约成本,它会只考虑它的客户群体的地区来做一个CDN节点的部署,而不会布置到国外去,通过国外地址去请求国内的目标,很容易找到真实IP地址。
4.遗留文件:一些站点在搭建之初,会用一些文件测试站点,例如“phpinfo()”文件,此类文件里就有可能包含了真实的IP地址。可以利用Google搜索引擎搜索关键字“site:xxx.com inurl:phpinfo.php”,搜索站点是否有遗留文件。
5.扫描全网:借助一些工具、软件或者平台,把全世界的网络对你的网站进行访问,判断一下响应IP,通过IP地址的收集整理,把节点访问的IP地址全部收集下来,去分析哪一个可能是真实IP地址。因为不可能每个地区都有CDN节点,所有真实IP一定在收集的里面
6.黑暗引擎搜索特定文件:fofa、shodan、zoomeye、censys、谛听等,会有搜索特定关键词,更加的实时,可以搜索指定文件;这里的特定文件,如:站点的icon文件,也就是网站的图标,一般查看网页源代码可以找到,格式大致“http://www.xx.com/favicon.ico”。在shodan搜索网站icon图标的语法为:http.favicon.hash:hash值,hash是一个未知的随机数,我们可以通过shodan语法来查看一个已经被shodan收录的网站的hash值,来进一步获取到所有带有某icon的网站。
7.DNS历史记录,以量打量
通过查询网站相关的DNS记录,以前这个网站没使用CDN服务,会遗留一些服务,找到没有设置CDN时的历史记录,找到IP地址,有可能就是真实IP地址。
“以量打量”就是常说的ddos攻击或者说是流量耗尽攻击,在网上开CDN的时候,都会分地区流量,就比如这个节点有100M流量,当这流量用完后,用户再访问就会访问网站真实的ip地址。
有些网站可能一开始没有部署CDN,是后来才部署的CDN,那么在dns历史记录里就有可能存在解析为真实IP的记录。
工具:
子域名在线查询:https://chaziyu.com/
全球ping扫工具:全球 CDN 服务商查询_专业精准的IP库服务商_IPIP
DNS查询:域名 DNS 查询 - 锤子在线工具、http://www.17ce.com/
黑暗搜索引擎:Shodan Search Engine、https://www.zoomeye.org、https://fofa.info
第三方接口查询真实ip(也有误报):微步在线 、get-site-ip
全网扫描工具:fackcdn、w8fuckcdn、zmap ,结果需要自己判断,有误报率绕过CDN,使用真实ip访问网站
找到CND真实IP地址后,更改本地HOSTS解析指向文件


此时再次访问网站,便是使用真实IP访问网站。
08.信息收集之架构、搭建、WAF
思路:
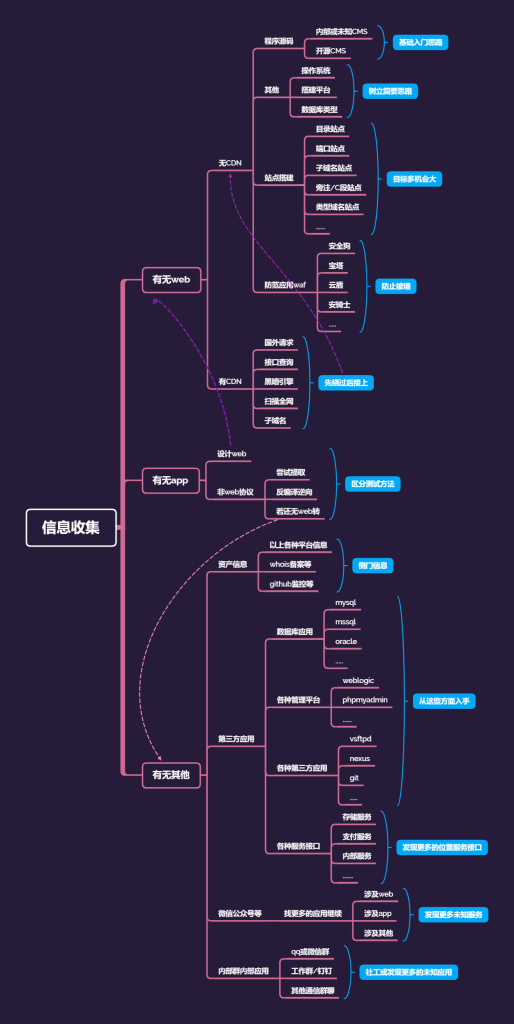
站点搭建分析
1.搭建习惯-目录型站点
简单的理解就是主站上面存在其他的cms程序
例如:
D:\Microsoft\AndroidNDK64\android-ndk-r16b\build\core\toolchains\aarch64-linux-android-4.9和
D:\Microsoft\AndroidNDK64\android-ndk-r16b\build\core\toolchains\mips64el-linux-android-clang
这两者只是目录路径不同;但是两个网站使用的是两套程序,一旦有一个站点出现漏洞,就同时可以攻击另一个站点,就相当于有了两套漏洞两个方案。我们可以通过目录扫描来获取相关信息。
2.搭建习惯-端口类站点
一个服务器(网址)的不同端口,对应了不同的网站(站点)。这种情况只要搞定一个基本就可以渗透。例如web.0516jz.com(默认访问80端口)和web.0516jz.com:8080不是同一个站点。8080端口出现漏洞,80端口也会受到影响。
3.搭建习惯-子域名站点
通过子域名将两个网站分开
可能两者是共用一个ip,也可能不是,现在的主流网站都是采用的这种模式,且子域名和网站之间很有可能是不在同一台的服务器上面。可以ping测试两个网站服务器ip
4.搭建习惯-类似域名站点
有些公司由于业务的发展将原来的域名弃用,选择了其他的域名。但是我们访问他的旧的域名还是能够访问,有的是二级域名的更换而有的是顶级域名的更换。可以通过他的旧的域名找到一些突破口。
如:遇到一个网站,还可以爆破相关域名后缀,比如.com、.cn、.edu.cn等;或者爆破中间域名 如www.xiaoyang.com;www.xiaoyang1.com;www.xiaoyang4.com.....
