
shell编程
shell简介
Shell是一种命令行界面,用于用户与操作系统进行交互。也是一种脚本语言,允许用户编写程序自动执行一系列命令。Linux系统中常见的Shell类型包括bash、sh、dash等,其中bash是最常用的Shell之一。
创建并执行shell脚本
#! /bin/bash,#! /bin/dash,#! /bin/sh 这三个开头都是shell执行时的格式,其区别在于:
- #! /bin/bash:指定 Bash解释器执行脚本,且必须有可执行权限,还可以支持数组正则表达式匹配等,具有拓展特性
- #! /bin/dash:指定 Dash解释器,不支持 Bash 的扩展特性(如数组、
[[条件判断等),否则会报错 - #! /bin/sh :指定使用系统默认的 SHell
开始创建第一个shell脚本并开始编写
(1)在终端上通过vim编辑器新建shell脚本shell.sh
使用指令:vim shell.sh 内容如下:
#!/bin/bash
echo "hello world!"
(2)查看shell.sh的权限,假设没有可执行权限
使用指令:ls -l shell.sh
如果出现权限不足的情况时,只会出现rw 可读权限,而没有x-执行权限
(3)为shell.sh添加可执行权限:
chmod u+x shell.sh
注意:chmod a+x 和 chmod u+x 都是用于修改文件或目录的权限,但它们的作用对象不同。
1、chmod a+x 表示为文件或目录设置可执行权限,同时适用于所有用户
2、chmod u+x 表示为文件或目录设置可执行权限,仅适用于文件所有者
(4)执行文件:
sh shell.sh 或者 ./shell.sh
即执行shell的命令有两种:
1、sh + 脚本:无需赋予执行权限,直接执行即可
2、输入脚本的绝对路径或者相对路径:需要先赋予脚本执行权限 x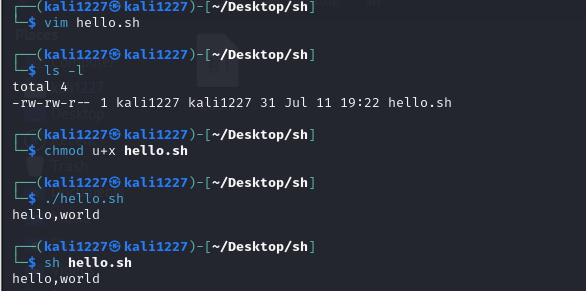
shell变量
系统变量和自定义变量
1、系统变量:顾名思义就是系统已经设置好的变量
诸如 $HOME、$PWD、$USER、$SHELL 等都是系统变量。可以用env/printenv 配合 echo 查看系统变量
env | head -n 4
# 或 printenv | head -n 4
(head 命令用来截取前 4 行输出)
echo $SHELL / echo $PWD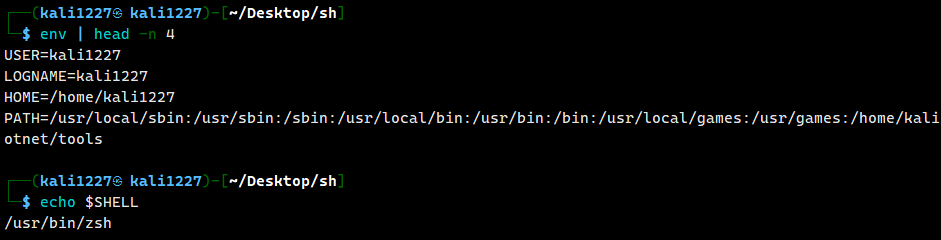
2、自定义变量:我们常用较多的是自定义变量,其基本语法如下:
定义变量:变量名称=值;
撤销变量:unset 变量名;
定义静态变量:readonly 变量名称=值(静态变量不能撤销);
输出变量:$变量。举个例:
#!/bin/bash
#定义变量
A=100
echo "A=$A"
echo "A=${A}"
unset A
echo "A=$A"
readonly B=50
echo "B=$B"
echo "B=${B}"
unset B
echo "B=$B"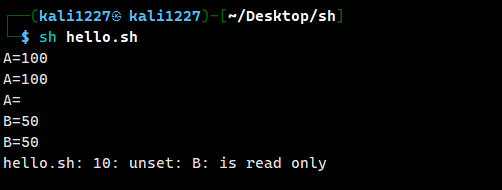
自定义变量的引号问题
#!/bin/bash
name="xiaoyang" #注意:变量赋值时等号两边不能有空格
echo $name #简单的变量声明
echo my name is $name
echo "my name is $name" #加双引号
echo 'my name is $name' #加单引号为什么变量赋值时等号两边不能有空格(这里注意此后文章涉及空格均为英文空格)
如果你写成 name = "xiaoyang",Bash 会按以下方式解析:
- 命令名:
name(被视为一个命令)。 - 参数:
=和"xiaoyang"(被视为该命令的两个参数)。
总结:
- 不加引号或者加双引号都可以输出变量
- 加单引号会把变量当字符串输出出来,即(需要变量解析时用双引号:
echo "Value is $value"。 禁止变量解析时用单引号:echo 'Literal $value')
自定义变量花括号问题
$A:这是最基本的变量引用方式,会直接将变量的值替换到命令中。${A}:变量的扩展语法,变量名被花括号括起来,能精确界定变量名的边界,避免和周围文本混淆。
例如:
A=100
echo "A1=${A}1" # 输出:A1=1001(正确解析)