5.搭建习惯-旁注,c段站点
旁注:同服务器不同站点,但是你要攻击的是A网站由于各种原因不能成功。就通过测试B网站进入服务器然后再攻击A网站最终实现目的。
C段:同网段不同服务器不同站点,通过扫描发现与你渗透测试的是同一个网段最终拿下服务器,然后通过内网渗透的方式拿下目标服务器
旁注查询在线工具:https://www.webscan.cc/
6.搭建习惯-搭建软件特征站点
有的网站是借助于第三方的集成搭建工具实现。例如:PHPstudy、宝塔、wmap、lnmap等环境。
这样的集成环境搭建的危害有 默认账户密码、泄露了详细的版本信息(可以通过版本找到相关漏洞)等。
如:phpstudy搭建了之后在默认的站点安装了phpmyadmin有的网站没有做安全性直接可以通过用户名:root密码:root 登录进入
可以尝试收集一些各类软件搭建网站的特征信息,如nginx搭建的网站 抓包server字段值为nginx
(用中间件搭建,在网站源代码中显示的服务器信息比较少,用搭建平台,显示的服务器信息比较多。)
shodan可以搜索这些特征:https://www.shodan.io/
还可以搜waf:字段为x-powered-waf:waf-WAF防护分析
1.什么是wAF应用?
Web应用防护系统(称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称:WAF)。Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品。
2.如何快速识别WAF
(1)工具wafwoof:Linux上的kali自带,直接就可以使用
项目地址:https://codeload.github.com/EnableSecurity/wafw00f/zip/refs/heads/master
命令: wafw00f 域名/IP
缺点:判断的不是特别的准确存在误报或识别不出的情况
(2)在有些网站的请求信息当中留下了waf的相关信息
F12查看网站标头信息中的X-Powered-By字段中可能会有
(3)使用nmap指纹检测
命令:nmap --script==http-waf-fingerprintnmap --script=http-waf-detec
(4)identYwaf识别
参考地址:https://github.com/stamparm/identywaf
与wafwoof相比运行速度慢,比较稳定推荐还是使用这一款工具。
(5)sqlmap识别
命令:sqlmap.py -u “http://www.xxx.com” --batch
3.识别WAF的意义?
对于一个网站要是使用了waf而渗透人员没有识别直接使用工具进行扫描有可能会导致waf将你的ip地址拉入黑名单而不能访问。而识别waf在于有针对性行的绕过各个厂商的waf可能存在着不同的绕过思路。09.信息收集之APP和其他资产
若WEB无法取得进展或无WEB的情况下,我们需要借助app或其他资产进行信息收集,从而开展后续渗透
APP提取及抓包及后续反编译
(1)利用反编译工具提取URL信息
工具:漏了个大洞:【APK反编译】漏了个大洞获取资源文件+APK文件的获取、反编译使用方法、
(2)利用burp历史抓包获取更多URL
在模拟器中安装CA证书。调整代理监听地址端口。从“HTTP history”信息查看数据包
某IP无WEB框架下的第三方测试
思路:端口乱扫、接口乱扫、接口部分乱扫
(1)nmap扫描–相对全面但时间较慢
详情见工具手册或上网查阅Nmap扫描手册
(2)黑暗引擎扫描(shodan、ZoomEye、fofa)
强大的引擎,开放的端口、端口可能对应的服务都能检测出来,三个都试试
也可以写个脚本同时搜索并导出结果
(3)资产信息、旁注、类似域名、子域名、DNS查询等进行搜索和查端口。
相关工具:微步在线、站长IP查询工具、DNS查询:kali里的dig命令和nslookup命令 、推荐工具
整理
收集到的信息如CMS、IP地址、域名、子域、数据库等等,均进行记录然后根据相应的版本进行漏洞测试
10.信息收集之资产监控
Github监控
收集整理最新exp或poc、发现相关测试目标的资产
#需要修改监控内容、注册github账号、注册Server酱账号(用于微信推送)
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# coding:UTF-8
import requests
import json
import time
import os
import pandas as pd
time_sleep = 20 #每隔20秒爬取一次
while(True):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
#判断文件是否存在
datas = []
response1=None
response2=None
if os.path.exists("olddata.csv"):
#如果文件存在则每次爬取10个
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()#将提取出来的数据中的nan转化为None
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&per_page=10",
headers=headers)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",
headers=headers)
else:
#不存在爬取全部
datas = []
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&order=desc",headers=headers)
response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)
#print(datas)
params = {
"text":s["name"],
"desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"])
}
print("当前推送为"+str(s)+"\n")
print(params)
requests.get("https://sc.ftqq.com/XXXX.send",params=params,timeout=10)
#time.sleep(1)#以防推送太猛
print("推送完成!")
datas.append(s1)
else:
pass
#print("数据已处在!")
pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None)
time.sleep(time_sleep)常见的子域名收集方法(补充)

域名收集及枚举工具-提莫(teemo)项目地址:https://github.com/bit4woo/teemo
Layer子域名挖掘机
查询子域名和证书:https://crt.sh
IP定位:www.chaipip.com
dns历史解析记录查询:https://dnsdb.io
11.漏洞基本知识
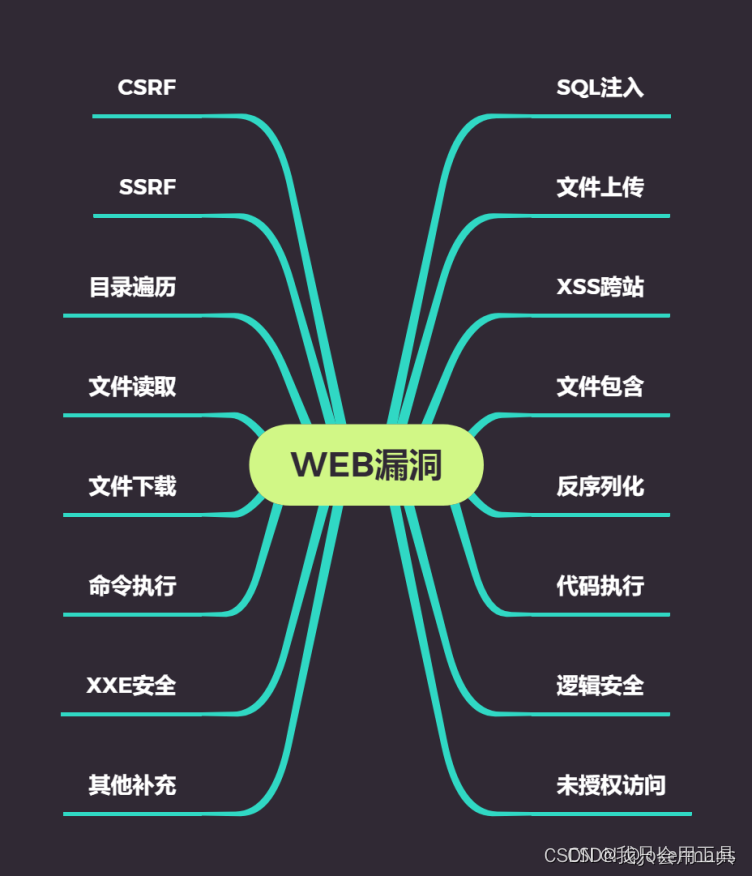
- 高危漏洞:直接影响到网站权限,获得数据或者网站很敏感的东西。如:SQL注入、文件上传、文件包含、代码执行、未授权访问、命令执行
- 中危漏洞:反序列化、逻辑安全
- 低危漏洞:主要是信息泄露,如网站源码泄露这类的,XSS跨站、目录遍历、文件读取
- 漏洞的等级决定漏洞的重要程度,高危漏洞是重点;
pikachu靶场搭建:https://github.com/zhuifengshaonianhanlu/pikachu
12.漏洞发现技巧
操作系统
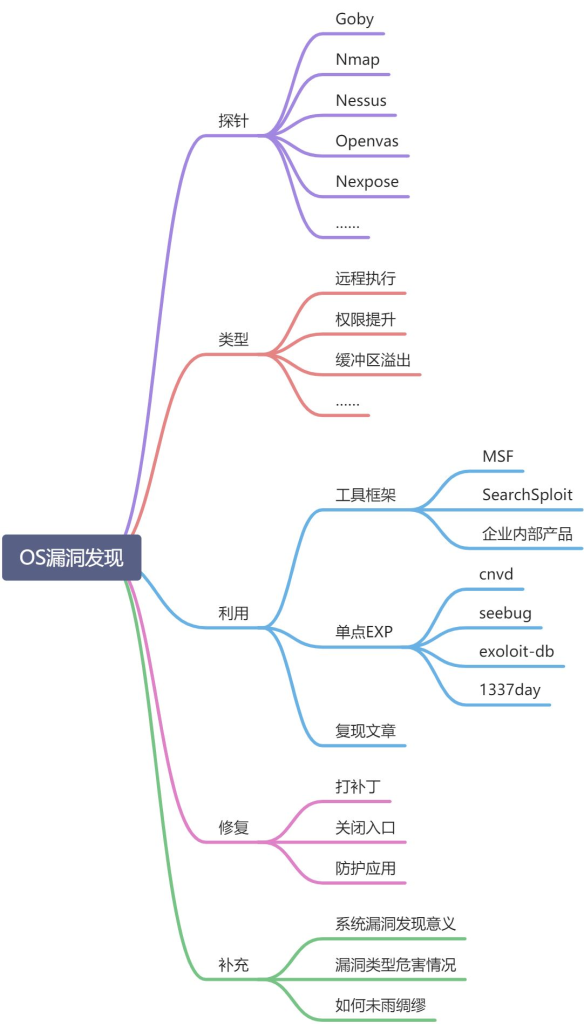
操作系统权限的获取会造成服务器上安全问题。通常使用漏扫工具:Goby,Nmap,Nessus,Openvas,Nexpose等
- nmap 默认nse插件(扫描常规漏洞):
- nmap –script=vuln 192.168.33.1
- nmap 扩展漏洞扫描模块(参考:https://www.cnblogs.com/shwang/p/12623669.html)
- nmap -sV –script=vulscan/vulscan.nse 192.168.199.1
- nmap -sV –script=nmap-vulners 192.168.199.1
- Nessus 安装-使用-插件库加载扫描(推荐此工具)
漏洞类型:权限提升,缓冲器溢出,远程代码执行,未知Bug等
漏洞利用:工具框架集成类,漏洞公布平台库类,复现文章参考等
- 使用工具框架,包括:metasploit、searchsploit、企业单位内部产品等
- kali系统
- 忍者安全渗透系统(NINJUTSU OS):https://blog.csdn.net/qq_35258210/article/details/115457883
- searchsploit使用攻略:https://www.jianshu.com/p/bd8213c53717
- https://www.cnvd.org.cn/
- https://www.seebug.org/
- https://fr.0day.today/
- https://www.exploit-db.com/
- https://packetstormsecurity.com/
漏洞修复:打上漏洞补丁,关闭对应入口点,加上防护软件硬件等
WEB应用
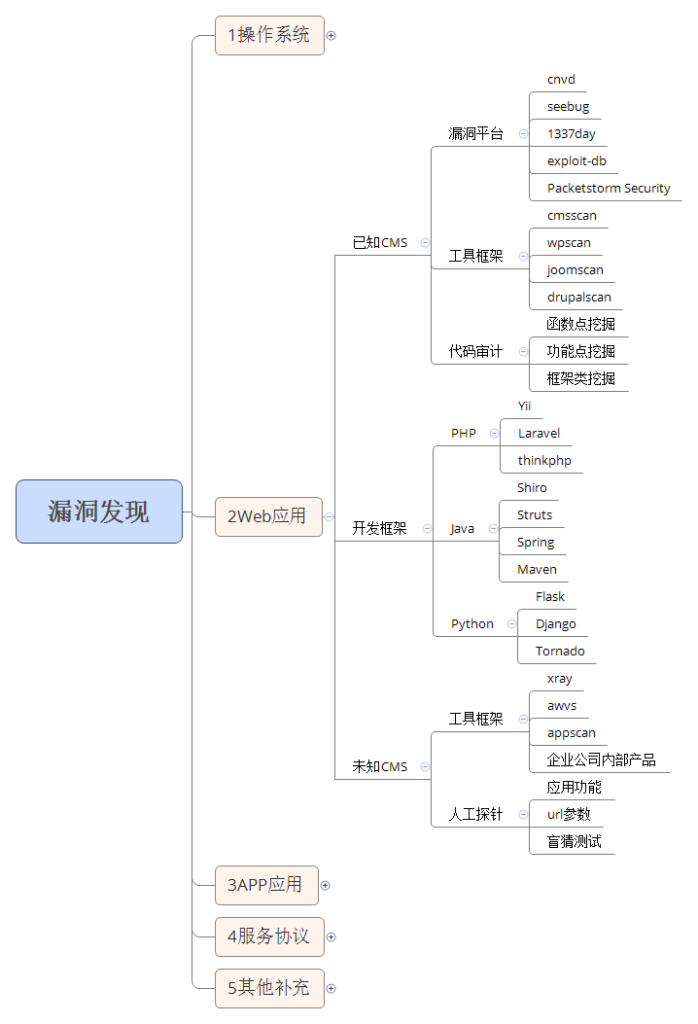
已知CMS