echo "A1=$A1" # 输出:A1=(错误!Bash会尝试查找变量A1,而这个变量并未定义)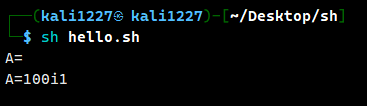
变量的基本规则
- 变量名称可由字母、数字和下划线组成,但不能以数字开头;
- 变量赋值时等号的两侧不能有空格;
- 变量名称一般为大写。
将命令的返回结果赋值给变量是,采取以下写法:
A=`date` #表示运行反引号` `中的命令,并把结果返回给A; date命令会返回日期信息
A=$(date) #这里的$()相当于反引号``的作用。A=`date`
echo $A
B=$(date)
echo $B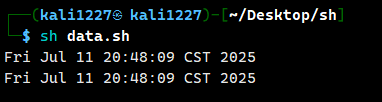
环境变量
打开环境变量:env命令或者printenv
配置环境变量:
| 文件 | 作用范围 | 加载时机 | 环境变量类型 |
|---|---|---|---|
~/.bashrc | 当前用户 | 每次打开新终端时加载 | 用户自定义配置 |
~/.bash_profile | 当前用户 | 登录时加载(仅对登录 shell 有效) | 设置 PATH 等基础变量 |
/etc/environment | 所有用户 | 系统启动时加载 | 系统级环境变量 |
/etc/bash.bashrc | 所有用户 | 每次打开新终端时加载 | 全局 bash shell 配置 |
/etc/profile | 所有用户 | 登录时加载 | 全局环境变量 |
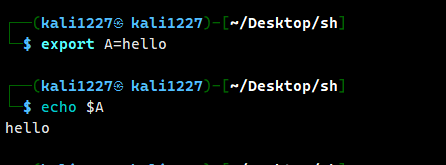
export: 一个用于设置环境变量的关键字,可以直接在终端设置,使得设置的变量可以在当前 shell 以及由该 shell 启动的子进程中生效。
PATH: 一个非常重要的环境变量,它定义了系统在哪些目录下去寻找可执行程序。当你在命令行输入命令(如ls、cat等)时,系统会根据PATH环境变量所指定目录顺序去查找对应的可执行文件,找到后就执行它。
PATH=/root:$PATH: 这是在重新定义PATH的值。它将/root目录添加到了原有的PATH变量值的最前面(假如原有的PATH值存储在变量PATH中,这里通过:PATH的形式保留了原来的值并添加了新的部分)。这样做的结果是,当系统查找可执行程序时,会先在/root目录下查找,然后再按原来PATH指定的其他目录顺序查找
位置参数变量
当执行一个 Shell 脚本时,如果希望获取到命令行各个位置的参数信息,就需要使用到位置参数变量。基本语法:
$n //n为数字,$0代表命令本身,$1-9代表第1到第9个参数,10以上的参数需要用大括号包含如${10}
$* //代表命令行中的所有参数,$* 将所有参数看成一个整体
$@ //单个变量也可以代表命令行中的所有参数,不过 $@ 把每个参数区分对待
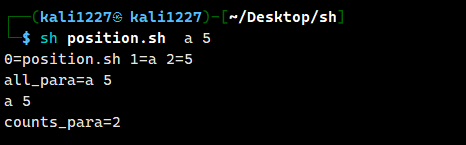
$# //代表命令行中所有参数的个数如:编写一个 Shell 脚本 position.sh,在脚本中获取到命令行中的各个参数信息。可以向脚本程序传递一个或多个参数,脚本出的$1,里面的数字是可以依次递增的,比如$1,$2,$3等等,其中的$0(比较特殊表示文件名称)
#!/bin/bashecho "0 = $0 1 = $1 2 = $2"echo "all_para = $*"echo "$@"echo "counts_para= $#"
预定义变量
预定义变量就是 Shell 的设计者事先定义好的变量,可以直接在 Shell 脚本中使用。语法如下:
- $$ //获取当前进程的进程号码(PID)
- $! //获取后台运行的最后一个进程的进程号
- $? //获取最后一次执行命令的执行结果,若该变量值为0表明上一个命令正确执行,若非 0 表示上一个命令没有正确执行
永久变量
上文提及的export只是设置了临时变量,那么我们只有把它写入到配置文件当中才能永久生效。可以根据生效范围选择写入的配置文件:
当前用户生效(推荐):~/.bashrc 或 ~/.bash_profile;
所有用户生效(需管理员权限):/etc/bash.bashrc 或 /etc/profile。
# 编辑当前用户的配置文件
vim ~/.bashrc
# 在文件末尾添加以下内容(示例)
export MY_VAR="this is my var"
export PATH="$PATH:/新的路径" # 若需添加PATH路径