如常见的dedecms,discuz,wordpress等源码结构,这种一般采用非框架类开发,但是也有少部分采用框架类开发,针对此类源码程序的安全检测,我们要利用公开的漏洞进行测试,如不存在可采用白盒代码审计自行挖掘。
搜索漏洞公布平台,寻找单点EXP:
- https://www.cnvd.org.cn/
- https://www.seebug.org/
- https://fr.0day.today/
- https://www.exploit-db.com/
- https://packetstormsecurity.com/
使用工具框架进行有针对性的扫描:
- CMSScan:综合类,一款适用于WordPress、Drupal、Joomla、vBulletin的安全扫描工具
- https://github.com/ajinabraham/CMSScan
- wpscan:WordPress扫描工具
- https://github.com/wpscanteam/wpscan
- kali系统,忍者系统自带
- 使用时需要在官方(https://wpscan.com)申请一个账号(谷歌人机身份验证,必须FQ),登录后得到一个token,使用wpscan时需要带着这个token。
- 用法:wpscan –url <URL> –api-token <YourToken>
- joomscan:Joomla扫描工具
- https://github.com/OWASP/joomscan
- DrupalScan:Drupal扫描工具
- https://github.com/rverton/DrupalScan
- 其他:先识别CMS,然后网上搜索针对该CMS的漏扫工具
代码审计:
- 函数点挖掘
- 功能点挖掘
- 框架类挖掘
开发框架
如常见的thinkphp,spring,flask等开发的源码程序,这种源码程序正常的安全测试思路:先获取对应的开发框架信息(名字,版本),通过公开的框架类安全问题进行测试,如不存在可采用白盒代码审计自行挖掘。
- 常见的PHP开发框架:Yii、Laravel、Thinkphp
- 常见的Java开发框架:Shiro、Struts、Spring、Maven
- 常见的Python开发框架:Flask、Django、Tornado
未知CMS
如常见的企业和个人内部程序源码,也可以是某CMS二次开发的源码结构,针对此类的程序源码测试思路:能识别二次开发就按已知CMS思路进行,不能确定二次开发的话可以采用常规综合类扫描工具或脚本进行探针,也可以采用人工探针(功能点,参数,盲猜),同样在有源码的情况下也可以进行代码审计自行挖掘。
案例1:开发框架类源码渗透测试-咨讯-thinkphp
1.fofa搜索”index/login/login”,寻找测试网站。
2.构造错误的url,查看错误回显,确定网站使用thinkphp框架及其版本。
3.使用专门工具对thinkphp进行漏洞挖掘,比如
- TPScan(jar文件):一键ThinkPHP漏洞检测工具(参考:https://www.jeeinn.com/2021/03/1493/)
- https://github.com/tangxiaofeng7/TPScan
- TPScan(基于Python3):一键ThinkPHP漏洞检测工具:
- https://github.com/Lucifer1993/TPscan
- thinkPHP5.x远程命令执行(getshell)测试工具
- 地址:https://pan.baidu.com/s/17UOif8XD_-V_IMVAHXVlcw 提取码: 31×2
4.找到漏洞后,通过工具框架,漏洞公布平台,复现文章参考等进行漏洞利用。
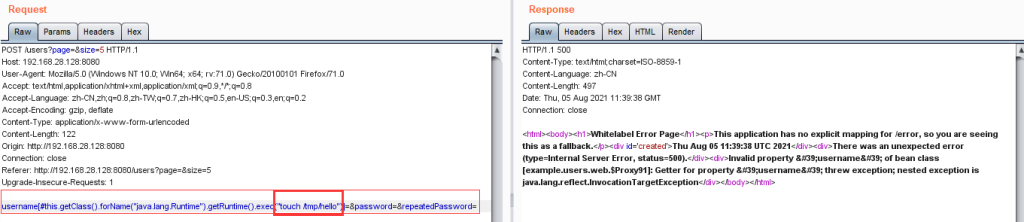
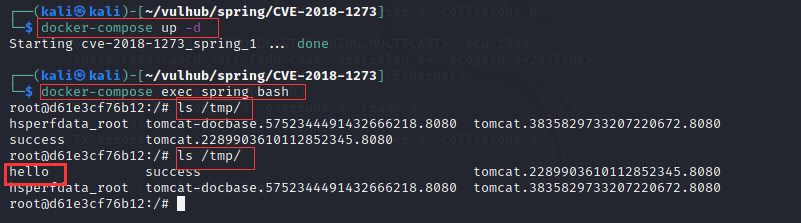
案例2:开发框架类源码渗透测试-咨讯-spring
1.使用Vulhub一键搭建漏洞测试靶场(https://vulhub.org/)
2.在Vulhub网站搜索某类漏洞,按照步骤,启动环境,漏洞复现。如图
案例3:已知CMS非框架类渗透测试-工具脚本-wordpress
1.环境准备:登录墨者学院,启动靶场环境:WordPress插件漏洞分析溯源。
2.CMS识别:进入首页,根据底部版权信息得知,该网站CMS使用的是WordPress。
3.使用wpscan工具扫描。
(1)wpscan官网注册并登录账号,得到token。
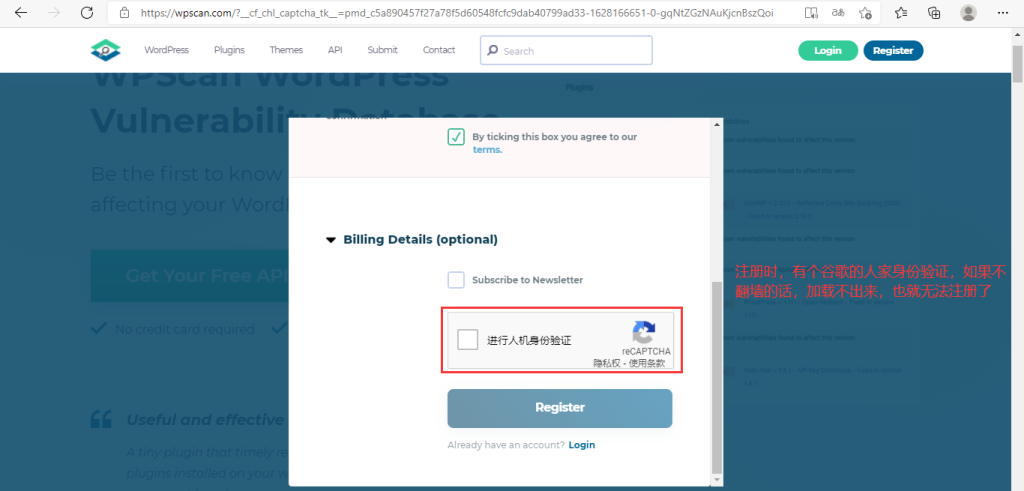
(2)kali下启动扫描:$ wpscan –url http://219.153.49.228:41640/ –api-token <mytoken>
扫描结果如下:
发现一个插件漏洞
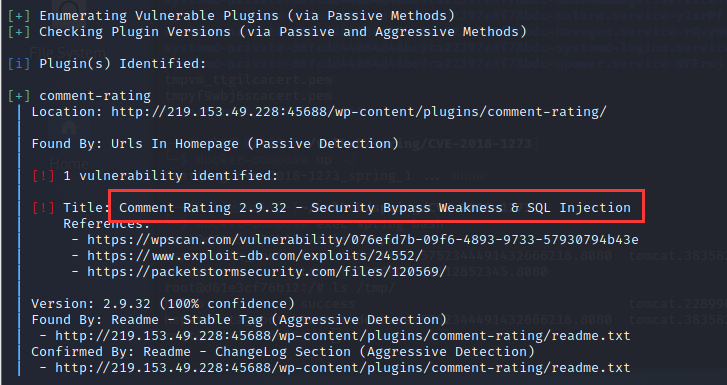
4.去网上找到相关文章、poc等,进行漏洞利用。
案例4:已知CMS非框架类渗透测试-代码审计-qqyewu_php
seay源码审计系统
案例5:未知CMS非框架类渗透测试-人工-wg
外挂类网站
APP应用测试
思路说明:
反编译提取URL或抓包获取url,进行web应用测试,如不存在或走其他协议的情况下,需采用网络接口抓包进行数据获取,转至其他协议安全测试!
案例1:抓包精灵
Android抓包软件,可以安装到手机上,不需要过多设置,即可抓住手机上app产生的http/https包并自动解析,确定是只能看不能操作。
地址:https://github.com/huolizhuminh/NetWorkPacketCapture/releases/tag/1.0.4
案例2:ApkAnalyser
简介:一键提取安卓应用中可能存在的敏感信息。
用法:将所有app放到程序自动创建的apps目录,再运行主程序就好了,不用加参数。
功能:目前提取了APK内所有字符串、所有URLs、所有ip、可能是hash值的字符串、存在的敏感词(如oss.aliyun)、可能是accessKey的值。
地址:https://github.com/TheKingOfDuck/ApkAnalyser//releases/download/1.0/apkAnalyser.zip
案例3:xray与burp联动被动扫描
参考:https://www.cnblogs.com/L0ading/p/12388928.html