export PATH=/root:PATH #是系统环境变量路径永久变成 先从root目录寻找,在从原PATH路径寻找
source ~/.bashrc # 针对当前用户配置使配置生效,或输入这个命令 . ~/.bashrc
echo $MY_VAR # 验证是否成功:若输出“this is my var”,则说明已永久生效字符串相关的操作
计算某一个字符串的长度
str="hello world"
echo ${#str}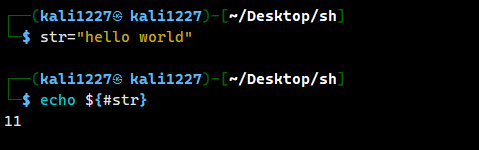
我们想表示str的前7个字符 “hello w”,可用冒号进行截断
echo ${str:0:7}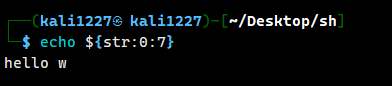
运算符
在 Shell 编程中有各种运算操作,语法格式为
- $((运算式)) //推荐使用
- $[运算式] //(该方式在较新的 bash 版本中已被弃用)如sh就已经不支持该语法了
- expr m + n //若想将 expr 计算出的值赋给某个变量,则使用 “ 符号(注意空格)
expr命令要求 运算符和操作数必须用空格分隔。且遇到乘法的时候要对*进行转义(避免被 Shell 解释为通配符),且expr 不支持两目以外的运算 - * //乘运算符,在shell环境下直接运行时,要将*进行转义,负责会被误认为是通配符。即 \*
- / //除运算符
- % //取余运算符
运算可以在bash脚本中运行,也可以在shell环境下直接运行:
1、在脚本中执行:
#!/bin/bash
# 方式1:使用 $((...)) 进行算术运算
result1=$(((2 +3)*4))
echo "res1=$result1"
# 方式2:使用 $[...] 进行算术运算,sh不支持该语法
result2=$[(2+3)*4]
echo "res2=$result2"
# 方式3:使用 expr 命令进行算术运算
result3=$(expr 2 + 3)
result4=$(expr $result3 \* 4)
echo "expr res4=$result4" #注意这里的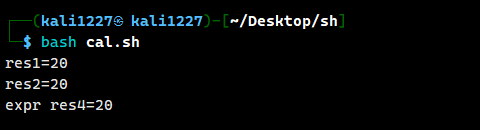
2、在shell中直接运行
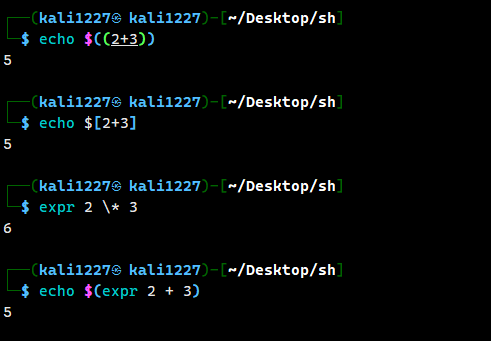
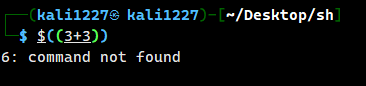
可以看到当我们输入命令格式不对的时候,也会打印出相应的结果,这里的处理过程是shell环境先将 $[3+3] 进行计算得到结果 6 ,然后将 6 当作命令执行,但系统中不存在 6 的命令,于是就报错 6: command not found ,这为安全提供了思路,若算术运算的表达式中包含 未过滤的外部输入(如用户可控的变量),可能被恶意构造为 命令注入攻击。例如:假设脚本接收用户输入作为运算参数,但未做过滤:
# 接收用户输入(不可信)
read user_input
# 直接代入算术扩展
result=$((user_input))
echo "结果:$result"如果用户输入的是 10; rm -rf /(利用分号分隔命令),在某些 Shell 解析逻辑中,可能会先执行 10 的运算,再执行 rm -rf /(删除系统文件),导致严重后果。expr也是同样的道理

shell脚本与用户交互
这里以read读取控制台输入为例展开叙述:
交互
当进行 Shell 编程时,有时也需要跟控制台进行交互,如用户动态的输入一些数据,这时就需要用到 read
基本语法如下:
read (选项)+(选项内容) (参数)
-p 指定读取值时的提示符
-t 指定读取值时的等待时间,如果没有在规定时间内输入,则不再等待
-n 限制字符输入的数量案例1:读取控制台输入的 num 值
#!/bin/bash
read -p "input_num1:" num1
echo "your input num1 is:$num1"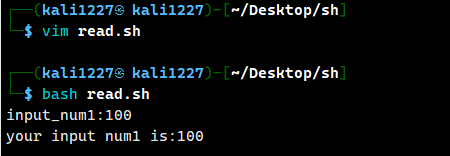
案例 2:读取控制台输入的 num 值,指定在 5 秒内输入;
read -t 5 -p "input_num2:" num2
echo "your input num2 is:$num2"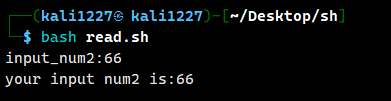
等待输入超过5秒后:

案例3:限制用户输入的字符个数
read -n 3 -t 10 -p "input your name:" name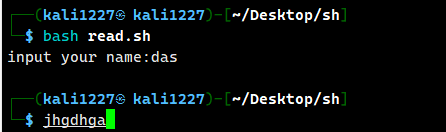
超过输入限制则会自动停止,并打印最前面的三个字符
字符串运算符和逻辑运算符
字符串运算符
案例1:相等的判断
#!/bin/bash
str1="hello"
str2="hello"
if [ "$str1" = "$str2" ]; then # [] 和 = 要注意保留空格,不然会被系统解析成命令而无法识别
echo True
else
echo False
fi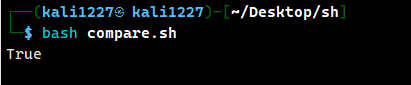
案例2:不相等的判断(同时对str的两个变量采用不同的大小写)
str1="hello"
str2="Hello"
if [ "$str1" = "$str2" ]; then
echo True
else
echo False
fi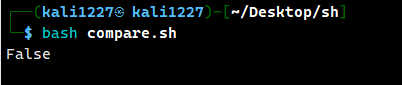
即shell编程中的大小写是有严格区分的
案例3:长度比较。用${#变量名} 来获取变量的长度
str1="hello"
str2="hello" # 比较 str1 和 str2 是否相等
if [ "${#str1}" = "${#str2}" ]; then
echo True
else
echo False
fi逻辑运算符
num1=9
num2=19
if [ "$num1" != "9" ]; then
echo num1不等于9
else
echo num1等于9
fi与运算:&& 或运算:||
num1=9
num2=19
# 使用 && 来连接两个条件,并确保每个操作符周围有空格
if [ "$num1" != "9" ] && [ "$num2" -lt "20" ]; then //这里的-lt 就是小于符号
echo true
else
echo false
fi条件判断
条件判断使用语法 [ condition ](注意 condition 前后有空格),非空会返回 true。可以使用 $? 验证结果,0 为 true,>1 为false。如:
- [ condition ] && echo yes || echo no ,前一个判断满足时会继续执行后面的语句
- [ hspEdu ] 会返回 true
- [ ] 会返回 false
常用的判断语句有:
- 判断两个字符串:= 表示等于
- 判断两个整数: -lt 表示小于,-le 表示小于等于,-eq 表示等于,-gt 表示大于,-ge 表示大于等于,-ne 表示不等于(或者用!=)
- 按照文件权限进行判断:-r //有读的权限,-w //有写的权限,-x //有执行的权限
- 按照文件类型进行判断:-f //文件存在且是常规的文件,-e //文件存在,-d //文件存在且是目录
例如:
num1=78
num2=89
if [ $num1 -eq $num2 ] ; then
echo 相等
else
echo 不相等
fi[]可以换成 test进行测试
num1=78
num2=89
if test $num1 -eq $num2; then
echo 相等
else
echo 不相等
fi1、条件判断部分:
if [ $num1 -eq $num2 ]; 这里使用 if 语句来进行条件判断。在 if 语句的条件表达式中,[] (注意实际使用时 [ 和它里面的内容、] 和它前面的内容都要有空格隔开) 在 shell脚本中用于进行各种测试操作。-eq 是一个比较操作符,用于判断两个值是否相等。所以整个条件表达式就在测试num1 的值和 num2 的值是否相等
2、执行逻辑部分:
then: 如果前面的条件判断结果为真(即 num1 的值和num2 的值相等),那么就会执行 then 后面的代码块。
else: 如果前面的条件判断结果为假(即 num1 的值和num2 的值不相等),就会执行 else 后面的代码块。
流程控制
if 语句
if 语句的基本语法如下,需要注意 [ 条件判断式 ] 中括号与判断式之间必须有空格。
1、单分支结构
#单分支
if [ 条件判断式 ] then
代码
fi2、多分支结构
#多分支
if [ 条件判断式 ] then
代码
elif [ 条件判断式 ] then
代码
...