案例4:Charles抓包:https://blog.csdn.net/weixin_43612602/article/details/135287720、https://blog.csdn.net/Ambition_ZM/article/details/140181842、https://blog.acesheep.com/p/charles-proxy-usage-guide/
API接口服务
接口服务类安全测试
根据前期信息收集针对目标端口服务类探针后进行的安全测试,主要涉及攻击方法:口令安全,WEB类漏洞,版本漏洞等,其中产生的危害可大可小,属于端口服务/第三方服务类安全测试面。一般在已知应用无思路的情况下选用的安全测试方案。
API接口-webservice RESTful APT
保姆级教程教你玩转API渗透测试 – FreeBuf网络安全行业门户
https://github.com/SmartBear/soapui
根据应用自身的功能方向决定,安全测试目标需有API接口才能进行此类测试,主要涉及的安全问题:自身安全,配合WEB,业务逻辑等,其中产生的危害可大可小,属于应用API接口网络服务测试面,一般也是在存在接口调用的情况下的测试方案。
WSDL(网络服务描述语言,web services description language)是一门基于XML的语言,用于描述web services 以及如何对他们进行访问。
漏洞关键字,配合shodan,fofa,zoomye搜索
inurl: jws?wsdl
inurl: asmx?wsdl
inurl: aspx?wsdl
inurl: ascx?wsdl
inurl: ashx?wsdl
inurl: dll?wsdl
inurl: exe?wsdl
inurl: php?wsdl
inurl: pl?wsdl
inurl: ?wsdl
inurl: asmx?wsdl
filetype: ?wsdl
1.web服务类
tomcat--80/8080/8009
manager弱口令
put上传webshell
HTTP慢速攻击
ajr文件包含漏洞 CVE-2020-1938
Jboss--8080
后台弱口令
console后台部署war包
Java反序列化
远程代码执行
webSphere--9080
后台弱口令
任意文件泄露
Java反序列化
Weblogic--7001/7002
后台弱口令
console后台部署war包
SSRF
测试页面上传webshell
Java反序列化
CVE-2018-2628
CVE-2018-2893
CVE-2017-10271
CVE-2019-2725
CVE-2019-2729
Glassfish--8080/4848
暴力破解
任意文件读取
认证绕过
Jetty--8080
远程共享缓冲区溢出
Apache--80/8080
HTTP慢速攻击
解析漏洞
目录遍历
Apache Solr--8983
远程命令执行
CVE-2017-12629
CVE-2019-0193
IIS--80
put上传webshell
IIS解析漏洞
IIS提权
IIS远程代码执行 CVE-2017-7269
Resin-8080
目录遍历
远程文件读取
Axis2--8080
后台弱口令
Lutos--1352
后台弱口令
信息泄露
跨站脚本攻击
Nginx--80/443
HTTP慢速攻击
解析漏洞2.数据库类
MySQL--3306