else
代码
fi案例1:编写一个 shell 程序,如果输入的参数大于等于 60,输出“及格”,小于 60 则输出“不及格”
#!/bin/bash
if [ $1 -ge 60 ] then
echo "pass"
elif [ $1 -le 60 ] then
echo "no pass"
fi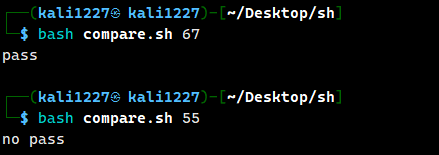
for 循环
For循环有两个基本语法。
1、语法1
for 变量 in 值1 值2 值3...
do
程序
done案例1:打印命令行输入的参数;
#!/bin/bash
#使用$* 把所有输入的参数当成一个整体读取
for i in "$*"
do
echo "num is $i"
done
#使用$@ 读取所有输入的参数,但是区别分开对待
for i in "$@"
do
echo "numagain is $i"
done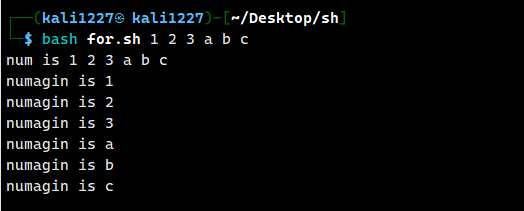
2、语法2
for((初始值;循环控制条件;变量变化))
do
程序
done案例2:输出从 1 加到 100 的值。
#!/bin/bash
sum=0
for(( i=1;i<=100;i++ ))
do
sum=$[$sum+$i]
done
echo "SUM=$sum"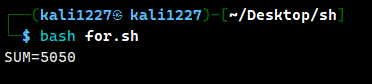
while 循环
基本语法:
while [ 条件判断式 ]
do
程序
done案例:命令行输入一个参数 n,计算 1+2+..+n 的值;
#/bin/bash
sum=0
i=0
while [ $i -le $1 ] #只要第i个数小于我们输入的第一个参数,就执行循环
do
sum=$(($sum+$i))
i=$(($i+1)) #i自增
done
echo "SUM=$sum"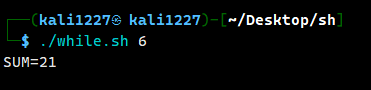
case 语句
基本语法如下,其中 * 代表都不是以上的值
case $变量名 in
"值1")
程序1 //如果变量的值等于1,则执行程序1
;;
"值2")
程序2 //如果变量的值等于2,则执行程序2
;;
......
*)
其他程序 //如果变量的值都不是以上的值,则执行此程序
;;
esac案例:编写程序当命令行参数为 1 时输出“周一”,是 2 时输出“周二”,其他情况输出“other”。
#!/bin/bash
case $1 in
"1")
echo "monday"
;;
"2")
echo "Tuesday"
;;
*)
echo "other"
;;
esac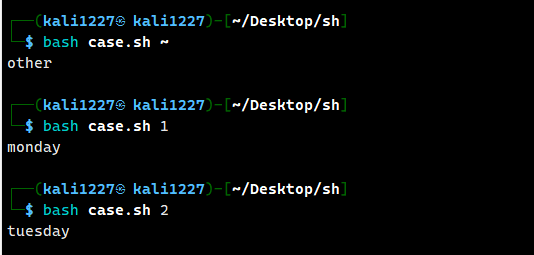
until循环
基本语法如下:
until [ 条件判断式 ]; do
程序 # 当条件为假时执行的代码
done案例:循环打印0-9 十个数
i=0
# 使用 until 循环,当条件为假时执行循环体
until [ $i -ge 10 ]; do
echo "$i"
i=$((i + 1))
done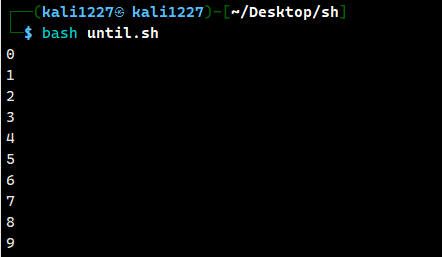
基本函数学习
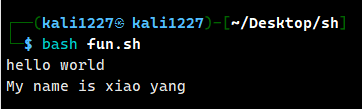
一个函数我们要怎么创建 要怎么引用,起基本语法如下:
DemoFunc() {
echo "hello world"
echo "My name is $1: "
}
DemoFunc "xiao yang"这段代码定义了一个名为 DemoFunc 的函数,函数体 内部仅包含一条打印输出语句。然后通过调用 DemoFunc 来执行这个函数,使得 “hello world” 被输出到控制台。
1、函数定义部分:
- DemoFunc() {: 函数定义开头,声明了函数名为 DemoFunc,紧跟的大括号 { 表示函数体的开始。