弱口令
身份认证漏洞 CVE-2012-2122
拒绝服务攻击
phpmyadmin万能密码or弱口令
UDF/MOF提权
Mssql--1433
弱口令
存储过程提权
Oralce--1521
弱口令
TNS漏洞
Redis--6379
弱口令
未授权访问
PostgreSQL--5432
弱口令
缓冲区溢出 CVE-2014-2669
MongoDB--27001
弱口令
未授权访问
DB2--5000
安全限制绕过进行未授权操作 CVE-2015-1922
SysBase--5000/4100
弱口令
命令注入
Memcache-11211
未授权访问
配置漏洞
ElasticSearch--9200/9300
未授权访问
远程代码执行
文件办理
写入Webshell
3.大数据类
Hadoop--50010
远程命令执行
Zookeeper--2181
未授权访问
4.文件共享
ftp--21
弱口令
匿名访问
上传后们
远程溢出
漏洞攻击
NFS--2049
未授权访问
Samba--137
弱口令
未授权访问
远程代码执行 CVE-2015-0240
LDAP--389
弱口令
注入
未授权访问
5.远程访问
SSH--22
弱口令
28退格漏洞
OpenSSL漏洞
用户名枚举
Telnet--23
弱口令
RDP--3389
弱口令
shift粘滞键后门
缓冲区溢出
MS12-020
CVE-2019-0708
WNC--5901
弱口令
认证口令绕过
拒绝服务攻击 CVE-2015-5239
权限提升 CVE-2013-6886
Pcanywhere-5632
拒绝服务攻击
权限提升
代码执行
X11-6000
未授权访问 CVE-1999-0526
6.邮件服务
SMTP--25/465
弱口令
未授权访问
邮件伪造
POP3-110/995
弱口令
未授权访问
IMAP-143/993
弱口令
任意文件读取
7.其他服务
DNS--53
DNS区域传输
DNS劫持
DNS欺骗
DNS缓存投毒
DNS隧道
DHCP-67/68
DHCP劫持
DHCP欺骗
SNMP--161
弱口令
Rlogin-512/513/514
rlogin登录
Rsync--873
未授权访问
本地权限提升
Zabbix-8069
远程命令执行
RMI--1090/1099
java反序列化
Docker-2375
未授权访问
案例1:其他补充类-基于端口web站点又测试
很多网站域名是一个网站,域名+端口又是一个网站,这样当你渗透测试时,相当于多了一个目标,相应的成功几率也会变高。举例:http://yc.zjgsu.edu.cn和http://yc.zjgsu.edu.cn:8080/
案例2:其他补充类-基于域名web站点又测试
思路1:当我们拿到一个域名时,比如www.jmisd.cn,我们可能首先会去查询它的子域名,这是一个方向,这里我们提供另外一种思路,查询它的相关域名,方法是百度 域名查询,会有很多可以查询域名是否已被注册的网站,比如西部数码网站,我们进入后搜索jmisd,会显示以下3个域名已被注册,然后我们分别查看它们的whois信息、下方版权信息等,查看它们与是否与原网站有相同点,若有,说明这两个网站是同一个公司的,然后就为渗透这个网站找到了一条新路。

思路2:当我们拿到一个域名时,通过查看它的whois信息、下方版权信息等获取到该网站特有的一些关键信息,然后直接百度搜索这些信息,就有可能得到一些与该网站相关的其他域名。
案例3:其他补充类-基于IP配合端口又测试
思路1:假设xx.com对应目录d:/wwwroot/xx/,192.168.33.2对应目录d:/wwwroot/,此时目录d:/wwwroot/下有一个网站备份压缩包xx.zip,那么访问xx.com/xx.zip不能下载,但是访问192.168.33.2/xx.zip可以成功下载。
思路2:给定一个域名,我们先找到对应的ip,然后扫描IP,可以发现开放的端口,我们进行目录扫描或敏感文件扫描时,不仅需要对域名扫描,还要对IP以及IP:端口进行扫描,这样会发现更多的漏洞。
案例4:端口服务类-Tomcat弱口令安全问题
1.使用Vulhub一键搭建漏洞测试靶场(https://vulhub.org/)
docker-compose 启动报错时,试试命令:sudo docker-compose up -d
参考:http://wxnacy.com/2019/01/23/docker-compose-up-error/
2.在Vulhub网站搜索tomcat弱口令漏洞洞,按照步骤,启动环境,漏洞复现。如图
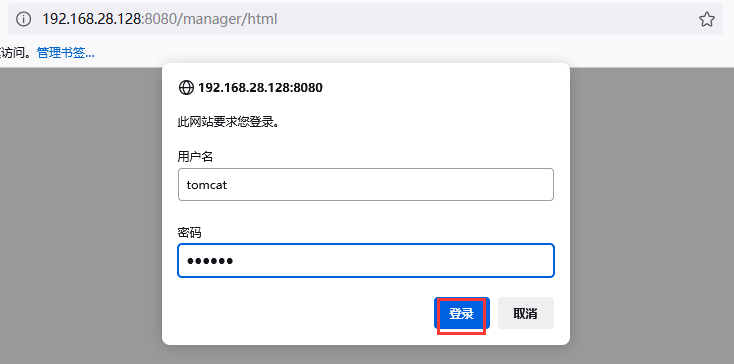
案例5:端口服务类-Glassfish任意文件读取
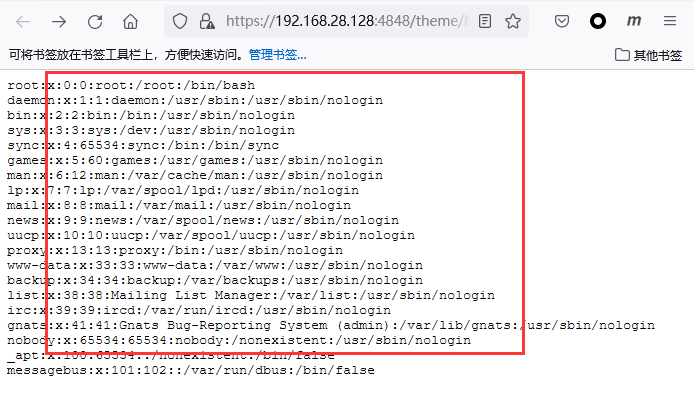
访问https://192.168.28.128:4848/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd,返回服务器文件。
案例6:口令安全脚本工具简要使用-Snetcarcker
Snetcarcker下载:https://github.com/shack2/SNETCracker/releases
SNETCracker超级弱口令检查工具是一款Windows平台的弱口令审计工具,支持批量多线程检查,可快速发现弱密码、弱口令账号,密码支持和用户名结合进行检查,大大提高成功率,支持自定义服务端口和字典。
工具采用C#开发,需要安装.NET Framework 4.0,工具目前支持SSH、RDP、SMB、MySQL、SQLServer、Oracle、FTP、MongoDB、Memcached、PostgreSQL、Telnet、SMTP、SMTP_SSL、POP3、POP3_SSL、IMAP、IMAP_SSL、SVN、VNC、Redis等服务的弱口令检查工作。
工具特点:
- 1.支持多种常见服务的口令破解,支持RDP(3389远程桌面)弱口令检查。
- 2.支持批量导入IP地址或设置IP段,同时进行多个服务的弱口令检查。
- 3.程序自带端口扫描功能,可以不借助第三方端口扫描工具进行检查。
- 4.支持自定义检查的口令,自定义端口。
其他工具:hydra
案例7:API接口类-网络服务类探针利用测试-AWVS
测试WSDL网络服务可使用AWVS扫描
awvs下载:https://www.cnblogs.com/xyongsec/p/12370488.html
小技巧:sqlmap指定在参数id处进行注入:使id=1*