- {}内部: 这是函数体内部的语句,当函数被调用时,代码体就会被执行。其中注意的是$1会接受调用函数时传输的第一个参数。
- }: 这是函数体的结束大括号,标志着 DemoFunc 函数定义的完成。
2、函数调用部分:
DemoFunc luoyu: 这单独的一行就是对前面定义好的 DemoFunc函数进行调用。当执行到这一行时,就会跳转到 DemoFunc 函数的定义处,并将参数一并传递到函数内部,随后执行函数体内部的语句。
不同脚本的相互调用
互相调用
1、基本跨脚本调用
. /path/to/script.sh # 方式1:用点号(推荐)
source /path/to/script.sh # 方式2:用source关键字例如:按如下命令进行
- vim 2.sh(新建一个sh脚本文件) :内容为 echo “hello word”
- vim 3.sh(创建另一个 3.sh 脚本文件): 内容为: . ./2.sh 或者使用 source命令:source ./2.sh
- 这里的两个点,第一个点和source命令一样代表跨站执行,第二个表示当前目录下的2.sh
- 执行3.sh ,会发现直接输出hello world ,实现跨脚本调用

重定向
1、输出重定向
例如在shell中输入以下命令
vim 1.txt //在其中写入123456
ls > 1.txt //将ls的命令执行的回显结果写入1.txt中,并覆盖其原有的内容
cat 1.txt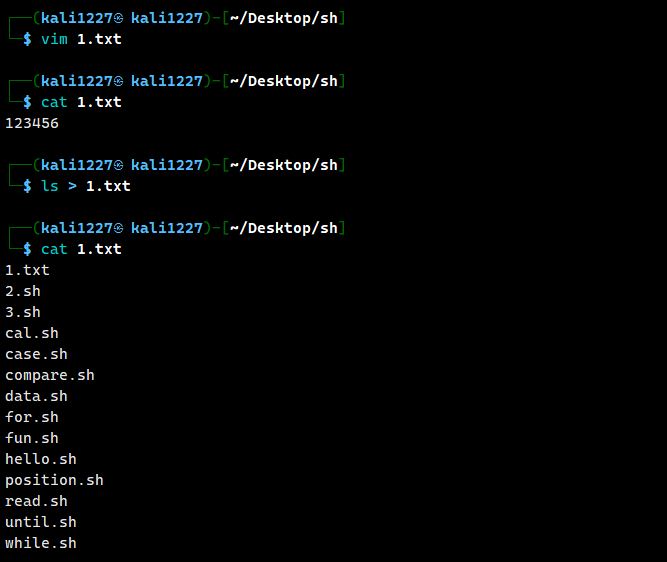
可以看到原有的1.txt内容被ls的回显结果进行了覆盖。
如果要实现不覆盖,可以使用追加写入,例如
ls >> 1.txt //将ls执行的回显结果写入1.txt,但不对原内容进行覆盖
cat 1.txt
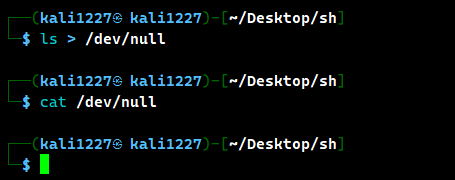
ls > /dev/null //把 ls 命令重定向到垃圾桶回收站,会执行但不会回显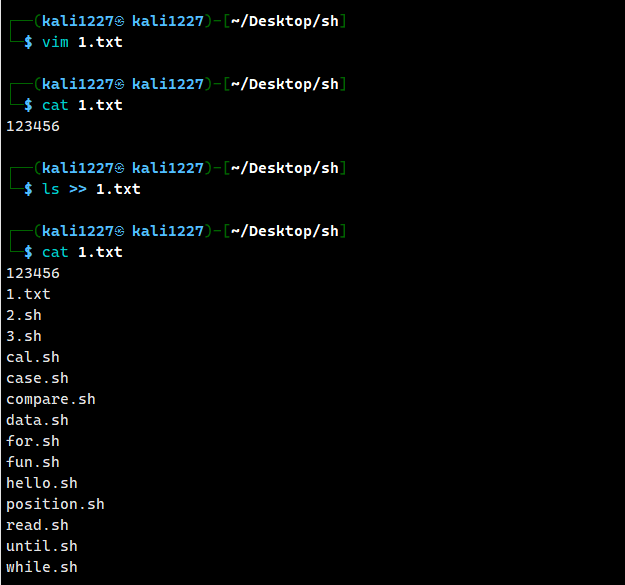
2、输入重定向
示例1:假设你有一个文本条件dirs.txt ,里面写着几个目录名称如:
/home/kali1227/Desktop/1.txt
/home/kali1227/Desktop/2.sh
hello
absg
2222
可以使用ls命令结合输入重定向来查看这些目录下的文件。
终端输入:
grep "hello" < dirs.txt //该命令会在dirs.txt文件中搜索含 "hello" 的行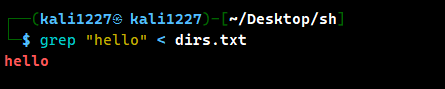
文件描述符
- 0: 标准输入
- 1: 标准输出
- 2: 错误输出
ls > 8.txt 2>9.txt
如果输出正确 就会输出到 8. txt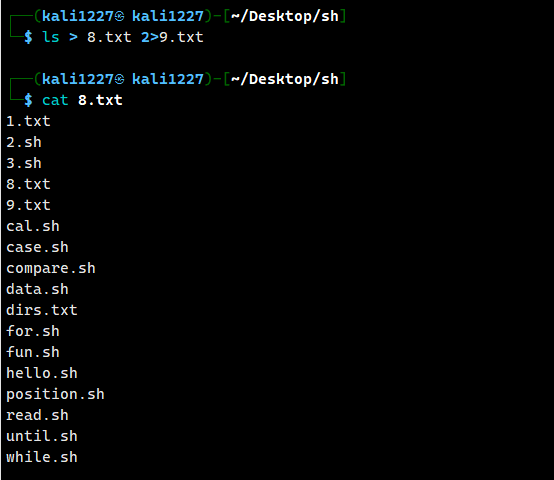
coo > 8.txt 2> 9.txt
如果输出错误 就会输出到 9. txt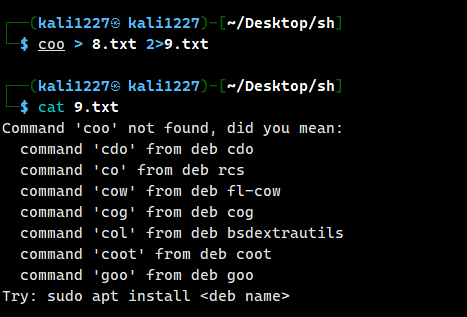
常用命令
文件与目录操作基础
- 创建并进入目录:
mkdir -p project/data && cd project/data(-p确保父目录存在) - 复制并保留属性:
cp -a source_dir destination_dir(-a归档模式,保留权限、时间戳等) - 移动文件到特定目录:
find . -name "*.log" -exec mv -t /backup/ {} +(高效移动大量文件) - 安全删除(先确认):
rm -i *.tmp(-i交互式删除,每个文件都询问) - 强制递归删除目录:
rm -rf old_build/(慎用!-r递归,-f强制) - 查看文件前10行:
head -n 10 access.log - 查看文件后15行:
tail -n 15 error.log - 实时跟踪日志新增内容:
tail -f app.log(-ffollow, 持续输出新增内容) - 查找文件(按名称):
find /home/user -type f -name "config.ini" - 查找目录:
find /var -type d -name "www" - 查找并删除(谨慎!):
find /tmp -name "core.*" -mtime +7 -exec rm {} \;(删除 /tmp 下超过 7 天的 core 文件) - 查找并统计文件数:
find src/ -type f | wc -l - 创建文件软链接:
ln -s /path/to/original /path/to/link - 创建目录软链接:
ln -s /path/to/original_dir /path/to/link_dir - 查看文件类型:
file unknown_file.bin - 比较两个文件差异:
diff file1.txt file2.txt - 比较并排显示差异:
diff -y file1.txt file2.txt - 生成目录树结构:
tree -L 2(显示当前目录树,深度为 2 级) - 更改文件扩展名:
for f in *.txt; do mv -- "$f" "${f%.txt}.csv"; done(批量 .txt 改为 .csv) - 备份文件(带时间戳):
cp important.conf{,.bak_$(date +%Y%m%d)}(生成important.conf.bak_20230713)
文本处理利器 (grep, sed, awk, sort, uniq)
- 搜索文件中包含关键词的行:
grep "ERROR" system.log - 递归搜索目录下文件内容:
grep -r "function_name" src/ - 搜索时忽略大小写:
grep -i "warning" app.log - 显示匹配行及其后2行:
grep -A 2 "Exception" trace.log - 显示匹配行及其前3行:
grep -B 3 "Starting" boot.log - 只显示匹配的文件名:
grep -l "pattern" *.py - 反转匹配(显示不包含的行):
grep -v "DEBUG" verbose.log - 使用扩展正则表达式:
grep -E "error|warning" messages.log - 统计匹配行数:
grep -c "success" report.txt - 简单文本替换:
sed 's/old_text/new_text/' input.txt(输出到屏幕,不修改原文件) - 替换并保存修改(原地编辑):
sed -i 's/foo/bar/g' file.txt(-i直接修改文件,g全局替换) - 删除空白行:
sed '/^$/d' messy.txt - 打印特定行(第5行):
sed -n '5p' data.txt - 打印行范围(10到20行):
sed -n '10,20p' longfile.log - 打印最后一列(默认空格分隔):
awk '{print $NF}' columns.dat - 打印特定列(第2和第4列):
awk '{print $2, $4}' table.csv - 根据条件打印行(第3列大于100):
awk '$3 > 100 {print $0}' numbers.txt - 设置输入字段分隔符(如逗号):
awk -F',' '{print $1}' data.csv - 统计文件行数、单词数、字符数:
wc report.txt - 排序文件内容:
sort unsorted_list.txt
文本处理进阶与数据操作
- 排序(数值顺序):
sort -n numeric_data.txt - 排序(逆序):
sort -r names.txt - 排序并去重:
sort names.txt | uniq - 仅显示重复行:
sort dups.txt | uniq -d - 显示唯一行(去除所有重复):
sort dups.txt | uniq -u - 统计每行出现次数:
sort log_levels.txt | uniq -c - 按次数降序排列:
sort log_levels.txt | uniq -c | sort -nr - 提取文件路径的目录部分:
dirname /var/log/apache/access.log(输出/var/log/apache) - 提取文件路径的文件名部分:
basename /var/log/apache/access.log(输出access.log) - 提取文件名(不含扩展名):
basename /path/to/file.tar.gz .tar.gz(输出file) - 连接多个文件:
cat header.txt body.txt footer.txt > complete.html - 查看压缩文本文件:
zcat access.log.gz | grep "404"(适用于 gzip) - 分页查看长输出:
ls -l /etc | less(按空格下翻页,q退出) - 转换DOS换行符(CRLF)为Unix(LF):
dos2unix script.sh(或sed -i 's/\r$//' script.sh) - 转换Unix换行符为DOS:
unix2dos document.txt(或sed -i 's/$/\r/' document.txt) - 生成随机密码(16字符):
head /dev/urandom | tr -dc A-Za-z0-9 | head -c 16; echo - 计算文件MD5校验和:
md5sum important.iso(Linux) - 计算文件SHA256校验和:
sha256sum critical.zip(Linux) - 按列合并两个文件:
paste file1.txt file2.txt > combined.txt - 转换字符大小写(小写转大写):
echo "Hello" | tr 'a-z' 'A-Z'(输出HELLO)
系统、进程、网络与脚本技巧
- 查看当前用户名:
whoami - 查看系统运行时间与负载:
uptime - 查看磁盘空间使用:
df -h(-h人类可读格式) - 查看目录大小:
du -sh /home/user(-s总大小,-h可读) - 查看内存使用情况:
free -h - 查看最耗CPU的进程:
top -o %CPU(动态,q退出) 或ps aux --sort=-%cpu | head -n 11 - 查看最耗内存的进程:
top -o %MEM或ps aux --sort=-%mem | head -n 11 - 根据进程名查找PID:
pgrep -f "nginx master process" - 根据进程名发送信号(如TERM):
pkill -TERM -f "python myapp.py" - 后台运行命令:
long_running_command & - 将后台作业带到前台:
fg %1(1是作业号, 用jobs查看) - 暂停当前前台作业: 按
Ctrl+Z - 让暂停的作业在后台继续运行:
bg %1 - 使进程不受终端关闭影响:
nohup ./start_server.sh &(输出默认到 nohup.out) - 查看网络连接状态:
netstat -tulnp(查看监听端口及对应进程) - 查看主机路由表:
route -n或ip route show - 测试网络连通性:
ping -c 4 google.com(-c指定次数) - 下载文件:
wget https://example.com/file.tar.gz - 命令行HTTP客户端:
curl -O https://example.com/image.jpg(-O下载文件) - 安全复制文件到远程主机:
scp local_file.txt user@remote_host:/remote/directory/

好